







 超级会员免费看
超级会员免费看
本文介绍:本专栏文章不会讲太复杂的定义,将从小白的角度去进行讲解,为大家节省时间,高效去做实验,文章将会简单介绍一下相关模块(也会附带相关论文链接,有兴趣可以阅读,可以作为论文文献),本专栏主要专注于YOLO改进实战!适用于小白入门也可以水论文,大佬跳过!!!
文章适用人群:研一、准研究生(研0)、少部分本科生、着急毕业水论文的各位
更新时间:每天1~3篇左右,本专栏文章至少50+篇,如果需要单独设计可以联系我,咨询一下
售后:购买专栏后在运行时有问题直接私聊我,大部分都是环境配置问题,我会录教程带大家配置,保证代码畅通无阻!
新专栏福利:帮助入门小白缝合模块,创新模块(先到先得,名额有限,论文从此不缺创新点)!
专栏通知:专栏文章大于20篇时将涨价,早买有优惠,感谢各位读者支持!(更新时间:2024/12/01)
目录
一、将主角“ECA注意力机制”加入到YOLO大家庭(代码)中
“ECA注意力机制”同学简介
个人简介:大家好!我是 ECA 注意力机制。我就像个超酷的信息导航员,在数据的海洋里,能迅速锁定关键信息,给重要的特征戴上“聚光灯”,让它们闪亮登场,把那些无关紧要的“小透明”信息往后放放,从而帮神经网络这个大团队把活儿干得更漂亮、更高效!
一、将主角“ECA注意力机制”加入到YOLO大家庭(代码)中
ECA代码展示:
#-------------------ECA---------------------#
from torch.nn import init
# 定义ECA注意力模块的类
class ECAAttention(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
self.gap = nn.AdaptiveAvgPool2d(1) # 定义全局平均池化层,将空间维度压缩为1x1
# 定义一个1D卷积,用于处理通道间的关系,核大小可调,padding保证输出通道数不变
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2)
self.sigmoid = nn.Sigmoid() # Sigmoid函数,用于激活最终的注意力权重
# 权重初始化方法
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out') # 对Conv2d层使用Kaiming初始化
if m.bias is not None:
init.constant_(m.bias, 0) # 如果有偏置项,则初始化为0
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1) # 批归一化层权重初始化为1
init.constant_(m.bias, 0) # 批归一化层偏置初始化为0
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001) # 全连接层权重使用正态分布初始化
if m.bias is not None:
init.constant_(m.bias, 0) # 全连接层偏置初始化为0
# 前向传播方法
def forward(self, x):
y = self.gap(x) # 对输入x应用全局平均池化,得到bs,c,1,1维度的输出
