









博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!

本篇博文将详细总结隐马模型相关知识,理解该模型有一定的难度,在此浅薄的谈下自己的理解。参考的实现代码:HMM_EM(无监督式),HMM有监督式
文章目录
- 概率计算问题
- HMM的三个问题
- 问题一:给定模型 λ = ( A , B , π ) \lambda = (A,B,\pi) λ=(A,B,π) 和观测序列 O = o 1 , o 2 , . . , o T O={o_1,o_2,..,o_T} O=o1,o2,..,oT,计算模型 λ \lambda λ 下观测序列O出现的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)
- 第二个问题:学习问题,给出观测序列 O O O,估计模型参数 λ = ( π , A , B ) \lambda =(\pi,A,B) λ=(π,A,B),使得 P ( O ∣ λ ) P(O|\lambda) P(O∣λ) 最大,显然用MLE的方式来估计。
- 问题三:预测算法
- HMM缺点
- 个人总结
概率计算问题
H M M HMM HMM 是关于时序的概率模型,描述由一个隐藏的马尔科夫链生成不可观测的状态随机序列,再由各个状态生成观测随机序列的过程。
隐马尔科夫模型随机生成的状态随机序列,称为状态序列;每个状态生成一个观测,由此产生的观测随机序列,称为观测序列。序列的每个位置可看做是一个时刻。
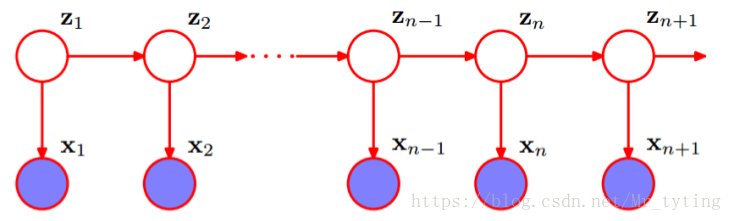
上图中的 Z Z Z 表示状态序列, X X X 表示观测序列。假设每个时刻的状态可能有 N N N 种可能,每个时刻的观测可能有 M M M 种可能。
H
M
M
HMM
HMM 由初始概率分布
π
π
π、状态转移概率分布
A
A
A 以及观测概率分布
B
B
B 确定。
λ
=
(
A
,
B
,
π
)
\lambda =(A, B, \pi)
λ=(A,B,π)
这个初始概率分布 π π π 是一个大小为 N N N 的向量, A A A 为大小为 N ∗ N N*N N∗N 的矩阵, B B B 为大小为 N ∗ M N*M N∗M 的矩阵。
-
I
I
I 是长度为
T
T
T 的状态序列,
O
O
O 是对应的观测序列,则有:
I = { i 1 , i 2 , . . . , i T } ; O = { o 1 , o 2 , . . . , o T } \ I =\{i_1, i_2,...,i_T\};O=\{o_1,o_2,...,o_T\} I={i1,i2,...,iT};O={o1,o2,...,oT} -
A
A
A 是状态转移概率矩阵,则有:
A = [ a i j ] N ∗ N A=[a_{ij}]_{N*N} A=[aij]N∗N
其中 a i j = P ( i t + 1 = q j ∣ i t = q i ) a_{ij}=P(i_{t+1}=q_j|i_t=q_i) aij=P(it+1=qj∣it=qi) 表示在时刻 t t t 处于状态 q i q_i qi 的条件下时刻 t + 1 t+1 t+1 转移到状态 q j q_j qj 的概率。
HMM的两个基本性质
齐次假设:
P
(
i
t
∣
i
t
−
1
,
o
t
−
1
,
i
t
−
2
,
o
t
−
2
.
.
.
i
1
,
o
1
)
=
P
(
i
t
∣
i
t
−
1
)
P(i_t|i_{t-1},o_{t-1},i_{t-2},o_{t-2}...i_1,o_1)=P(i_t|i_{t-1})
P(it∣it−1,ot−1,it−2,ot−2...i1,o1)=P(it∣it−1)
也即是当前时刻的隐状态只与前一时刻的隐状态有关。
观测独立性假设:
P
(
o
t
∣
i
T
,
o
T
,
i
T
−
1
,
o
T
−
1
,
.
.
.
,
i
1
,
o
1
)
=
P
(
o
t
∣
i
t
)
P(o_t|i_T,o_T,i_{T-1},o_{T-1},...,i_1,o_1) = P(o_t|i_t)
P(ot∣iT,oT,iT−1,oT−1,...,i1,o1)=P(ot∣it)
也即是当前时刻的观测状态只与当前时刻的隐状态有关。
HMM的三个问题
问题一:给定模型 λ = ( A , B , π ) \lambda = (A,B,\pi) λ=(A,B,π) 和观测序列 O = o 1 , o 2 , . . , o T O={o_1,o_2,..,o_T} O=o1,o2,..,oT,计算模型 λ \lambda λ 下观测序列O出现的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)
我们先看看代码中,是如何做的,参考的代码中,数据的格式为 [ 900 , 2 ] [900,2] [900,2],假设了这是由三个高斯模型混合而成的样本集,每个样本有两个特征,共900个样本。注意:样本个数也即是上面所说的步长 T T T。形如:
