







目录
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的基金仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。
1. 指标介绍
1.1 定义
交叉积比率主要用来评价基金自身的业绩持续性,其主要思路如下:
将评价期分为等长区间,以区间收益率作为评价指标进行排序,将每一区间收益率位于同类基金中位数以上的基金定义为赢家“W”,将每一区间收益率位于同类基金中位数以下的基金定义为输家“L”,统计连续两期对应的组合编码评级,然后依次滚动(例如基金在连续6个周期长度里的评级为“WLLWWL”,对应的组合编码评级为“WL,LL,LW,WW,WL”)统计各组合评级的出现次数,计算出交叉积比率(后续简称为CPR)。
交叉积比率公式为: CPR = (WW*LL)/(WL*LW)
WW表示的对应组合评级出现的次数(WL,LW,LL依次类推)因为可能存在WL或者LW为0的情况,因此当二者出现为0的情况时,将其取值为1。
1.2 使用方法
关于CPR的数值解释如下:
| CPR值所处区间 | 情形 | 结论 |
| [0,1) | WW和LL的数量占绝对劣势 | 不存在业绩持续性 |
| [1,2) | WW和LL的数量相对占优 | 业绩持续性不显著 |
| [2,3) | WW和LL的数量占优 | 具备一定的业绩持续性 |
| >3 | WW和LL的数量占绝对优势 | 业绩持续性显著 |
在计算CPR值时,所选样本的同类基金数量越多,其结果越可靠(基金分类,举例如偏股型,混合型,灵活配置型等);所统计的周期不能低于6个(例如,使用的日度收益率数据不得低于6个连续交易日)。另外,CPR值越高仅能说明过去业绩相对持续性更强(可理解强的持续强,弱的持续弱),并不能代表过去基金业绩更好。
2. 案例演示
2.1 获取数据
本文使用akshare开源api,选择6只指数型ETF为例,时间区间为20221201--20221230,进行后续的计算演示。
首先,使用一个自定义函数获取单只ETF对应的涨跌幅数据,代码如下:
import pandas as pd
import akshare as ak
def get_one_etf_sum_nav_return(fund_code, start_day, end_day):
'''
获取单只ETF场内基金累计净值的涨跌幅
----------
fund_code:str,基金代码,格式如'510500'
start_day:str,开始日期,格式如'2022-12-01'
end_day:str,结束日期,格式如'2022-12-01'
Returns:dataFream,第一列为日期,第二列为涨跌幅
-------
'''
data = ak.fund_etf_fund_info_em(fund_code)
data['date'] = data['净值日期'].apply(lambda x: str(x))
new_data = data.loc[(data['date'] >= start_day) & (data['date'] <= end_day)]
out_data = pd.DataFrame({'date': new_data['date'], fund_code: new_data['日增长率'] / 100})
return out_data
if __name__ == '__main__':
start_day, end_day = '2022-12-01', '2022-12-30'
data = get_one_etf_sum_nav_return('510500', start_day, end_day)对应得到的结果如下:
接下来,根据对基金代码对应的列表进行循环,合并每只ETF的数据,代码如下:
def get_all_data(fund_code_list, start_day, end_day):
'''
获取合并后的基金数据
----------
fund_code_list:list,基金代码列表
start_day:str,开始日期,格式如'2022-12-01'
end_day:str,结束日期,格式如'2022-12-01'
Returns:DataFrame
-------
'''
all_data = pd.DataFrame()
for fund_code in fund_code_list:
one_data = get_one_etf_sum_nav_return(fund_code, start_day, end_day)
if all_data.empty:
all_data = all_data.append(one_data)
else:
all_data = pd.merge(all_data, one_data, how='outer', on='date')
return all_data
if __name__ == '__main__':
start_day, end_day = '2022-12-01', '2022-12-30'
code_list = ['513100', '513330', '510500', '515390', '513500','510050']
all_data = get_all_data(code_list, start_day, end_day)对应得到的结果如下:
