






目录
一、期刊概述
Deep Reinforcement Learning for Delay-Oriented IoT Task Scheduling in SAGIN[1]
翻译:SAGIN(空天地一体化网络)中面向延迟的IoT任务调度的深度强化学习
来源:TWC
二、介绍
背景:考虑到物联网设备的低发射功率和短距离通信范围,本文在空天地一体化网络中提出了一种面向延迟的任务调度,以实时处理计算任务。用无人机与物联网设备进行通信并收集其计算任务,然后实时地做出任务调度决策,如何在合适的空天地一体化网络组件(基站,低地球轨道卫星,比如SpaceX和OneWeb)上获得高效调度策略是一个至关重要的问题。
方法:首先将在线调度问题建模为一个能量受限的马尔可夫决策过程( MDP )。然后,考虑到任务到达的动态性,本文提出了一种风险敏感强化学习算法。该算法对每个状态进行风险评估,衡量超过约束的能量消耗,并在学习最优策略的同时,搜索权衡最小化延迟和风险的最优参数。时延最大可降低30 %。
三、方法
系统模型
1、空天地一体化网络建模
空天地一体化网络中只考虑UAV、BS和LEO卫星的计算功能。基站具有较高的计算能力,但其覆盖范围有限。低轨卫星始终可以覆盖该区域,并作为陆地网络的补充,而无人机链路的传播延迟不容忽视。因此,应将任务适当地调度到空天地一体化网络中的不同组件,以减少服务延迟。无人机的位置用lt表示,无人机沿轨迹飞行,每个Epoch(一个时间单位)可以卸载多个计算任务,则只能选择一个目的(即BS或卫星)。
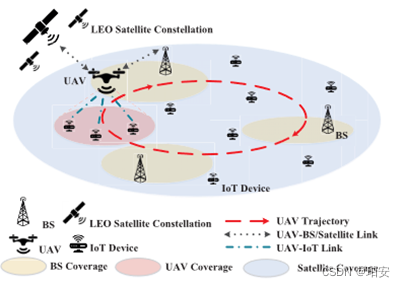
图表 1 网络模型
图表2是一个例子。在Epoch1,采集4个任务,其中1个任务在无人机本地处理,3个任务卸载到BS并移入转发队列。在Epoch2中,由于任务转发未完成,无人机无法将新任务移动到转发队列中。在无人机本地只处理一个任务,转发队列中的所有任务都进行传输。在Epoch3,有两个任务被卸载到卫星上,并移动到转发队列中。在Epoch4中,所有任务只能在无人机本地执行。
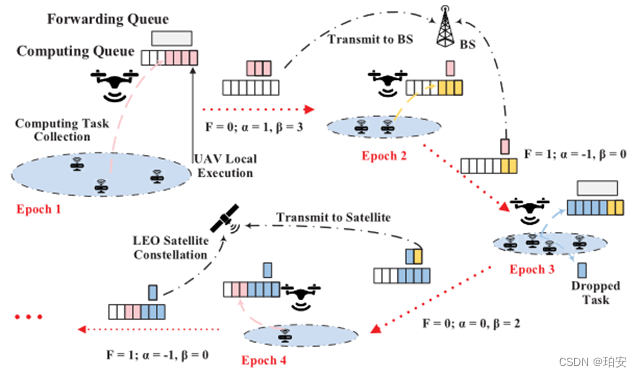
图表 2 一个例子
2、计算模型
(φ,γ)表示一个任务,φ表示计算任务的输入数据大小,γ表示处理一位输入数据需要多少个CPU周期。计算时延如下:
(1)任务卸载: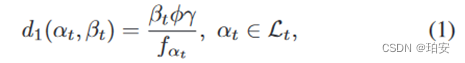 ,其中αt为卸载目标(0为卫星,n为基站), β t表示要传输的任务,f表示计算能力。
,其中αt为卸载目标(0为卫星,n为基站), β t表示要传输的任务,f表示计算能力。
(2)本地时延:本地时延=本地计算时延+排队时延。收集到的任务可能无法在本地处理或者完全卸载到无人机上,假设剩余的任务在UAV的计算队列中等待调度。先对计算队列建模:计算队列中Epoch t的排队任务数为 ,Ht为未完成的任务调度,f为无人机的计算能力,总的来说,就是未完成是任务数减去无人机处理的任务数减去传输的任务数。未完成的任务积压更新为
,Ht为未完成的任务调度,f为无人机的计算能力,总的来说,就是未完成是任务数减去无人机处理的任务数减去传输的任务数。未完成的任务积压更新为![]() ,其中,p为计算队列的最大长度。
,其中,p为计算队列的最大长度。
3、传输模型
无人机有两个通信接口,一个用于LEO卫星,另一个用于基站。接下来,讨论了卸载任务到卫星和基站的传输时延:
(1)无人机—卫星。低轨卫星与地面用户之间的无线通信是通过Ka或Ku频段实现的,其信道条件主要受通信距离和雨衰(雨衰落)的影响。假设气象环境在物联网任务收集过程中保持静止,无人机-卫星链路的信道增益主要由无人机与卫星之间的距离决定。无人机-卫星链路在Epoch t的数据速率为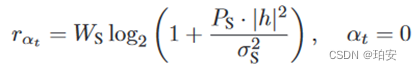 ,其中Ws表示链路的信道带宽,Ps表示链路的发射功率,σ表示噪声功率。卸载任务到卫星的传输时延为
,其中Ws表示链路的信道带宽,Ps表示链路的发射功率,σ表示噪声功率。卸载任务到卫星的传输时延为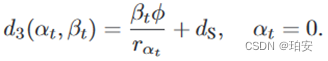
(2)无人机—基站。由于UAV需要保证在UAV飞出BS的覆盖范围之前能够完成所有βt任务的转发过程,因此转发任务的数量βt满足如下约束:
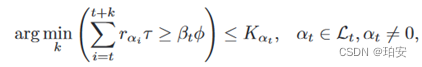
这意味着β t任务的传输时间比无人机在基站覆盖范围内停留的时间更短。无人机—基站链路数据速率为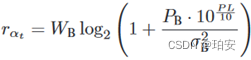 其中,WB表示信道带宽,PB表示发射功率,σ表示背景噪声的功率。卸载任务到BS的传输延迟为:
其中,WB表示信道带宽,PB表示发射功率,σ表示背景噪声的功率。卸载任务到BS的传输延迟为: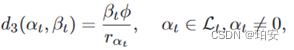
4、能耗模型
一般来说,无人机能耗包括推进能耗、通信相关能耗和计算相关能耗。由于无人机的推进能量主要取决于不同的轨迹和飞机参数,因此可以将其视为一个常数。因此,本文目标是保证能量消耗的剩余部分,即与计算相关的能量和与通信相关的能量不超过无人机的能量容量。用e表示任务传输引起的与通信相关的能量,计算如下:

同时,在无人机上处理计算任务也会消耗能量,这取决于计算任务的计算工作量和无人机的计算能力。用el表示与计算相关的能量,为:![]()
其中ξ表示由芯片结构决定。用Et表示Epoch t的累积能耗: ![]()
目标和约束
本文目标是在满足无人机能耗约束的同时,最小化所有计算任务的长期延迟。所有任务在Epoch t的总延迟可以计算如下:
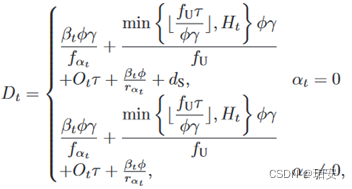
其中同时包括计算时延和传输时延。本文专注于最小化所有任务的时间平均延迟。延迟最小化问题可以表述为:
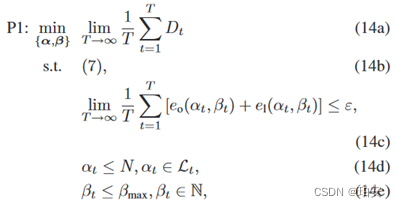
其中( 14a )是最小化所有收集任务在T个Epoch上的时间平均延迟的目标,( 14b )限制了卸载目的和卸载任务的数量。( 14c )限制了无人机的时均能耗,其中ε是无人机的能量容量。( 14d )和( 14e )分别约束任务卸载决策和卸载任务的数量。
P1不好计算,转化为P2形式,也使得期望平均成本最小。P2是一个带约束的MDP ( Constrained MDP,CMDP )问题,是一个典型的带附加约束的MDP问题
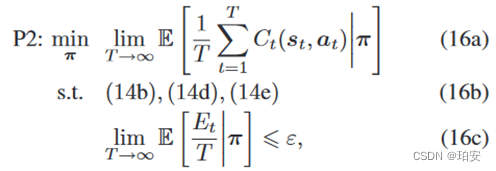
风险敏感强化学习算法
在问题P2中,除了成本最小化的目标外,还需要满足额外的能量容量约束。然而,由于能耗不是成本函数的组成部分,传统的RL方法不能满足问题P2中的约束。因此,本文提出了一种风险敏感的RL算法来处理CMDP问题。具体来说,除了代价函数之外,定义一个额外的风险函数,用来捕捉当前Epoch的无人机能耗是否违反无人机能量容量约束,然后定义一个相应的Q值函数来评估风险的价值。因此,该算法有两个Q值函数,一个Q值函数用于评估成本,另一个Q值函数用于评估风险。然后,提出的风险敏感RL算法独立地更新两个不同的Q值函数,并根据两个Q值函数的和来选择动作。