5.8045294e-01 9.6570931e-01
1.0101383e+00 3.9152260e-01
-4.1251308e-01 9.6435345e-01
-2.0477262e+00 1.5029133e+00
-1.3130763e+00 1.6049016e-01
-6.2352642e-01 3.7779862e-01
1.8841870e+00 1.1210070e+00
2.5608726e+00 -1.4935448e+00
3.2966895e-01 -1.1184212e+00
-1.1982074e+00 7.4402510e-01
7.1916729e-01 1.2625977e+00
-3.6946331e-01 1.4573214e+00
-7.3522039e-01 7.0942551e-02
-4.8153116e-01 1.3661593e+00
然后需要初始化出上面所讲的模型的三个要素 π 、 A 、 B \pi、A、B π、A、B。
def initForwardBackward(X,K,d,N):##X为数据集,K为隐状态数,在这里为3,d为观测状态数,N为时刻总数,共N步。
# Initialize the state transition matrix, A. A is a KxK matrix where
# element A_{jk} = p(Z_n = k | Z_{n-1} = j)
# Therefore, the matrix will be row-wise normalized. IOW, Sum(Row) = 1
# State transition probability is time independent.
A = np.ones((K,K))##隐状态转移矩阵初始为1
A = A/np.sum(A,1)[None].T ##需要保证每列之和为1
# Initialize the marginal probability for the first hidden variable
# It is a Kx1 vector
PI = np.ones((K,1))/K## 初始pi,即为第0时刻转移到某个隐状态的概率
## 这里我们假设发射矩阵服从高斯分布,所以我们只需要定义均值和方差即可。
## 显然对于不同的隐状态,会得到不同的观测序列。即对于不同的隐状态有不同的高斯分布
## 并且这里数据集每个样本有d(d=2)个feature,相当于有多维度随机变量,每个随机变量的分布都有不同的均值
## 所以MU的shape为[d,k],即每个隐状态对应d个均值
## 每个隐状态对应有不同的协方差矩阵
MU = np.random.rand(d,K)
SIGMA = [np.eye(d) for i in xrange(K)]
return A, PI, MU, SIGMA
这样我们就得到初始的 π \pi π ,状态转移矩阵 A A A,发射矩阵 M U , S I G M A MU, SIGMA MU,SIGMA。
前向后向算法—动态规划
给定模型 λ = ( A , B , π ) \lambda =(A, B, \pi) λ=(A,B,π) 和观测序列 O = { o 1 , o 2 , . . . , o T } O=\{o_1,o_2,...,o_T\} O={o1,o2,...,oT} ,计算模型 λ λ λ 下观测序列 O O O 出现的概率 P ( O ∣ λ ) P(O| λ) P(O∣λ)。
我们首先尝试直接用暴力求解:
- 状态序列
I
=
{
i
1
,
i
2
,
.
.
.
,
i
T
}
\ I=\{i_1,i_2,...,i_T\}
I={i1,i2,...,iT} 的概率是:
P ( I ∣ λ ) = π i 1 α i 1 i 2 α i 2 i 3 . . . α i T − 1 i T P(I|\lambda)=\pi_{i_1}\alpha_{i_1i_2}\alpha_{i_2i_3}...\alpha_{i_{T-1}i_T} P(I∣λ)=πi1αi1i2αi2i3...αiT−1iT - 对固定的状态序列
I
I
I,测序列
O
O
O 的概率是:
P ( O ∣ I . λ ) = b i 1 o 1 b i 2 o 2 . . . b i T o T P(O|I. \lambda)=b_{i_1o_1}b_{i_2o_2}...b_{i_To_T} P(O∣I.λ)=bi1o1bi2o2...biToT -
O
O
O 和
I
I
I 同时出现的联合概率是:
P ( o , I ∣ λ ) = P ( o ∣ I , λ ) P ( I ∣ λ ) = π i 1 b i 1 o 1 a i 1 i 2 b i 2 o 2 . . . P(o,I|\lambda)=P(o|I,\lambda)P(I|\lambda)=\pi_{i_1}b_{i_1o_1}a_{i_1i_2}b_{i_2o_2}... P(o,I∣λ)=P(o∣I,λ)P(I∣λ)=πi1bi1o1ai1i2bi2o2... - 对所有可能的状态序列