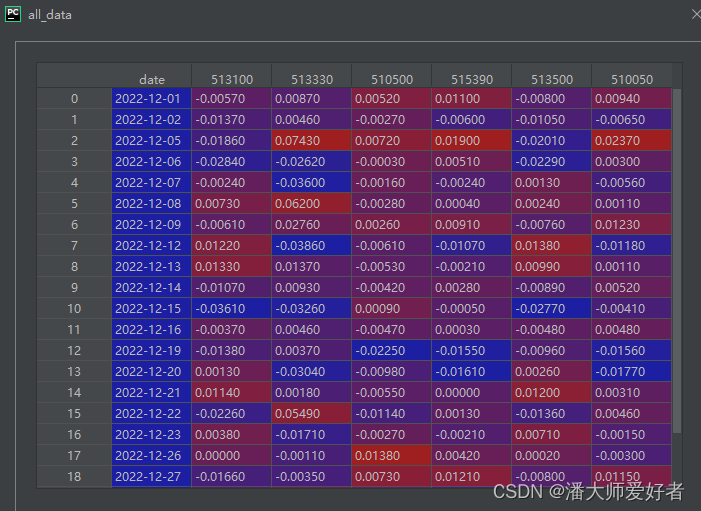
此处得到的all_data本身没有数据缺失,若存在数据缺失的情况,我们应当采取相应的行均值填充或者其他具有逻辑性的填充;对于数据缺失较为严重的情况,应该考虑更换数据对应的频率,例如将日度切换为周度或者月度,以此来保证底层数据的有效性。
2.2 数据转换
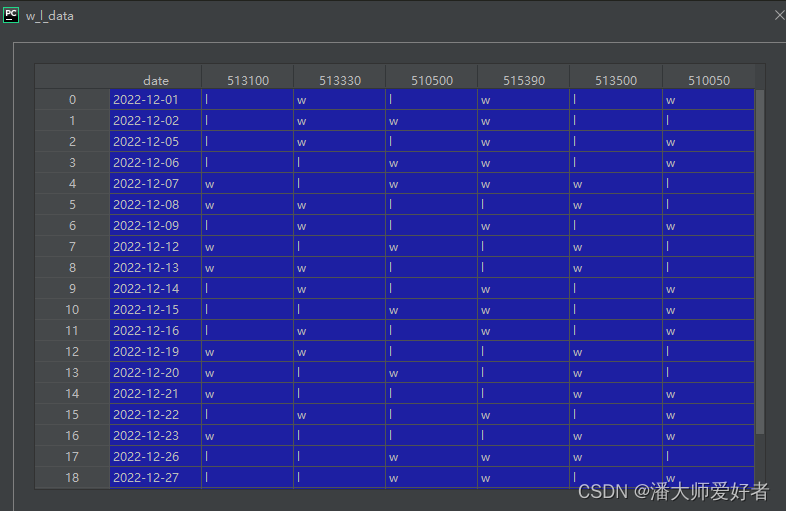
在得到了基础数据all_data的基础上,需要先将对应基金的涨跌幅数转换成w或者l。举例来说,20221201的涨跌幅数据中,515390,513330,510500三只基金的涨跌幅大于中位数(当日6只基金的涨跌幅对应的中位数),因此其对应都是w,其余三只基金对应l。以此类推,将每个周期下的涨跌幅进行转换,代码如下:
def get_w_or_l(in_data):
'''
将基金的涨跌幅数据对应转换成w/l
----------
all_data:DataFrame,所有基金的涨跌幅数据
Returns:DataFrame,转换后的基金w/l数据
-------
'''
copy_data = in_data.copy()
col_list = copy_data.columns[1::]
copy_data['mid'] = copy_data.median(axis=1)
for col_name in col_list:
copy_data['test'] = copy_data[col_name] - copy_data['mid']
in_data[col_name] = copy_data['test'].apply(lambda x: 'w' if x >= 0 else 'l')
return in_data
if __name__ == '__main__':
start_day, end_day = '2022-12-01', '2022-12-30'
code_list = ['513100', '513330', '510500', '515390', '513500', '510050']
all_data = get_all_data(code_list, start_day, end_day)
new_data = all_data.copy()
w_l_data = get_w_or_l(new_data)得到的数据如下:
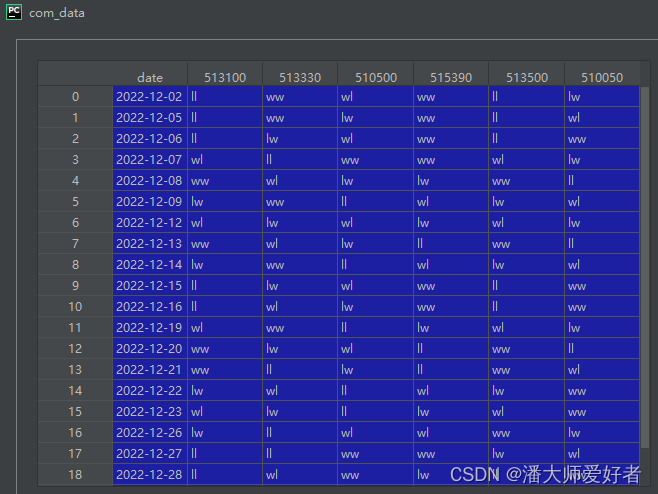
接下来,将w_l_data中每只基金相邻2单元格的w,l进行拼接,得到组合。举例来看,513100在20221201和20221202对应的分别是l,l,因此其在20221202对应的组合编码为ll,在20221201日无组合编码(因为今日设定为起始日)。以此类推,统计每交易日对应的组合编码,代码如下:
def get_com_df(new_w_l):
# 对相邻两个编码进行组合
col_list = new_w_l.columns[1::]
last_df = pd.DataFrame()
for col_name in col_list:
# 循环所有列
one_fund_list = []
for num in range(1, len(new_w_l)):
# 对单个基金的编码进行组合
com_code = new_w_l[col_name].values[num] + new_w_l[col_name].values[num - 1]
one_fund_list.append(com_code)
one_fund_df = pd.DataFrame({'date':new_w_l['date'][1::],
col_name:one_fund_list})
if last_df.empty:
last_df = last_df.append(one_fund_df)
else:
last_df = pd.merge(last_df, one_fund_df, how='outer', on='date')
return last_df
if __name__ == '__main__':
start_day, end_day = '2022-12-01', '2022-12-30'
code_list = ['513100', '513330', '510500', '515390', '513500', '510050']
all_data = get_all_data(code_list, start_day, end_day)
new_data = all_data.copy()
w_l_data = get_w_or_l(new_data)
new_w_l = w_l_data
com_data = get_com_df(new_w_l)得到的结果如下:
2.3 计算CPR值
根据每只基金的组合编码,计算其对应的CPR值,并划分出CPR值所处的区间,代码如下:
def CPR(data_list):
# 计算CPR的值
# data_list:组合编码对应的列表
if len(data_list) < 5:
cpr = 'null'
else:
wl = max(data_list.count('wl'), 1)
lw = max(data_list.count('lw'), 1)
ww = data_list.count('ww')
ll = data_list.count('ll')