四、个人小结
背景空天地一体化网络中,用无人机与物联网设备进行通信并收集其计算任务,然后实时地做出任务调度决策,是在本地处理,还是转发到基站,还是转发到低地球轨道卫星上进行处理。(1)先看目标:关键点在“实时”,所以本文目标是尽可能的降低总体时延。(2)接下来是约束,限制了卸载目的(基站,卫星,无人机)和卸载任务的数量,以及无人机的平均能耗。之前看过关于一篇关于调度的综述,就是说场景中有无人机的话,重点考虑其能耗;车联网物联网的话,重点考虑时延。(3)最后是算法,算法这块详细实现没看懂,大概写一下思路。由于能耗不是成本函数的组成部分,传统的RL就不能解决,所以本文提出了风险敏感的RL算法。除了代价函数外,定义一个额外的风险函数,用来捕捉无人机能耗是否违反约束,然后定义一个相应的Q值来评估风险的价值。因此,该算法有两个Q值函数,一个Q值函数用于评估成本,另一个Q值函数用于评估风险。根据两个Q值函数的和来选择动作。
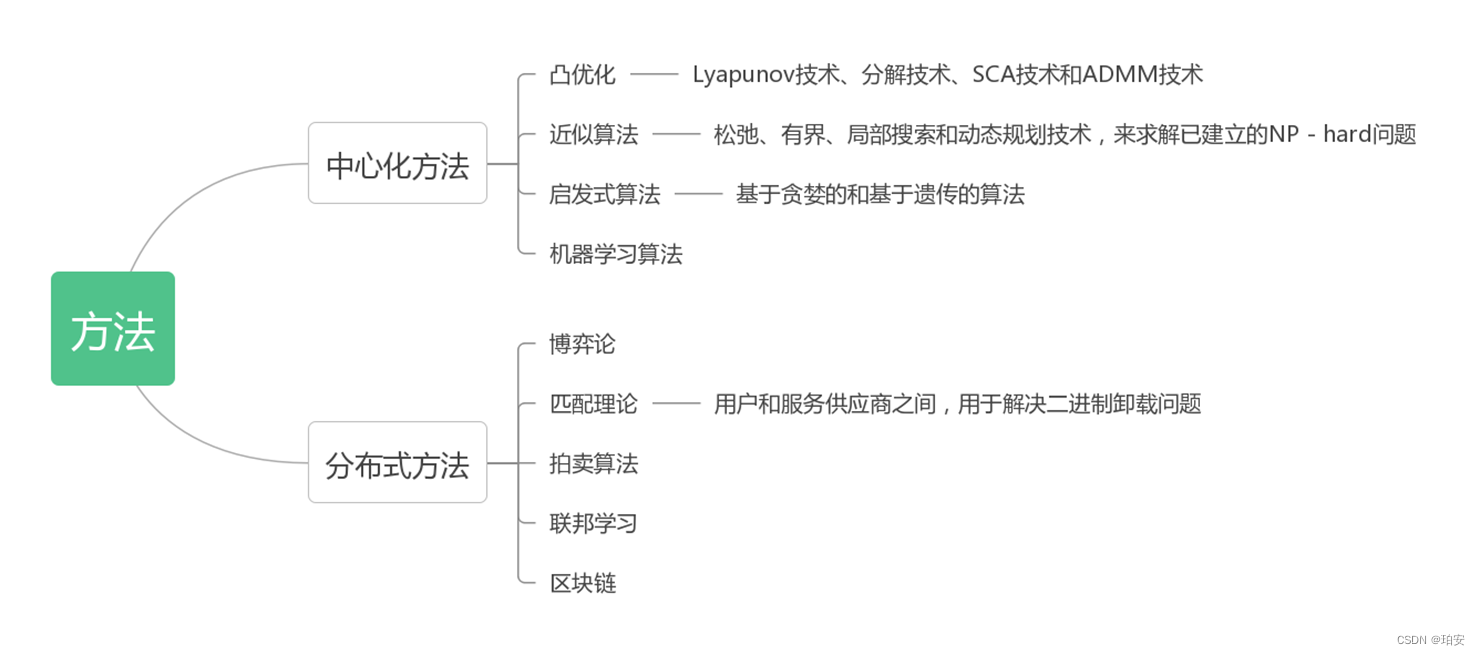
感觉这种调度类型的都是找目标,找约束,有的还会处理目标函数(P1->P2),然后是找个算法最大(小)化目标。算法这部分有这些:
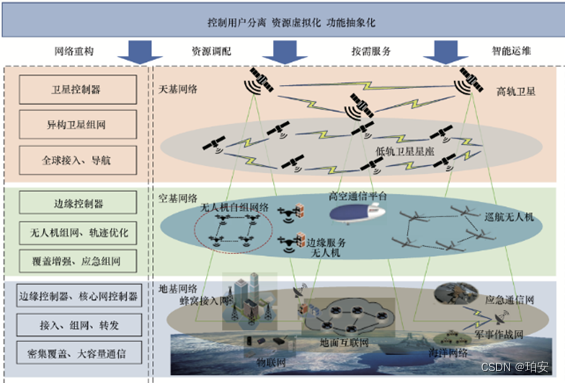
第一次看空天地方向的论文,还是有很多东西都没看懂。我理解的是,就是在之前看的那些网络的基础上加入了卫星这一层,基站提供大流量服务,以天基(高空通信平台,无人机网络,临近空间飞艇)网络和空基(卫星)网络为补充。覆盖范围扩大了很多,但是各个组件之间的交互也变得跟复杂了。有的还加入了海洋网络(下图),以实现全球互联。
-
参考文献
[1] Zhou C, Wu W, He H, 等. Deep Reinforcement Learning for Delay-Oriented IoT Task Scheduling in SAGIN[J]. IEEE Transactions on Wireless Communications, 2021, 20(2): 911-925.

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