I
I
I 求和,得到观测序列
O
O
O 的概率
P
(
O
∣
λ
)
P(O|λ)
P(O∣λ):
P ( o ∣ λ ) = ∑ I P ( o , I ∣ λ ) = ∑ I P ( o ∣ I , λ ) P ( I ∣ λ ) P(o|\lambda) =\sum_{I}P(o,I|\lambda)=\sum_{I}P(o|I,\lambda)P(I|\lambda) P(o∣λ)=I∑P(o,I∣λ)=I∑P(o∣I,λ)P(I∣λ)
我们可以试想,在每一个时刻,隐状态都有 N N N 个选择,一共有 T T T 个时刻,故 T N T^N TN ,而求和里面共有 2 T 2T 2T 个因子,故时间复杂度为 O ( T N T ) O(TN^T) O(TNT)。
显然直接暴力计算 P ( o , I ∣ λ ) P(o,I|\lambda) P(o,I∣λ) 时间复杂度过高。
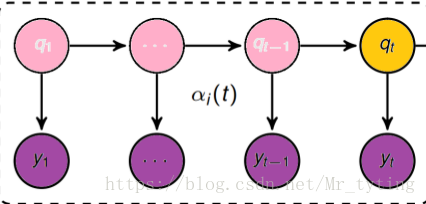
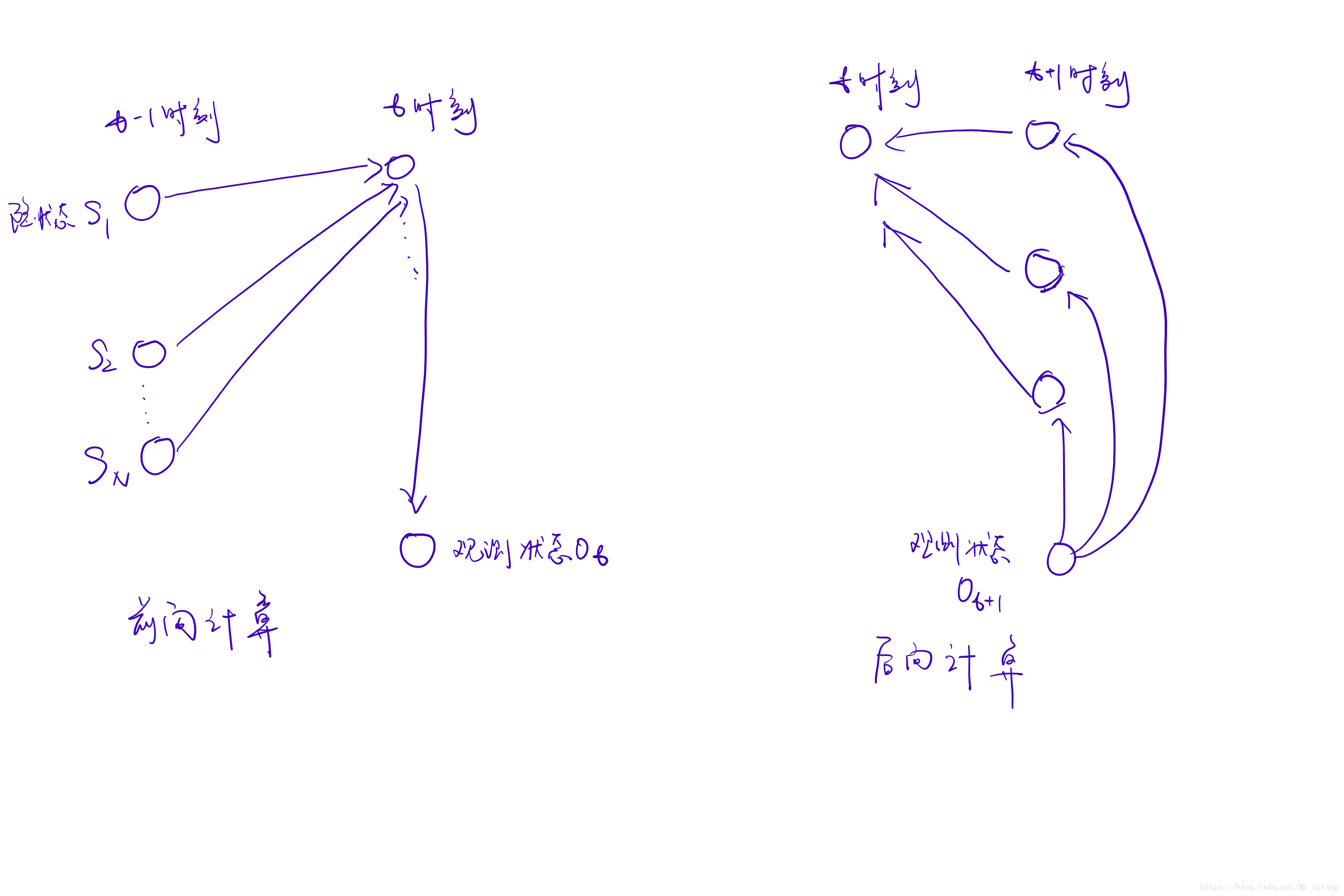
前向概率
定义:给定
λ
λ
λ,定义到时刻
t
t
t 部分观测序列为
o
1
,
o
2
.
.
.
o
t
o_1,o_2...o_t
o1,o2...ot 且状态为
q
i
q_i
qi 的概率称为前向概率,记做:
α
t
(
i
)
=
P
(
o
1
,
o
2
,
.
.
,
o
t
,
q
t
=
i
∣
λ
)
\alpha_t(i)=P(o_1,o_2,..,o_t,q_t=i|\lambda)
αt(i)=P(o1,o2,..,ot,qt=i∣λ)
-
初值:
α 1 ( i ) = π i b i o 1 \alpha_1(i)=\pi_ib_{io_1} α1(i)=πibio1 -
递推:对于 t = 1 , 2... T − 1 t=1,2...T-1 t=1,2...T−1(注意这是一个从前向后的递推过程)
需要注意上一步,在第 t t t 步时,位于隐状态 j j j 的概率转移到第 t + 1 t+1 t+1 步的隐状态 i i i,这里面的 j j j 有 N N N 种情况, i i i 也有 N N N 种情况,在第 t + 1 t+1 t+1 步的隐状态 i i i 对应有前一步的 N N N 种情况求和(这也是为什么前向计算能得出 q t = i q_t=i qt=i),然后再乘以发射概率。作为第 t + 1 t+1 t+1 步处于该种隐状态的概率值。注意 b i o t + 1 b_{io_{t+1}} biot+1 的意义,为当前隐状态 i i i 生成特定 O t + 1 O_{t+1} Ot+1 的概率。 ** -
最终可得:
对 i i i 积分,其结果即为生成指定的 o 1 , o 2 , o 3 , . . . . , o t o_1,o_2,o_3,....,o_t o1,o2,o3,....,ot 的观测序列的概率。
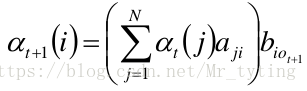
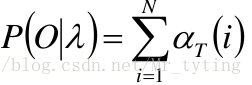
前向算法的时间复杂度是
O
(
N
2
T
)
O(N^2T)
O(N2T)。
那么在代码中是如何实现前向计算的呢?
def buildAlpha(X,PI,A,MU,SIGMA):## X.shape[feature,N]
# We build up Alpha here using dynamic programming. It is a KxN matrix
# where the element ALPHA_{ij} represents the forward probability
# for jth timestep (j = 1...N) and ith state. The columns of ALPHA are
# normalized for preventing underflow problem as discussed in secion
# 13.2.4 in Bishop's PRML book. So,sum(column) = 1
# c_t is the normalizing costant
N = np.size(X,1)
K = np.size(PI,0)
## 这里需要注意Alpha的shape为[K,N],表示在某个时刻为某个特定隐藏状态,其生成从开始时刻到当前时刻观测序列的概率
Alpha = np.zeros((K,N))
c = np.zeros(N)
# Base case: build the first column of ALPHA
for i in xrange(K):
## PI[i]表示选择该隐状态的概率值。
## normPDF(X[:,0],MU[:,i],SIGMA[i])表示该样本在该隐状态下的高斯分布下对应的概率值
┆ Alpha[i,0] = PI[i]*normPDF(X[:,0],MU[:,i],SIGMA[i])##也就是当前时刻的发射概率
