






关注公众号,发现CV技术之美
本文简要介绍由华中科技大学联合金山的研究人员提出的多模态大模型Monkey(Monkey : Image Resolution and Text Label Are Important Things for Large Multi-modal Models),通过低成本扩大分辨率+详细描述,帮助模型炼就洞察图像细节的火眼金睛,刷新多项SOTA,甚至能够完成GPT4V都发愁的密集文本问答难题。在 18 个不同的数据集上进行测试的结果表明,Monkey在图像描述生成、场景问答、以场景文本为中心的视觉问答和面向文档的视觉问答等任务中表现出有竞争力的性能。特别是,在以密集文本问答为主的定性评估中,与GPT4V相比,Monkey展现出了亮眼的结果。
详细信息如下:

论文链接:https://arxiv.org/abs/2311.06607
代码链接:https://github.com/Yuliang-Liu/Monkey
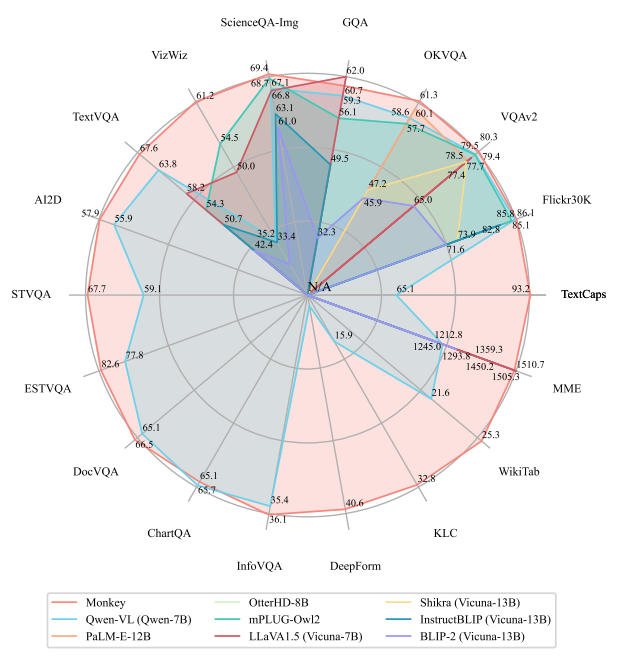
研究背景
近期,多模态大模型(LLMs)在视觉语言任务方面表现出了令人印象深刻的能力。然而,由于支持的输入分辨率(例如448 x 448)的限制以及训练图像文本对的不详尽描述,这些模型在处理复杂的场景理解和叙述时常常遇到挑战。
目前,大多数LMMs的输入图像被限制在224 x 224分辨率,与其架构中使用的视觉编码器的输入尺寸保持一致。然而,高分辨率的输入图像可以从图像中获得更多细节。一种提高输入分辨率的方法是使用更大输入分辨率的CLIP,但这种方式比较依赖预训练的CLIP模型,无法进一步提高分辨率;另一些模型通过在大规模训练过程中,不断提高输入图像的分辨率来获得更好的性能,但是这也导致巨大的训练消耗。
同时,高质量的图文数据对于LMMs的训练也十分重要,随着输入分辨率的扩大,图像-文本精细对齐的需求也进一步增加,因此现有数据集(如COYO[1]和LAION[2])中简短的单句描述无法满足需求。目前仍缺少详细的场景描述数据来进一步提高LMMs在复杂场景理解和叙述上的能力。
方法概述
1.增大输入分辨率
目前,大多数LMM(Language-Model-based Models)的输入图像分辨率通常为224 x 224,与它们架构中使用的CLIP模型的常规输入尺寸保持一致。然而,输入分辨率对于解释文本和复杂图像细节至关重要。目前的方法通过使用更大分辨率的CLIP模型,或者直接扩大视觉模块的输入分辨率后全量微调,这会导致巨大的训练消耗。