cpr = (ww * ll) / (lw * wl)
return cpr
def get_CPR_mean(value):
# 获取CPR值对应的含义
# value:对应CPR的值
if 0 < value < 1:
d_type = '不存在业绩持续性'
elif 1 <= value < 2:
d_type = '业绩持续性不显著'
elif 2 <= value < 3:
d_type = '具备一定的业绩持续性'
elif value > 3:
d_type = '业绩持续性显著'
return d_type
def main(com_data):
col_list = com_data.columns[1::]
main_df = pd.DataFrame()
for col_name in col_list:
one_fund_cpr = CPR(com_data[col_name].tolist())
one_fund_cpr_mean = get_CPR_mean(one_fund_cpr)
one_df = pd.DataFrame({'基金代码': [col_name],
'CPR值': [one_fund_cpr],
'CPR含义': [one_fund_cpr_mean]})
main_df = main_df.append(one_df)
return main_df
if __name__ == '__main__':
start_day, end_day = '2022-12-01', '2022-12-30'
code_list = ['513100', '513330', '510500', '515390', '513500', '510050']
all_data = get_all_data(code_list, start_day, end_day)
new_data = all_data.copy()
w_l_data = get_w_or_l(new_data)
new_w_l = w_l_data.copy()
com_data = get_com_df(new_w_l)
main_df = main(com_data)对应的结果为:
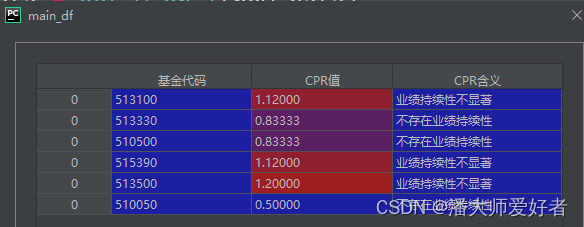
从结果看,所举例基金在对应时间区间内均不具备业绩持续性。当然这里仅仅作为举例,所使用的的基金样本数量太少,周期太短,所得出的结果也是不可靠的。
2.4 完整代码
import pandas as pd
import akshare as ak
def get_one_etf_sum_nav_return(fund_code, start_day, end_day):
'''
获取单只ETF场内基金累计净值的涨跌幅
----------
fund_code:str,基金代码,格式如'510500'
start_day:str,开始日期,格式如'2022-12-01'
end_day:str,结束日期,格式如'2022-12-01'
Returns:DataFrame,第一列为日期,第二列为涨跌幅
-------
'''
data = ak.fund_etf_fund_info_em(fund_code)
data['date'] = data['净值日期'].apply(lambda x: str(x))
new_data = data.loc[(data['date'] >= start_day) & (data['date'] <= end_day)]
out_data = pd.DataFrame({'date': new_data['date'], fund_code: new_data['日增长率'] / 100})
return out_data
def get_all_data(fund_code_list, start_day, end_day):
'''
获取合并后的基金数据
----------
fund_code_list:list,基金代码列表
start_day:str,开始日期,格式如'2022-12-01'
end_day:str,结束日期,格式如'2022-12-01'
Returns:DataFrame
-------
'''
all_data = pd.DataFrame()
for fund_code in fund_code_list:
one_data = get_one_etf_sum_nav_return(fund_code, start_day, end_day)
if all_data.empty:
all_data = all_data.append(one_data)
else:
all_data = pd.merge(all_data, one_data, how='outer', on='date')
return all_data
def get_w_or_l(in_data):
'''
将基金的涨跌幅数据对应转换成w/l
----------
all_data:DataFrame,所有基金的涨跌幅数据
Returns:DataFrame,转换后的基金w/l数据
-------
'''
copy_data = in_data.copy()
col_list = copy_data.columns[1::]
copy_data['mid'] = copy_data.median(axis=1)
for col_name in col_list:
copy_data['test'] = copy_data[col_name] - copy_data['mid']
in_data[col_name] = copy_data['test'].apply(lambda x: 'w' if x >= 0 else 'l')
return in_data
def get_com_df(new_w_l):
# 对相邻两个编码进行组合
col_list = new_w_l.columns[1::]
last_df = pd.DataFrame()
for col_name in col_list:
# 循环所有列
one_fund_list = []
for num in range(1, len(new_w_l)):
# 对单个基金的编码进行组合
com_code = new_w_l[col_name].values[num] + new_w_l[col_name].values[num - 1]
one_fund_list.append(com_code)
one_fund_df = pd.DataFrame({'date': new_w_l['date'][1::],
col_name: one_fund_list})
if last_df.empty:
last_df = last_df.append(one_fund_df)
else:
last_df = pd.merge(last_df, one_fund_df, how='outer', on='date')
return last_df
def CPR(data_list):
# 计算CPR的值
# data_list:组合编码对应的列表
if len(data_list) < 5:
cpr = 'null'
else:
wl = max(data_list.count('wl'), 1)
lw = max(data_list.count('lw'), 1)
ww = data_list.count('ww')
ll = data_list.count('ll')
cpr = (ww * ll) / (lw * wl)
return cpr
def get_CPR_mean(value):
# 获取CPR值对应的含义
# value:对应CPR的值
if 0 < value < 1:
d_type = '不存在业绩持续性'
elif 1 <= value < 2:
d_type = '业绩持续性不显著'
elif 2 <= value < 3:
d_type = '具备一定的业绩持续性'
elif value > 3:
d_type = '业绩持续性显著'
return d_type
def main(com_data):
col_list = com_data.columns[1::]
main_df = pd.DataFrame()
for col_name in col_list:
one_fund_cpr = CPR(com_data[col_name].tolist())
one_fund_cpr_mean = get_CPR_mean(one_fund_cpr)
one_df = pd.DataFrame({'基金代码': [col_name],
'CPR值': [one_fund_cpr],
'CPR含义': [one_fund_cpr_mean]})
main_df = main_df.append(one_df)
return main_df
if __name__ == '__main__':
start_day, end_day = '2022-12-01', '2022-12-30'
code_list = ['513100', '513330', '510500', '515390', '513500', '510050']
all_data = get_all_data(code_list, start_day, end_day)
new_data = all_data.copy()
w_l_data = get_w_or_l(new_data)
new_w_l = w_l_data.copy()
com_data = get_com_df(new_w_l)
main_df = main(com_data)
print(main_df)
上述代码完整阐述了交叉积比率的计算过程,有许多地方为了可视化的举例,代码存在重复或者复杂的情况,读者阅读时请根据所需忽略部分问题。
3. 指标评价
3.1 指标优点
1. 思路新颖,将复杂问题抽象化,便于理解。
2. 计算得到的结果具有较为清晰的评判标准。
3. 在对基金评价的同时,也可以衍生为基金筛选,行情分析的工具。
3.2 指标缺点
1. 数据基于历史,选择不同的数据频率或周期长度得到的结论可能不同。
2. 所需的基金底层数据量较大,数据处理过程相对繁琐。
3. 所选择的基金样本不同,得到的结论可能不同。
本期分享到此结束,有何问题欢迎交流。
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的基金仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。

















 4738
4738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