c[0] = np.sum(Alpha[:,0])## 每列求和
Alpha[:,0] = Alpha[:,0]/c[0]## 归一
# 以下就是上面所讲的从前往后的递推过程
for t in xrange(1,N):
┆ for i in xrange(K):
┆ ┆ for j in xrange(K):
┆ ┆ ┆ Alpha[i,t] += Alpha[j,t-1]*A[j,i] # sum part of recursion
┆ ┆ Alpha[i,t] *= normPDF(X[:,t],MU[:,i],SIGMA[i]) # product with emission prob
┆ c[t] = np.sum(Alpha[:,t])
┆ Alpha[:,t] = Alpha[:,t]/c[t] # for scaling factors
return Alpha, c ##注意函数返回的Alpha的shape为[K,N]
特别需要注意上面所求矩阵 A l p h a Alpha Alpha 的意义:其 s h a p e shape shape 为 [ K , N ] [K,N] [K,N],表示在某个时刻为某个特定隐藏状态,其生成从开始时刻到当前时刻观测序列的概率。
后向计算(同前向计算同理,只不过是从后向前计算)
定义:给定
λ
λ
λ,定义到时刻
t
t
t 状态为
q
i
q_i
qi 的前提下,从
t
+
1
t+1
t+1 到
T
T
T 的部分观测序列为
o
t
+
1
,
o
t
+
2
.
.
.
o
T
o_{t+1} ,o_{t+2} ...o_T
ot+1,ot+2...oT 的概率为后向概率,记做:
β
t
(
i
)
=
P
(
o
t
+
1
,
o
t
+
2
,
.
.
.
,
o
T
∣
i
t
=
q
i
.
λ
)
\beta_t(i)=P(o_{t+1},o_{t+2},...,o_T|i_t=q_i.\lambda)
βt(i)=P(ot+1,ot+2,...,oT∣it=qi.λ)
- 初值:
β T ( i ) = 1 \beta_T(i)=1 βT(i)=1
此时, 观测值为 O T + 1 O_{T+1} OT+1。故为 1 1 1 - 递推:对于
t
=
T
−
1
,
T
−
2...
,
1
t=T-1,T-2...,1
t=T−1,T−2...,1(注意:这是一个从后向前的递推过程)
这里需要注意 β t + 1 ( j ) \beta_{t+1}(j) βt+1(j) 是可以得到 O t + 2 , O t + 3 , . . . O_{t+2},O_{t+3},... Ot+2,Ot+3,... 而不知道 O t + 1 O_{t+1} Ot+1,所以对于不同的 j j j ,都要乘以 b j o t + 1 b_{jo_{t+1}} bjot+1。 - 最终:
看看代码中是如何实现后向计算的:
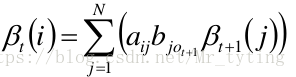
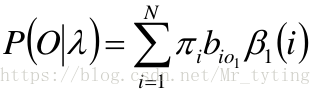
def buildBeta(X,c,PI,A,MU,SIGMA):## X.shape[features, N]
# Beta is KxN matrix where Beta_{ij} represents the backward probability
# for jth timestamp and ith state. Columns of Beta are normalized using
# the element of vector c.
N = np.size(X,1)
K = np.size(PI,0)
Beta = np.zeros((K,N))## 同上,shape也是[K,N],表示某一时刻的隐状态为某一隐状态从最后生成到当前时刻序列的概率。
# Base case: build the last column of Beta
for i in xrange(K):
┆ Beta[i,N-1]=1.## 此时,观测值为$O_{N}$。故为1
┆
# 按照上面所说的从后向前进行递推。直到t==0时。
for t in xrange(N-2,-1,-1):
┆ for i in xrange(K):
┆ ┆ for j in xrange(K):
┆ ┆ ┆ Beta[i,t] += Beta[j,t+1]*A[i,j]*normPDF(X[:,t+1],MU[:,j],SIGMA[j])
┆ Beta[:,t] /= c[t+1]
return Beta
一定要注意上面代码中,矩阵 β \beta β 的意义:shape也是[K,N],表示某一时刻的隐状态为某一隐状态生成从最后时刻到当前时刻指定序列的概率。
前向后向概率的关系
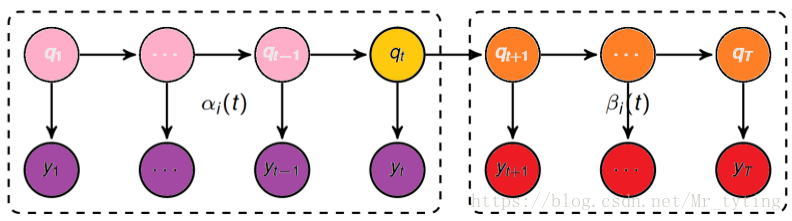