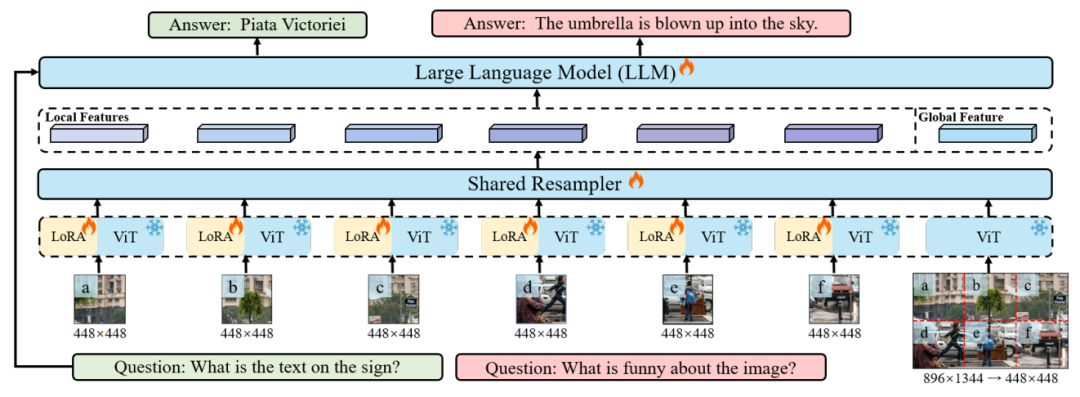
Monkey设计了一种更简单有效的方法,如图2所示。
给定一个H x W的图像,使用 x (和LMM分辨率一致)大小的滑动窗口将图像划分为更小的局部区域。Monkey对于每个图片块的编码器都增加了独属它的Lora[10]来有效地识别和吸收每个图像区域的细节敏感特征,从而增强对空间和上下文关系的理解。训练时只训练Lora部分,因此无需大幅增加参数量和计算需求。
原始图像大小也被调整为 x ,用于全局信息的提取。
最后,通过视觉编码器和重采样器处理所有局部图像和全局图像,并将局部特征和全局特征送入LLM。这种方法能够在不显着增加计算负载的情况下提高模型分辨率和性能。
2.多级特征融合的详细描述生成方法
之前的工作如LLaVA[3]、Qwen-VL[4]等依赖于互联网上爬取的大规模图文数据及进行模型的预训练。但这类数据标注比较简单,缺乏更丰富的图像细节。即使使用高分辨率图像进行训练, LMM 也无法在图像视觉特征和其中各个物体之间建立准确的关联,从而可能损害了视觉处理和语言理解之间的协同作用。
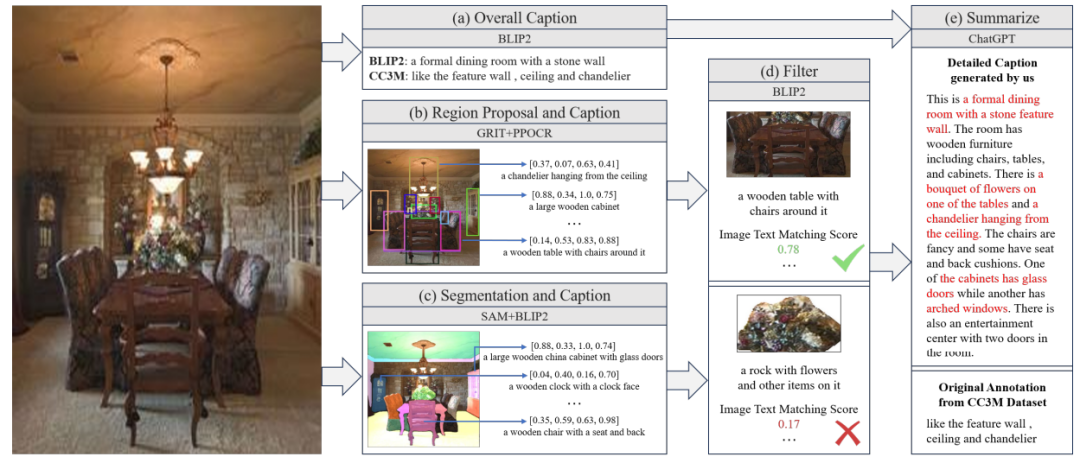
Monkey使用了一种多级特征融合的详细描述生成方法(利用 BLIP-2[5]、PP-OCR[6]、GRIT[7]、SAM[8]和 ChatGPT[9]等预训练系统),为CC3M中的400k图像提供更加细致的描述,来更好地将高分辨率的视觉模型和语言模型对齐。
全局描述生成: Monkey使用BLIP2对整张图生成全局描述,并且使用CC3M原始标注作为全局描述的补充。
区域框和对应描述生成:Monkey使用 GRIT生成区域框,并提供区域中对象的名称和详细描述,包括它们的属性、动作和数量等信息。同时为了提取图像中的文本信息,还会使用PPOCR提取图像中的文本框坐标和文本内容。
分割图和对应描述生成:首先使用SAM模型提取图像中各个物体及其组成部分的分割图,然后利用分割图将物体抠出,送入BLIP2生成对各个物体及其组成部分的详细描述。
过滤低质量局部描述:由于在zero-shot场景中模型难免会生成低质量的标注,为了确保局部描述的正确性,Monkey还使用BLIP-2 评估图像区域、对象及其描述性文本之间的一致性,过滤掉低分匹配。
