







自动驾驶系统中,由于交通参与者和感知的不确定性,在密集交通流场景中决策是非常苦难的。POMDP(partially observable Markov decision process)是解决不确定问题的系统性的工具,但是在实际的大规模问题中,其计算非常耗时。论文提出了高效的不确定性下决策框架(EUDM, efficient uncertainty-aware decision-making),在复杂的行驶环境中产生横纵向决策。使用特定领域闭环策略树(DCP-Tree, domain-specific closed-loop policy tree)和条件聚焦剪枝机制(conditional focused branching),利用了特定领域的专家经验对行为空间和意图空间进行剪枝,减少计算量。
论文是在MPDM(multipolicy decision-making)的基础改进的。MPDM使用有限几个语义级策略(例如换道、车道保持)进行闭环的前向仿真,而不是使用车辆所有可能的控制输入。MPDM有两个不足:一是在整个规划时域内只有一个语义决策,二是在初始预测状态不准确的情况下,可能会生成不安全的决策。
1. 架构
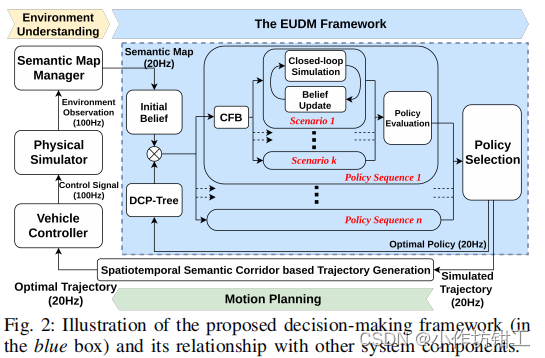
DCP-Tree构造一个语义级的行为空间。决策树上的每个节点都是主车的一个语义级行为,从根节点到叶子节点的每一条轨迹都表示主车的一系列语义级行为,并且语义级行为可以在规划时域内改变一次,每条行为轨迹会在闭环仿真中计算。DCP-Tree决定了主车的行为,但是其他车辆的行为仍然是不知道的。由于和其他车辆的行为意图组合是指数级增长的,CFB机制在主车行为序列的条件下,使用开环安全评估,挑选出可能存在风险的场景。
DCT-Tree将主车的行为空间剪枝,在上一步最优策略的基础上构建决策树。对于主车的每个行为序列(DCP-Tree的每条轨迹),CFB机制通过挑选出主车附近车辆可能具有风险的行为来进行意图空间剪枝。CFB产生一系列场景,其是主车附近车辆的不同的意图的组合。每个场景考虑多智能体之间的交互,使用闭环仿真计算,所有场景进行cost计算,并对有风险的场景进行惩罚。
EUDM输出的最优决策是主车和其他车辆通过闭环前方仿真生成的一系列离散状态,时间分辨率是 0.4 s 0.4s 0.4s。下面是EUDM的伪代码,可以发现两个 f o r for for循环都可是使用多线程并行计算。

2. POMDP
P O M D P POMDP POMDP由七元组 < S , A , T , R , Z , O , γ > <\mathcal{S,A,T,R,Z,O,\gamma}> <S,A,T,R,Z,O,γ>构成,分别是状态空间,动作空间,状态转移函数,回报函数,观测空间,观测函数和折扣因子。智能体的状态是部分可观测的,使用置信度 b b b描述, b b b是在 S \mathcal{S} S上的概率分布。在给定的动作 a a a和观测 z z z下,使用贝叶斯计算 b t b_t bt, b t = τ ( b t − 1 , a t − 1 , z t ) b_t = \tau(b_{t-1},a_{t-1},z_t) bt=τ(bt−1,at−1,zt)。在线 P O M D P POMDP POMDP是在初始置信度 b 0 b_0 b0情况下,计算最优策略 π ∗ \pi^* π∗,是在整个规划时域 t h t_h th内总的期望折扣回报最大。
P O M D P POMDP POMDP置信度树的复杂度为 O ( ∣ A ∣ h ∣ Z ∣ h ) \mathcal{O}(|\mathcal{A}|^h |\mathcal{Z}|^h) O(∣A∣h∣Z∣h), h h h深度为树的深度,其是指数级增长的,一般采用蒙特卡洛采样的方法计算来解决维度灾难(Curse of Dimensionality)和历史灾难(Curse of History),同时,启发式搜索、剪枝(branch-and-bound)和可行性分析(reachability analysis)可以加快求解。
3. DCP-Tree
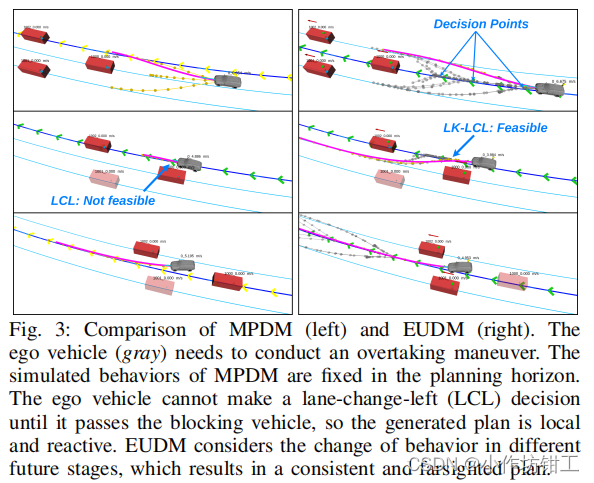
MPDM在规划周期内只有一种行为决策,会导致局部最优和不适合用于长期决策。DCP-Tree允许主车在规划周期内改变行为决策,DCP-Tree将上一帧规划正在执行的最优动作 a ^ \hat{a} a^作为当前帧决策树的根节点,并且在每一幕(episode)都将 a ^ \hat{a} a^作为根节点。由于允许在规划周期内改变策略,会使策略序列指数级增长,因此,文章只允许行为策略(action)在规划周期内改变一次,来回变化的(back and forth)行为会在帧与帧之间形成。

