






在深度学习领域,Transformer架构凭借其独特的注意力机制,成为理解和处理复杂数据的重要工具。该机制使得模型能够有效地理解上下文理解,显著提升对输入数据的解析能力,尤其在处理超长文本时展现出卓越性能。
然而,随着输入规模的不断扩大,Transformer的计算开销和复杂度也随之增加。这要求设计者在模型中平衡计算效率与表现,特别是在捕捉复杂依赖关系时,如何优化计算成为关键。
虽然传统的循环神经网络(RNN)和卷积神经网络(CNN)在某些任务中表现良好,但在面对大规模数据时,计算效率常常不足。因此,研究者们开始探索更为高效计算的方法,尤其是结合线性可扩展性的思想,以提升Transformer模型的计算效率。
Mamba等新兴技术的引入,为Transformer提供了新的选择机制,使其能够在运行时进行动态重新参数化,有效滤除不相关信息,优化计算资源的使用。这些技术的应用不仅提升了Transformer的计算速度,还推动了硬件感知型算法的开发。
为了全面了解Mamba新兴技术的引入,我们总结了关于Mamba模型的四种变体的相关文献。
论文1
HRVMAMBA: HIGH-RESOLUTION VISUAL STATE SPACE MODEL FOR DENSE PREDICTION
方法:
我们引入了动态视觉状态空间(DVSS)块,它利用多尺度卷积核来提取不同尺度的局部特征并增强归纳偏差,并采用可变形卷积来减轻长程偏差用于在基于输入和特定于任务的信息启用自适应空间聚合的同时解决问题。通过利用 HRNet 中提出的多分辨率并行设计,我们引入了基于 DVSS 块的高分辨率视觉状态空间模型,该模型在整个过程中保留了高分辨率表示同时促进有效的多尺度特征学习。

创新点:
(1)我们引入了 DVSS 块,它集成了多尺度卷积核和可变形卷积,以减轻 VSS 块中缺乏归纳偏差和长程遗忘的问题。
(2)我们提出基于 DVSS 块的 HRVMamba,作为第一个应用于多分辨率分支结构的基于 Mamba 的模型,旨在保留细粒度的细节和专门针对密集预测任务捕获多尺度变化。
(3)HRVMamba 在图像分类、人体姿势估计和语义分割任务中展示了良好的性能。实验结果表明HRVMamba与现有的 CNN、ViT 和 SSM 基准模型相比,取得了具有竞争力的结果。
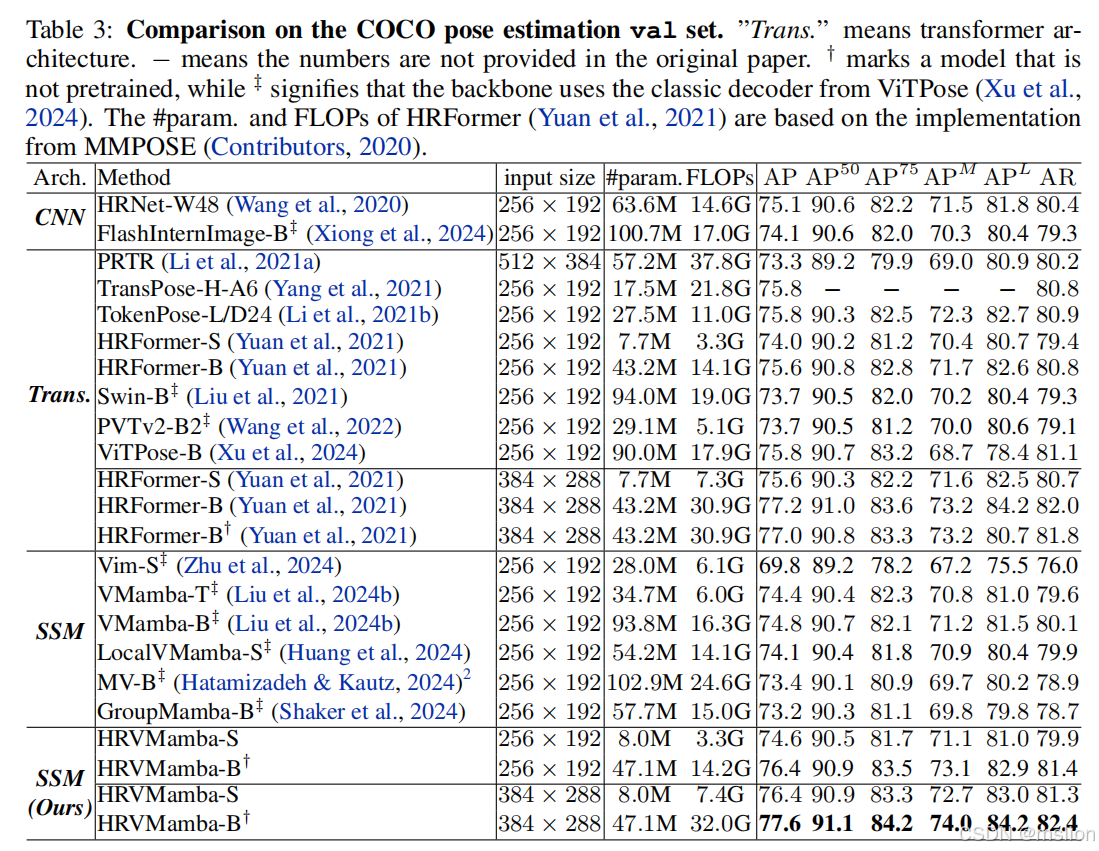
结果:
论文2