ChatGPT总结:在最后阶段,将全局描述、过滤后的区域框和对应描述、过滤后的分割图和对应描述及其坐标输入 ChatGPT API 中总结。并让ChatGPT考虑各个物体之间的位置关系及其相互关联。
实验结果
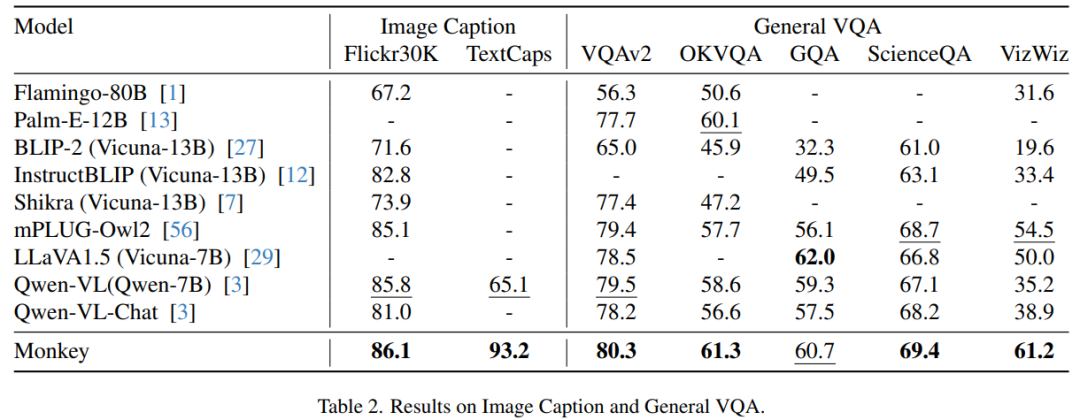
图像描述和通用VQA。详细描述能够帮助模型学习到图像中更多物体的属性,高分辨率的输入也能帮助模型看清更多细节。
场景文本VQA。高分辨率的输入能够帮助模型看清更小的文字,并且详细描述中包含的文本信息也进一步帮助模型学习。
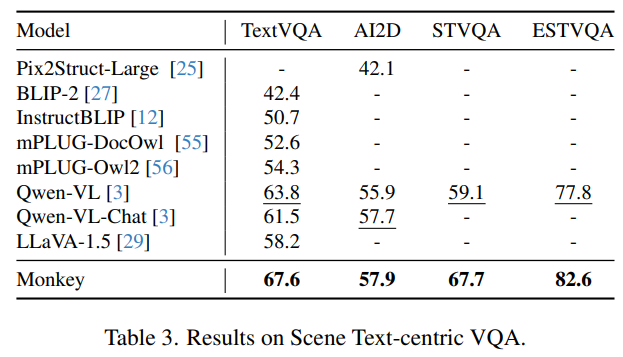
文档VQA。Monkey处理更大输入分辨率的能力增强了它的空间感知,从而提高了它对各种文档元素的识别和理解,如文本、图表、信息图等。
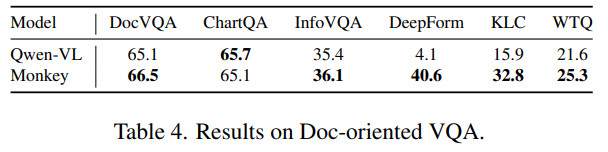
消融实验
表五中针对模型结构和输入分辨率的实验表明,提高分辨率能提高模型性能(r3-r9),四个LoRA能够帮助模型获得图像中不同部分的独特特征(r7 vs. r9),并帮助模型建立对空间和上下文关系的理解。进一步提高输入分辨率能够提高模型在文档等更高分辨率的图像上的性能(r5,r6)。同时,相比与直接插值扩大模型输入分辨率的方法相比(r1,r2 vs. r9),本文的方法在时间和性能上更具优势。表六中当把llava1.5的输入分辨率从224扩大为448,性能得到显著提升,进一步展现了本文方法的有效性。
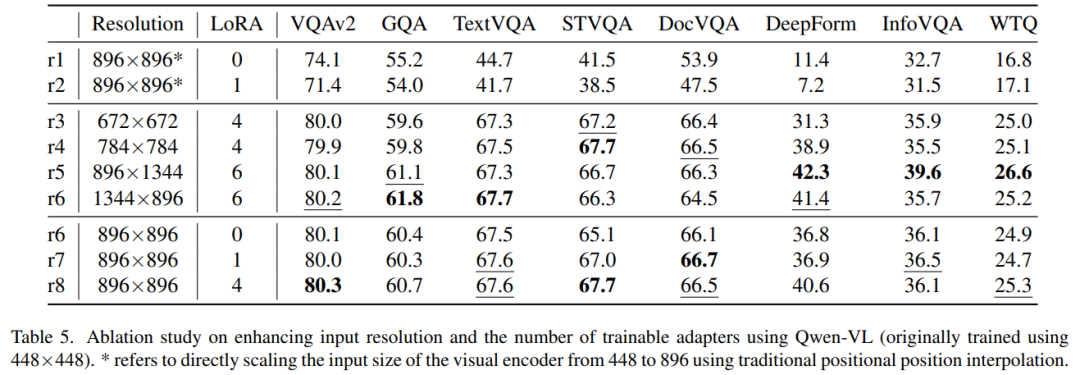
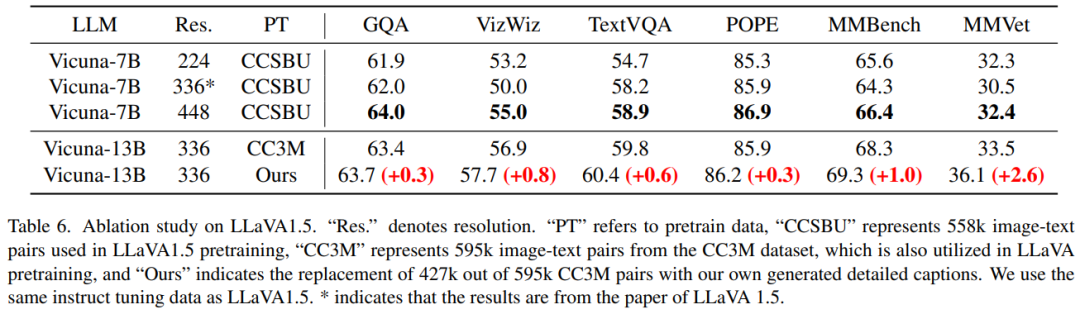
表六中使用生成的427k详细标注替换原始的CC3M标注,模型在6个benchmark上都获得了性能提升,这是因为预训练阶段中的详细描述使得模型在预训练时能够关注图像中的更多物体及其属性,从而实现视觉模块和语言模块之间更好的对齐。
可视化结果展示
详细描述: Monkey能够关注到其他LMM所不能注意到的文本细节,比如下图中隐藏在众多店铺之后的 “Emporio Armani”(仅有GPT4V和Monkey能够观察到)。 同时Monkey还观察并描述了多个细节,比如一个穿着红色连衣裙和白色外套的女人,另一位穿着红色外套和黑色裤子、提着黑色手提包的女士,以及图像左侧带着太阳眼镜的女人的照片。

密集文本问答:在密集文本问答任务中,Monkey表现尤为出色,甚至能够完成GPT4V都发愁的难题。 在物品标签的密集文本中,Monkey能够准确回答出物品的各种信息,相比于GPT4V有十分亮眼的表现。