例如,当前的action是 L K LK LK,那么后续的行为策略可以是 ( L K − L C − L C − L C ⋯ ) (LK-LC-LC-LC \cdots) (LK−LC−LC−LC⋯), ( L K − L K − L C − L C ⋯ ) (LK-LK-LC-LC \cdots) (LK−LK−LC−LC⋯)和 ( L K − L K − L K − L C ⋯ ) (LK-LK-LK-LC \cdots) (LK−LK−LK−LC⋯),因此DCP-Tree的叶子节点的个数为 O [ ( ∣ A − 1 ∣ ) ( h − 2 ) + ∣ A ∣ ] \mathcal{O} [(|\mathcal{A} - 1|)(h-2) + |\mathcal{A}|] O[(∣A−1∣)(h−2)+∣A∣],是随着决策树的深度 h h h线性增加的。可以看出MPDM是DCP-Tree的一个分支。
3.1 语义行为
文章同时考虑的横纵向action以保证驾驶策略的多样性。定义横向动作为 { L K , L C L , L C R } \{ LK, LCL, LCR \} {LK,LCL,LCR},纵向动作为 { a c c e l e r a t e , m a i n t a i n s p e e d , d e c e l e r a t e } \{accelerate, maintain speed, decelerate\} {accelerate,maintainspeed,decelerate},其中纵向动作连续的期望速度作用在前向仿真模型中,而不是离散的加速度指令。每个语义动作的执行时间为 2 s 2s 2s,仿真的时间分别率为 0.4 s 0.4s 0.4s,DCP-Tree的深度为 4 4 4,因此规划周期为 8 s 8s 8s,频率为 20 H z 20Hz 20Hz。
4. CFB
DCP-Tree对 A \mathcal{A} A进行了剪枝,但是周围车辆的意图空间是随着车辆数目的增多指数级增长的。MPDM使周围车辆的意图在整个规划周期内是固定不变的,这样会导致有的风险不能被识别出来。
CFB机制设计的目的是使用产生风险的决策分支只可能的少。"conditional"的意思是在主车行为决策序列的条件下。其动机来自于我们的观察:当人们打算进行不同的动作时,人类驾驶员对附近车辆的注意会有不同的偏差。例如,当一个驾驶员意图向左换道时,其会更加注意左侧车道的情况。因此,基于主车的行为决策序列(one episode of DCP-Tree),可以挑选出一系列相关的车辆。在论文中的挑选方式使用了基于规则的方法,在Epsilon中使用了学习的方法。
通过CFB机制,可以挑选出相关车辆,论文并没有对这些车辆的所有可能的交互行为进行枚举,而是使用初步的安全校验挑选出需要特殊注意的车辆。初步的安全校验使用基于多重假设的开环仿真,比如对于意图不确定的车辆,我们分别预测车辆在变道和车道保持情况下会发生什么。使用忽略交互的开环仿真计算最坏的情况。对没有通过初步安全校验的车辆,使用闭环前向仿真对不同场景进行仿真。对于通过安全校验的车辆,基于初始置信度 b 0 b_0 b0计算最大后验值(maximum a posteriori)。因此,意图空间中的分支被引导到潜在的风险场景。在实践中,我们发现初步的安全检查虽然设计简单,但可以识别许多危险案例。
(1)识别关键车辆目标:在主车当前车道和相邻车道的前后一定范围内车辆作为关键车辆目标,距离范围和主车速度相关。
(2)不确定意图的车辆识别:根根初始置信度 b 0 b_0 b0识别,即三种意图的概率分布接近均匀分布。
(3)安全评估:使用开环仿真,如果安全评估失败,则枚举可能的意图并计算其概率;
(4)场景挑选:根据偏好定义,挑选出概率最高的 k k k个场景,并且marginalize概率分布,将其作为权重。
5. 前方仿真
使用IDM模型和纯跟踪控制作为横纵向仿真模型。
6. 置信度更新
周围车辆的隐藏意图包括 { L K , L C L , L C R } \{ LK, LCL, LCR \} {LK,LCL,LCR},其置信度通过前向仿真更新。文章使用基于规则的置信度计算方法:例如前车和跟随车辆的速度差,RSS和换道模型。在简单工况下效果良好,后续(Epislon)使用基于学习的方法。
7. 策略计算
某个策略的回报是策略序列产生的CFB选择的场景汇报的概率加权和,奖励的计算由效率,安全性和连续性的线性加权计算。
8. 轨迹产生
使用SSC planner。















 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