这种前向后向计算,每次都是在上一层的基础上进行递推,相对于暴力计算方法,避免了大量的重复计算,降低了复杂度,计算只存在于相邻的时间点内。
单个状态的概率
求给定模型
λ
λ
λ 和观测
O
O
O,在时刻t处于状态
q
i
q_i
qi 的概率。记:
γ
t
(
i
)
=
P
(
i
t
=
q
i
∣
O
,
λ
)
\gamma_t(i) = P(i_t=q_i|O,\lambda)
γt(i)=P(it=qi∣O,λ)
可计算得:
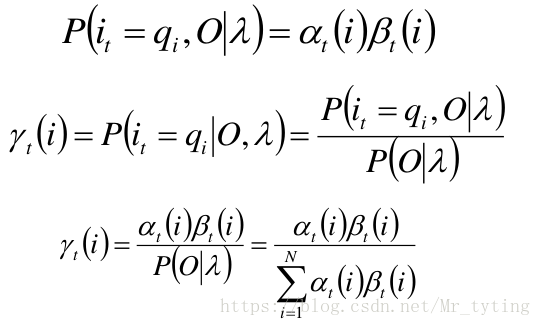
Gamma = Alpha*Beta ## 矩阵点乘,shape为[k,N],这里没有除以分母,分母即所求gamma矩阵所在列之和。
这个Gamma主要是在M步更新PI的,故在M步再除分母一样
这就意味着只要我们知道 T T T 个观测序列,和模型 λ \lambda λ(初始状态,状态矩阵,状态转移矩阵),就可以计算每个时刻的隐状态。即:在每个时刻 t t t 选择在该时刻最有可能出现的状态 i t ∗ i_t^* it∗ ,从而得到一个状态序列 I ∗ = i 1 ∗ , i 2 ∗ . . . i T ∗ I^* ={i_1^* , i_2^ *... i_T^* } I∗=i1∗,i2∗...iT∗,将它作为预测的结果。
两个状态的联合概率
求给定模型
λ
λ
λ 和观测
O
O
O,在时刻
t
t
t 处于状态
q
i
q_i
qi 并且时刻
t
+
1
t+1
t+1 处于状态
q
j
q_j
qj 的概率。
ε
t
(
i
,
j
)
=
P
(
i
t
=
q
i
,
i
t
+
1
=
q
j
∣
O
,
λ
)
\varepsilon _t(i,j)=P(i_t=q_i,i_{t+1}=q_j|O,\lambda)
εt(i,j)=P(it=qi,it+1=qj∣O,λ)
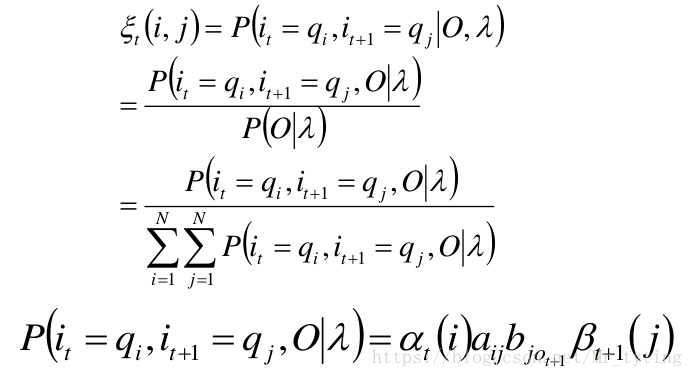
那么在代码中如何实现 ε t ( i , j ) \varepsilon _t(i,j) εt(i,j) 呢?首先我们可以试想, i i i 共有三种状态, j j j 也有三种状态,故每相邻的状态转移共有 9 9 9 种转移方式。而代码中共有 N = 900 N=900 N=900 个时刻。故 ε t ( i , j ) \varepsilon _t(i,j) εt(i,j) 的 s h a p e [ 3 , 3 , 900 ] shape[3,3,900] shape[3,3,900]。
i = np.zeros((K,K,N))
for t in xrange(1,N):
## 每个时刻都是3*3 的矩阵,\alpha_{T}(i)*a_{ij}*\Beta_{t+1}(j),i,j都有k种可能,故a_{ij}就是转移矩阵A。
Xi[:,:,t] = (1/c[t])*Alpha[:,t-1][None].T.dot(Beta[:,t][None])*A
# Now columnwise multiply the emission prob
for col in xrange(K):
## 因为还需要乘以b_{jO_{t+1}},而3*3矩阵第二维即表示转移的j
┆ Xi[:,col,t] *= normPDF(trainSet[:,t],MU[:,col],SIGMA[col])
第二个问题:学习问题,给出观测序列 O O O,估计模型参数 λ = ( π , A , B ) \lambda =(\pi,A,B) λ=(π,A,B),使得 P ( O ∣ λ ) P(O|\lambda) P(O∣λ) 最大,显然用MLE的方式来估计。
监督学习
若训练数据包括观测序列和状态序列,则 H M M HMM HMM 的学习非常简单,是监督学习。利用大数定理的结论 “频率的极限是概率”,给出 H M M HMM HMM 的参数估计。
- 初始概率
- 转移概率
- 观测概率
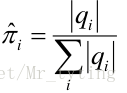
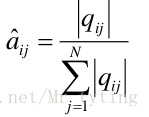
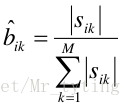
有监督式的学习比较简单,就是统计每个句子里的每个词的状态而已,大概的讲下思路:
- 获取已经分词好的语料库,类似这样
1986年 , 十亿 中华 儿女 踏上 新 的 征 程 。 过去 的 一 年 , 是 全国 各族 人民 在 中国 共产党 领导 下 , 在 建设 有 中国 特色 的 社会主义 道路 上 , 坚持 改革 、 开放 , 团结 奋斗 、 胜利 前进 的 一 年 。 - 每个词即为一个观测状态,再定义词的隐状态,例如参考代码中的 B(开头),M(中间), E(结尾), S(独立成词)作为四种隐状态,则可得到语料库中每句话的隐状态序列。由隐状态序列求得 转移概率。
- π \pi π 为初始状态,可从语料库中每句开头第一个词对应的隐状态得出
- 由语料库中每个隐状态对应的词得出 观测概率
- 由此可以从语料库中学习到参数矩阵 ( π , A , B ) (\pi,A,B) (π,A,B),然后可以利用学习到的参数矩阵,对要预测的句子进行分词(Viterbi算法),可根据预测得到的每个词隐状态,决定是否进行分词。
循环遍历语料库中每个句子,统计句子中每个词的隐状态(已经定义好每个词对应的隐状态)。得到该句的 l i n e _ s t a t e line\_state line_state 隐状态列表。
for i in range(len(line_state)):## 不同的句子,其line_state不同,可以理解为不同的时刻
if i == 0:
┆ Pi_dic[line_state[0]] += 1## 该句第一个词的隐状态
┆ Count_dic[line_state[0]] += 1## 后面做归一化用的
else:
┆ A_dic[line_state[i-1]][line_state[i]] += 1## 统计转移概率
┆ Count_dic[line_state[i]] += 1
## 统计发射概率,第i个隐状态对应第i个观测状态
┆ if not B_dic[line_state[i]].has_key(word_list[i]):
┆ ┆ B_dic[line_state[i]][word_list[i]] = 0.0
┆ else:
┆ ┆ B_dic[line_state[i]][word_list[i]] += 1
这样统计完语料库中的每个句子后,做完归一化后得到最终的 π 、 A 、 B \pi、A、B π、A、B 。
无监督学习(Baum-Welch算法)
若训练数据只有观测序列,则
H
M
M
HMM
HMM 的学习,需要使用
E
M
EM
EM 算法,是非监督学习。
E
M
EM
EM 算法整体框架:
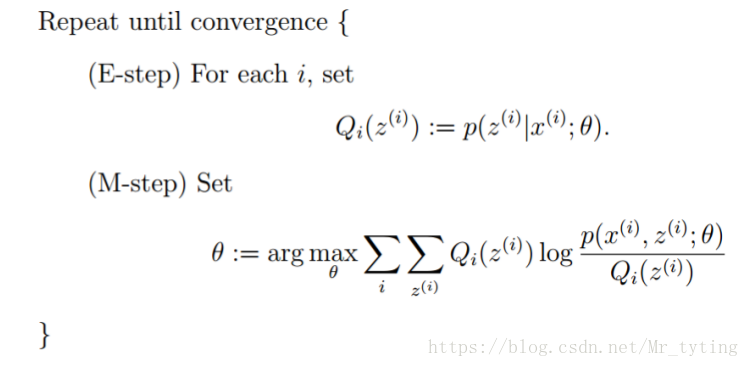