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
方法:
首先,简单地让 SSM 参数作为输入的函数,可以解决其离散模态的弱点,允许模型根据当前标记选择性地沿序列长度维度传播或忘记信息。其次,尽管这种变化阻止了高效卷积的使用,但我们在循环模式下设计了一种硬件感知的并行算法。我们将这些选择性 SSM 集成到简化的端到端神经网络架构中,无需注意力机制,甚至不需要 MLP 模块 (Mamba)。Mamba 享有快速推理(吞吐量比 Transformer 高 5 倍)和序列长度线性缩放,并且其性能在高达百万长度序列的实际数据上得到提高。
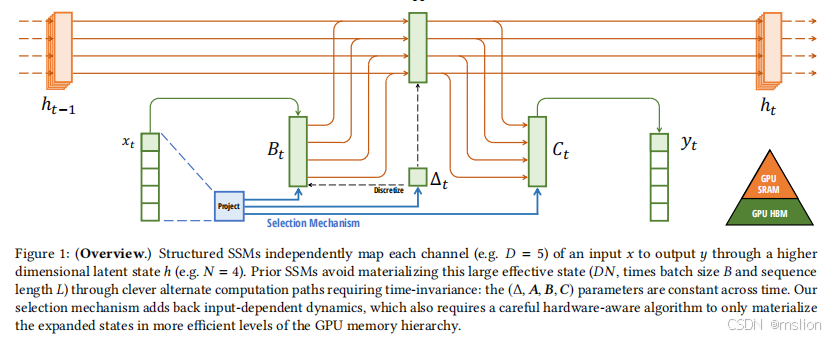
创新点:
(1)合成材料。在重要的合成任务上,例如复制和归纳头,这些任务被认为是大型语言模型的关键,Mamba 不仅可以轻松解决它们,而且可以无限期地推断解决方案(> 1M 个令牌)。
(2)音频和基因组学。在音频波形和 DNA 序列建模方面,Mamba 在预训练质量和下游指标方面均优于 SaShiMi、Hyena 和 Transformers 等之前最先进的模型(例如,将具有挑战性的语音生成数据集上的 FID 减少一半以上)。在这两种设置中,随着上下文长度达到百万长度的序列,其性能都会得到提高。
(3)语言建模。Mamba 是第一个真正实现 Transformer 质量性能的线性时间序列模型,无论是在预训练困惑度还是下游评估方面。通过高达 1B 参数的缩放法则,我们证明 Mamba 的性能超过了大范围基线,包括基于 LLaMa 的非常强大的现代 Transformer 训练方法(Touvron 等人,2023)。与类似大小的 Transformer 相比,我们的 Mamba 语言模型的生成吞吐量是其 5 倍,Mamba-3B 的质量与两倍大小的 Transformer 相当(例如,与 Pythia-3B 相比,常识推理平均高出 4 分,甚至超过 Pythia-7B )。
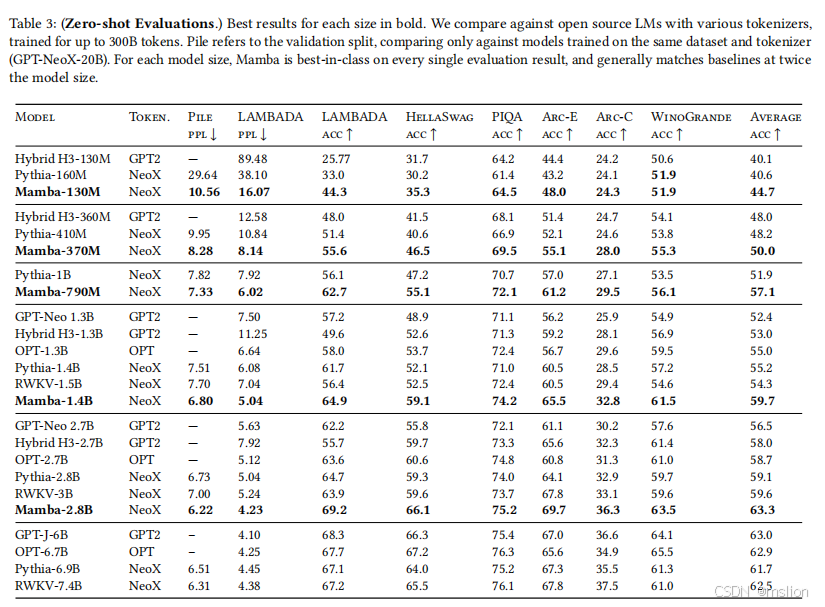
结果:
论文3
VL-Mamba: Exploring State Space Models for Multimodal Learning
方法:
我们提出了VL-Mamba,一种基于状态空间模型的多模态大语言模型,它已被证明在具有快速推理和序列长度线性缩放的长序列建模方面具有巨大潜力。具体来说,我们首先用预先训练的 Mamba 语言模型替换基于 Transformer 的主干语言模型(例如 LLama 或 Vicuna)。然后,我们实证探索如何有效地将 2D 视觉选择性扫描机制应用于多模态学习以及不同视觉编码器和预训练 Mamba 语言模型变体的组合。

创新点:
(1)我们提出了VL-Mamba,这是第一个探索和利用状态空间模型来解决多模态学习任务的工作,它为除基于变压器的架构之外的多模态大语言模型提供了一种新颖的框架选项。
(2)我们凭经验探索了不同组件对VL-Mamba 的影响,并引入了一种新颖的多模式连接器,其中包含视觉选择性扫描(VSS)模块,以提高表征能力。
(3)我们对不同的多模式学习基准进行了广泛的实验。实验表明,与现有的多模态大语言模型相比,VL-Mamba 实现了具有竞争力的性能。
(4)我们将代码开源,以促进应用状态空间模型进行多模态学习的研究。
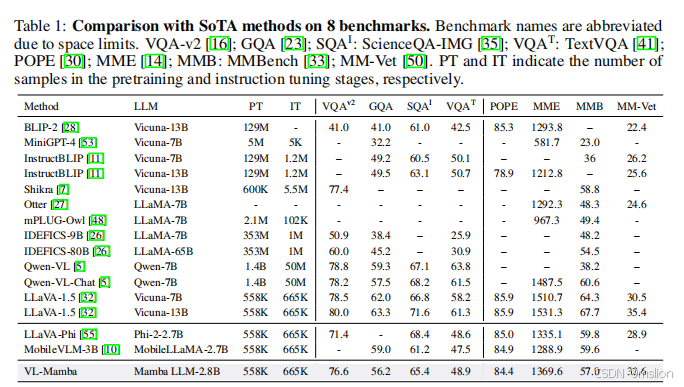
结果:
论文4
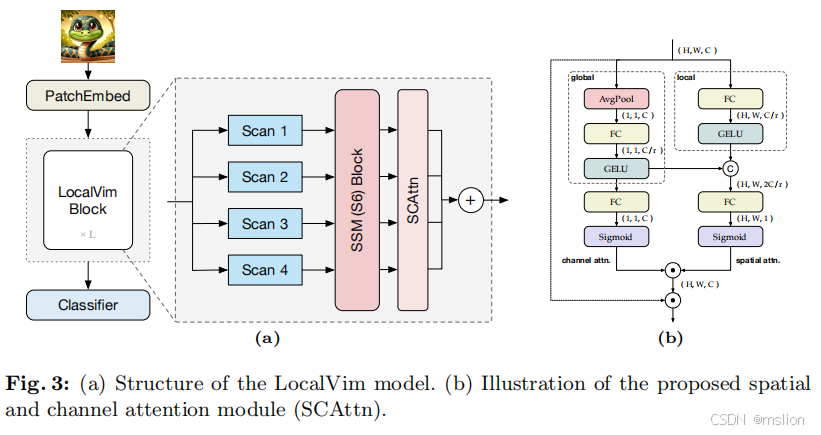
LocalMamba: Visual State Space Model with Windowed Selective Scan
方法:
我们引入了一种新颖的局部扫描策略,将图像划分为不同的窗口,有效捕获局部依赖性,同时保持全局视角。此外,考虑到不同网络层对扫描模式的不同偏好,我们提出了一种动态方法来独立搜索每层的最佳扫描选择,从而显着提高性能。
创新点:
(1)我们引入了一种新颖的 SSM 扫描方法,其中包括本地化在不同的窗口内进行扫描,显着增强我们模型的能力结合全球背景捕获详细的本地信息。
(2)我们开发了一种跨不同网络层搜索扫描方向的方法,使我们能够识别并应用最有效的扫描组合,从而提高网络性能。
(3)我们提出了两种模型变体,采用简单结构和分层结构设计。通过对图像分类、目标检测和语义分割任务的广泛实验,我们证明了我们的模型与以前的作品相比取得了显着的改进。例如,在语义分割任务中,在参数数量相似的情况下,我们的 LocalVim S 在 mIoU (SS) 上的表现远远优于 Vim-S 1.5。
结果:

















 2331
2331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