日常生活场景: Monkey在日常生活场景中的表现也毫不逊色 。能够完成各种问答任务,识别图像中的水印,详细描述图像中的各种细节尤其是细小的文本。

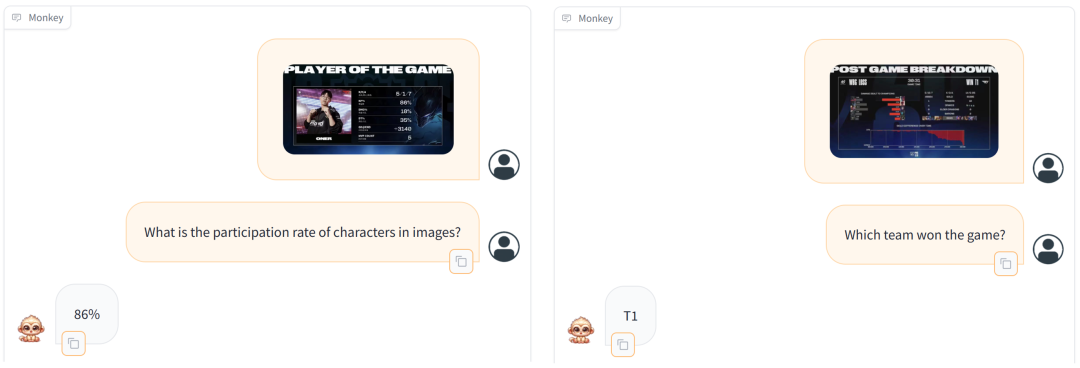
除此之外,Monkey还表现出强大的泛化性,在刚刚结束的2023英雄联盟全球总决赛上,Monkey能够根据结算面板读取出比赛中的各种信息。
总结
Monkey提出了一种训练高效的方法,无需预训练即可有效地提高模型的输入分辨率,最高可达896 x 1344像素。为了弥补简单文本标签和高分辨率输入之间的差距,Monkey提出了一种多级特征融合的详细描述生成方法,它可以自动提供丰富的信息,以引导模型学习图像中各个物体的属性及其联系。通过这两种设计的协同作用,Monkey在多个基准测试中取得了出色的结果。通过与包括GPT4V在内的各种多模态模型进行比较,Monkey在详细描述生成,场景问答,以场景文本为中心的视觉问答和面向文档的视觉问答方面表现出色,刷新多项SOTA,特别是Monkey甚至完成GPT4V都发愁的密集文本问答任务。
相关资源
论文地址:https://arxiv.org/abs/2311.06607
代码地址:https://github.com/Yuliang-Liu/Monkey
Demo, Detailed Caption, Model Weight 地址:见github
参考资料
[1] Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun 496 Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: 497 Image-text pair dataset. https : / / github . com / 498 kakaobrain/coyo-dataset, 2022.
[2] Schuhmann C, Beaumont R, Vencu R, et al. Laion-5b: An open large-scale dataset for training next generation image-text models[J]. Advances in Neural Information Processing Systems, 2022, 35: 25278-25294.