所有观测数据写成 O = ( o 1 , o 2 . . . o T ) O=(o_1 ,o_ 2 ...o_T ) O=(o1,o2...oT),所有隐数据写成 I = ( i 1 , i 2 . . . i T ) I=(i_1 ,i_2 ...i_T ) I=(i1,i2...iT),完全数据是 ( O , I ) = ( o 1 , o 2 . . . o T , i 1 , i 2 . . . i T ) (O,I)=(o_1 ,o_2 ...o_T ,i_1 ,i_2 ...i_T ) (O,I)=(o1,o2...oT,i1,i2...iT),完全数据的对数似然函数是 l n P ( O , I ∣ λ ) lnP(O,I|λ) lnP(O,I∣λ)。
在 H M M HMM HMM 中,上面公式中的 x x x 就是观测 O O O,隐随机变量就是隐状态 I I I。则其 E M EM EM 公式中的 Q Q Q 在 H M M HMM HMM 中为 p ( I ∣ o ) p(I|o) p(I∣o),这其实就是 E E E 步。
假设 λ ˉ \bar{\lambda} λˉ 是 H M M HMM HMM 参数的当前估计值(也就是上一轮中得出的最优的参数)
这个 E E E 步在代码中如何实现呢?实际上由后面的 M M M 步中为了得到 λ ( M U , S I G M A 、 转 移 矩 阵 A , π ) \lambda(MU, SIGMA、转移矩阵A,\pi) λ(MU,SIGMA、转移矩阵A,π) 需要先知道 γ 、 ε \gamma、\varepsilon γ、ε 的值,故在 E E E 步时先更新得到:
def Estep(trainSet, PI,A,MU,SIGMA):## PI,A,MU,SIGMA 为上一轮M步迭代更新出的\lambda
## 即在E步利用上一轮更新后的PI,A,MU,SIGMA来计算gamma等
# The goal of E step is to evaluate Gamma(Z_{n}) and Xi(Z_{n-1},Z_{n})
# First, create the forward and backward probability matrices
Alpha, c = buildAlpha(trainSet, PI,A,MU,SIGMA)
Beta = buildBeta(trainSet,c,PI,A,MU,SIGMA)
# Dimension of Gamma is equal to Alpha and Beta where nth column represents
# posterior density of nth latent variable. Each row represents a state
# value of all the latent variables. IOW, (i,j)th element represents
# p(Z_j = i | X,MU,SIGMA)
Gamma = Alpha*Beta
#pdb.set_trace()
# Xi is a KxKx(N-1) matrix (N is the length of data seq)
# Xi(:,:,t) = Xi(Z_{t-1},Z_{t})
N = np.size(trainSet,1)
K = np.size(PI,0)
Xi = np.zeros((K,K,N))
for t in xrange(1,N):
┆ Xi[:,:,t] = (1/c[t])*Alpha[:,t-1][None].T.dot(Beta[:,t][None])*A
┆ # Now columnwise multiply the emission prob
┆ for col in xrange(K):
┆ ┆ Xi[:,col,t] *= normPDF(trainSet[:,t],MU[:,col],SIGMA[col])
return Gamma, Xi, c
λ
λ
λ 为待求 的参数。则有:
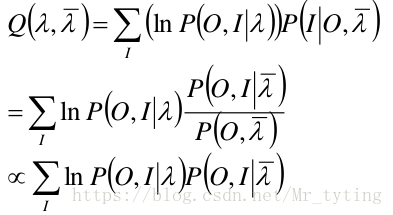
我们就是要最求上面 Q ( λ , λ ˉ ) Q(\lambda,\bar{\lambda}) Q(λ,λˉ) 取极值时对应的 λ \lambda λ ,其实就是 π 、 A 、 B \pi、A、B π、A、B,这就是 M M M 步。
根据上面的暴力计算的结论:
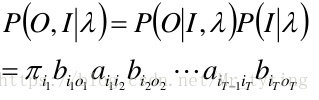
函数可写成:
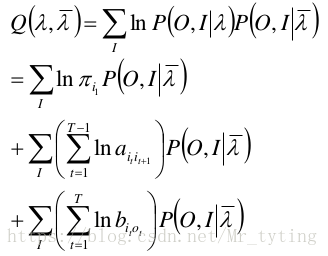
- 极大化
Q
Q
Q,获得
π
\pi
π 参数
注意到 π i \pi_i πi 加和为1,利用拉格朗日乘子法得:
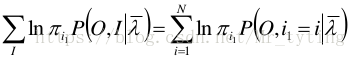
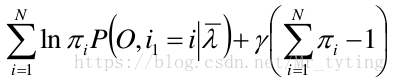
对上式中的
π
i
\pi_i
πi 求导,可得:
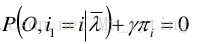
对
i
i
i 求和,得到:
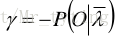
从而得到:
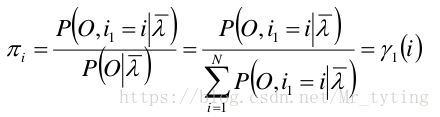
PI = (Gamma[:,0]/np.sum(Gamma[:,0]))[None].T
同理可以用拉格朗日乘子法求得:
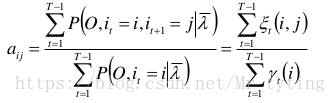
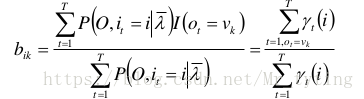
代码中是如何实现 M M M 步呢?
def Mstep(X, Gamma, Xi):
# Goal of M step is to calculate PI, A, MU, and SIGMA while treating
# Gamma and Xi as constant
K = np.size(Gamma,0)
d = np.size(X,0)
PI = (Gamma[:,0]/np.sum(Gamma[:,0]))[None].T
tempSum = np.sum(Xi[:,:,1:],axis=2)
A = tempSum/np.sum(tempSum,axis=1)[None].T ## 转移矩阵A
MU = np.zeros((d,K))
GamSUM = np.sum(Gamma,axis=1)[None].T
SIGMA = []
for k in xrange(K):
┆ MU[:,k] = np.sum(Gamma[k,:]*X,axis=1)/GamSUM[k]
┆ X_MU = X - MU[:,k][None].T
┆ SIGMA.append(X_MU.dot(((X_MU*(Gamma[k,:][None])).T))/GamSUM[k])
return PI,A,MU,SIGMA
问题三:预测算法
在每个时刻 t t t 选择在该时刻最有可能出现的状态 i t ∗ i_t^* it∗ ,从而得到一个状态序列 I ∗ = { i 1 ∗ , i 2 ∗ . . . i T ∗ } I^* =\{i_1^* , i_2^ *... i_T^* \} I∗={i1∗,i2∗...iT∗},将它作为预测的结果。
Viterbi算法
首先看看Viterbi 算法的厉害之处
如下图,假如你从S和E之间找一条最短的路径,除了遍历完所有路径,还有什么更好的方法?