[3] Liu H, Li C, Wu Q, et al. Visual instruction tuning[J]. arXiv preprint arXiv:2304.08485, 2023.
[4] Bai J, Bai S, Yang S, et al. Qwen-vl: A frontier large vision-language model with versatile abilities[J]. arXiv preprint arXiv:2308.12966, 2023.
[5] Li J, Li D, Savarese S, et al. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[J]. arXiv preprint arXiv:2301.12597, 2023.
[6] Du Y, Li C, Guo R, et al. Pp-ocr: A practical ultra lightweight ocr system[J]. arXiv preprint arXiv:2009.09941, 2020.
[7] Wu J, Wang J, Yang Z, et al. Grit: A generative region-to-text transformer for object understanding[J]. arXiv preprint arXiv:2212.00280, 2022.
[8] Kirillov A, Mintun E, Ravi N, et al. Segment anything[J]. arXiv preprint arXiv:2304.02643, 2023.
[9] OpenAI. ChatGPT. https://openai.com/blog/687chatgpt/, 2023.
[10] Hu E J, Shen Y, Wallis P, et al. Lora: Low-rank adaptation of large language models[J]. arXiv preprint arXiv:2106.09685, 2021.
[11] OpenAI. Gpt-4v(ision) system card. 2023b

END
欢迎加入「大模型」交流群👇备注:LLM


















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