答案:viterbi (维特比)算法。
过程非常简单:
为了找出S到E之间的最短路径,我们先从S开始从左到右一列一列地来看。
首先起点是S,从S到A列的路径有三种可能:S-A1、S-A2、S-A3,如下图:

我们不能武断地说S-A1、S-A2、S-A3中的哪一段必定是全局最短路径中的一部分,目前为止任何一段都有可能是全局最短路径的备选项。
我们继续往右看,到了B列。按B列的B1、B2、B3逐个分析。
先看B1:

如上图,经过B1的所有路径只有3条:
S-A1-B1
S-A2-B1
S-A3-B1
以上这三条路径,各节点距离加起来对比一下,我们就可以知道其中哪一条是最短的。假设S-A3-B1是最短的,那么我们就知道了经过B1的所有路径当中S-A3-B1是最短的,其它两条路径路径S-A1-B1和S-A2-B1都比S-A3-B1长,绝对不是目标答案,可以大胆地删掉了。删掉了不可能是答案的路径,就是viterbi算法(维特比算法)的重点,因为后面我们再也不用考虑这些被删掉的路径了。现在经过B1的所有路径只剩一条路径了,如下图:

接下来,我们继续看B2:

同理,如上图,经过B2的路径有3条:
S-A1-B2
S-A2-B2
S-A3-B2
这三条路径中,各节点距离加起来对比一下,我们肯定也可以知道其中哪一条是最短的,假设S-A1-B2是最短的,那么我们就知道了经过B2的所有路径当中S-A1-B2是最短的,其它两条路径路径S-A2-B2和S-A3-B1也可以删掉了。经过B2所有路径只剩一条,如下图:

接下来我们继续看B3:

同理,如上图,经过B3的路径也有3条:
S-A1-B3
S-A2-B3
S-A3-B3
这三条路径中我们也肯定可以算出其中哪一条是最短的,假设S-A2-B3是最短的,那么我们就知道了经过B3的所有路径当中S-A2-B3是最短的,其它两条路径路径S-A1-B3和S-A3-B3也可以删掉了。经过B3的所有路径只剩一条,如下图:

现在对于B列的所有节点我们都过了一遍,B列的每个节点我们都删除了一些不可能是答案的路径,看看我们剩下哪些备选的最短路径,如下图:

上图是我们删掉了其它不可能是最短路径的情况,留下了三个有可能是最短的路径:S-A3-B1、S-A1-B2、S-A2-B3。现在我们将这三条备选的路径放在一起汇总到下图:

S-A3-B1、S-A1-B2、S-A2-B3都有可能是全局的最短路径的备选路径,我们还没有足够的信息判断哪一条一定是全局最短路径的子路径。
如果我们你认为没毛病就继续往下看C列,如果不理解,回头再看一遍,前面的步骤决定你是否能看懂viterbi算法(维特比算法)。
接下来讲到C列了,类似上面说的B列,我们从C1、C2、C3一个个节点分析。
经过C1节点的路径有:
S-A3-B1-C1、
S-A1-B2-C1、
S-A2-B3-C1

同理,我们可以找到经过C2和C3节点的最短路径,汇总一下:

到达C列时最终也只剩3条备选的最短路径,我们仍然没有足够信息断定哪条才是全局最短。
最后,我们继续看E节点,才能得出最后的结论。
到E的路径也只有3种可能性:

E点已经是终点了,我们稍微对比一下这三条路径的总长度就能知道哪条是最短路径了。

在效率方面相对于粗暴地遍历所有路径,viterbi 维特比算法到达每一列的时候都会删除不符合最短路径要求的路径,大大降低时间复杂度。
以上例子参考自 如何通俗地讲解 viterbi 算法?
强烈建议去读下源文,写的太好了
Viterbi算法在HMM中
V i t e r b i Viterbi Viterbi 算法实际是用 动态规划 解 H M M HMM HMM 预测问题,用 D P DP DP 求概率最大的路径(最优路径),这是一条路径对应一个状态序列。其实就是我们知道了模型参数 λ \lambda λ 后,从时刻 1 1 1 递推到时刻 T T T 的最大概率路径。
定义变量 δ t ( i ) δ_t (i) δt(i):在时刻 t t t 状态为 i i i 的所有路径中,概率的最大值。
- 递推
- 终止
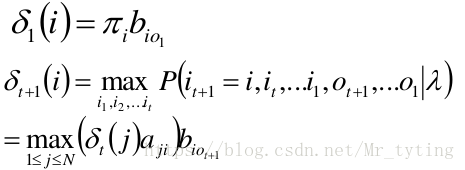
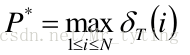
那么在代码中时如何实现 V i t e r b i Viterbi Viterbi 算法呢?
def viterbi(obs, states, start_p, trans_p, emit_p):
"""
obs: 需要切分的sentence
states: 状态种类序列,例如每个词可能有四个状态[B, M, E, S]
start_p: 就是上面所讲的\PI
trans_p: 状态转移矩阵
emit_p: 发射矩阵
"""
V = [{}] #tabular V[t][state]:t表示时刻,state表示该时刻的隐状态
path = {}
for y in states: #init
## emit_p[y].get(obs[0],0)表示在y隐状态下,观测状态为obs[0] 的发射概率。
## 在t=0 时刻时,观测状态即为obs[0]
┆ V[0][y] = start_p[y] * emit_p[y].get(obs[0],0)
┆ path[y] = [y] ## 记录当前的状态路径
for t in range(1,len(obs)):
┆ V.append({})
┆ newpath = {}
┆ for y in states:
## 在t时刻时,遍历t-1时刻所有可能的隐状态state与当前y隐状态的连接概率,获取最大时对于的state和对应的概率prob
┆ ┆ (prob,state ) = max([(V[t-1][y0] * trans_p[y0].get(y,0) * emit_p[y].get(obs[t],0) ,y0) for y0 in states if V[t-1][y0]>0])
┆ ┆ V[t][y] =prob## 将最大概率prob作为V[t][y]
┆ ┆ newpath[y] = path[state] + [y]## path[state] 表示t-1时刻最大概率对应的隐状态序列,再加上当前时刻的y
┆ path = newpath
## 取最后概率最大的对应的序列作为最后结果。
(prob, state) = max([(V[len(obs) - 1][y], y) for y in states])
return (prob, path[state])
def cut(sentence):
#pdb.set_trace()
prob, pos_list = viterbi(sentence,('B','M','E','S'), prob_start, prob_trans, prob_emit)
return (prob,pos_list)
V i t e r b i Viterbi Viterbi 算法其实就是多步骤、每步多选择模型的最优选择问题,其在每一步的所有选择都保存了从第一步到当前步的的最小或最大代价,以及当前情况下前进步骤的选择。并且记下在每一步每一个隐状态与上一步对应代价最小的隐状态节点,如果有 n n n 个隐状态,就形成 n n n 个不同的链路,并且保证了每个节点对应的链路都是该节点的最小代价。
HMM缺点
- 由hmm过程可知(转移矩阵和发射矩阵是分开独立model的),hmm可能会生成训练集中从未出现过得样本,这也导致了可能训练集中有明确的样本,但是hmm预测结果却不是训练集中的结果。这对于训练集样本数量较少时有好处,但是训练集样本很多时表现可能会差。
- hmm生成的结果不一定最优,这与上面一点原因类似。
个人总结
- 问题建模:
F ( x , y ) = P ( x , y ) = P ( x ) P ( X ∣ y ) F(x,y) = P(x,y)=P(x)P(X|y) F(x,y)=P(x,y)=P(x)P(X∣y)注意是联合概率建模
- 模型推断:
y ^ = a r g m a x y ∈ Y P ( x , y ) \hat{y} = argmax_{y \in Y}P(x, y) y^=argmaxy∈YP(x,y) - 参数估计
P ( x ) P(x) P(x)即状态转移概率, p ( X ∣ y ) p(X|y) p(X∣y) 即发射矩阵,有监督时可以从训练数据中很容易统计出
我个人觉得前向、后向计算、 V i t e r b i Viterbi Viterbi 算法、 B e a m S e a r c h BeamSearch BeamSearch 这几个算法有几分相似,又有几分区别之处,值得思考一下:
- 前向、后向计算是利用动态规划的思想,每一步的计算都是在前一步计算结果的基础上,大大降低了计算量。
- V i t e r b i Viterbi Viterbi 算法 同样也是利用了动态规划的思想,能保证找到最优的路径。
- B e a m S e a r c h BeamSearch BeamSearch 利用的是贪心的思想,每一步只能找到当前时刻最优的 B e a m S i z e BeamSize BeamSize 个不同的 t o k e n token token,而只是在当前时刻最优,却不能保证整体最优,故 b e a m S e a r c h beamSearch beamSearch最后结果可能不是最优结果。那么有人可能会问,为啥 B e a m S e a r c h BeamSearch BeamSearch 不用 V i t e r b i Viterbi Viterbi 的那种动态规划的思想,而用贪心?这个问题其实很简单,试想一下,在 V i t e r b i Viterbi Viterbi 中,最后一个时刻每个状态都有对应的最优链路,因此我们可以找到最优的,而在 B e a m S e a r c h BeamSearch BeamSearch 中呢,你不可能在最后一步遍历所有的隐状态(词表一般很大),你只能采取贪心的方式每一步选择当前最优的 B e a m S i z e BeamSize BeamSize 个状态。














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