y = y.squeeze(-1).permute(0, 2, 1) # 移除最后一个维度并转置,为1D卷积准备,变为bs,1,c
y = self.conv(y) # 对转置后的y应用1D卷积,得到bs,1,c维度的输出
y = self.sigmoid(y) # 应用Sigmoid函数激活,得到最终的注意力权重
y = y.permute(0, 2, 1).unsqueeze(-1) # 再次转置并增加一个维度,以匹配原始输入x的维度
return x * y.expand_as(x) # 将注意力权重应用到原始输入x上,通过广播机制扩展维度并执行逐元素乘法
使用步骤:
- 找到并打开“YOLOv8\ultralytics-main\ultralytics\nn\modules\block.py”文件,在箭头位置添加ECA模块,如图1
- 复制上面提供的ECA代码粘贴进block.py的64行(你们的不一定是56行,注意附近内容),如图2
- 在包结构中导入ECA类,注意看,这步最容易错,图中有详解,如图3和图4
- 找到task.py导入你的新模块,task.py位置和模块导入方法,如图5
- 编写parse_model函数,首先你需要按住Ctrl和F,搜索def parse_model并跳转到这个函数的定义,然后开始往下滑找到如图6所示的位置(行数不一定相同,注意周围内容),并且在图示位置比着图6添加相关内容(直接复制粘贴下面代码块的内容到图中位置)
#----------------------ECA---------------------------#
elif m is ECAAttention:
c1 = ch[f]图示教程:
 图1(上图)
图1(上图)
 图2(上图)
图2(上图)
 图3(上图)
图3(上图)
 图4(上图)
图4(上图)
 图5(上图)
图5(上图)
 图6(上图)
图6(上图)
二、模型文件中加入ECA注意力机制
步骤:
- 如图7所示,在相应位置创建ADD文件夹(用于存放新建的模型文件)和yolov11-ECA.yaml模型文件
- 复制下面yolov11-ECA.yaml文件内容到新建的yolov11-ECA.yaml文件中并保存。
 图7(上图)
图7(上图)
yolov8-CoTAttention.yaml文件内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, ECAAttention, []] # 0-P1/2
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 7], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
三、直接开跑
步骤:
- 运行train.py出现如图8所示即为运行成功
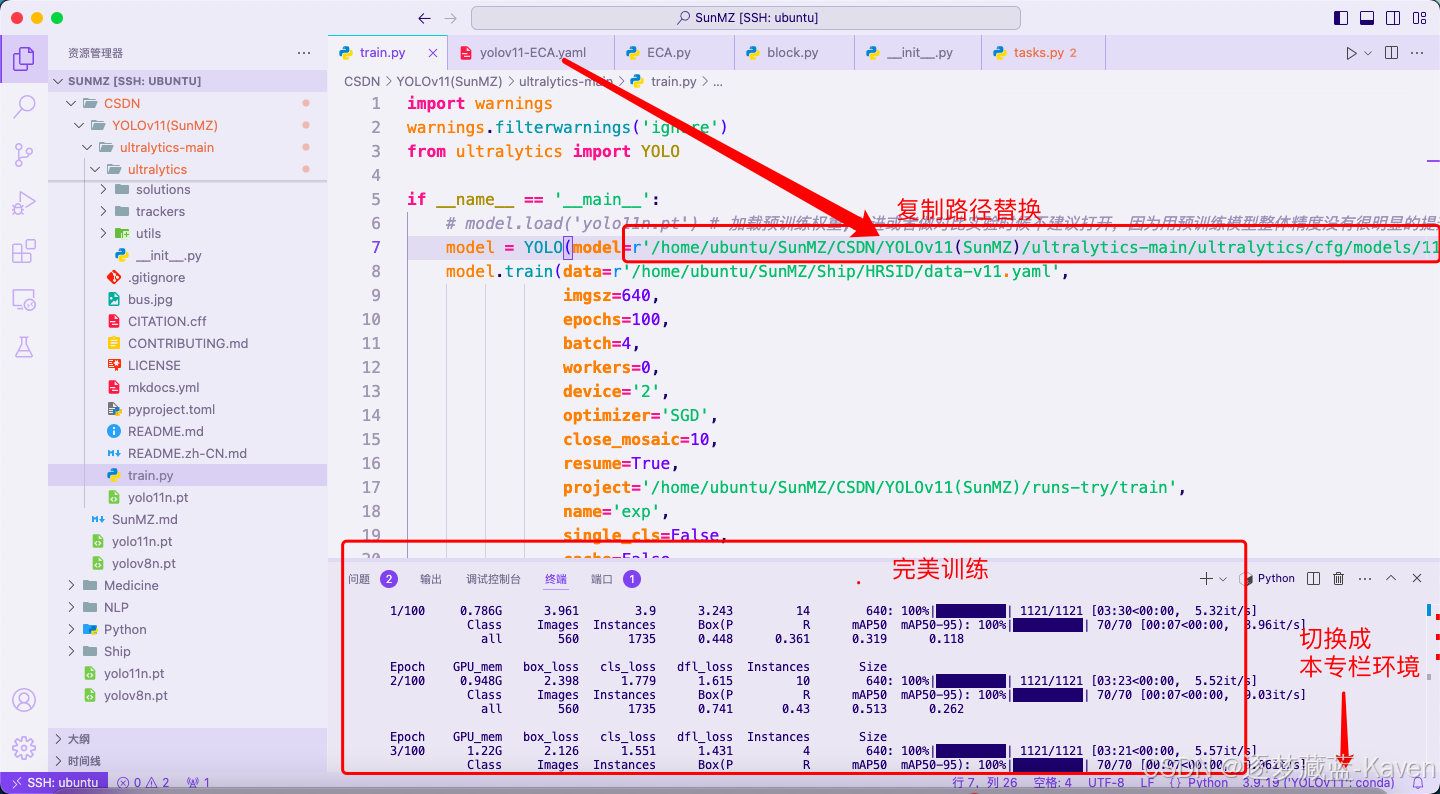 图8(上图)
图8(上图)
四、附赠ECA(改进版)效果好可做创新点
代码如下所示:(添加方式与上面相同也可直接将源代码替换不需要额外操作,不会的私信我!)
#-----------------------ECA(改进)--------------------------#
import torch
from torch import nn
from torch.nn import init
import torch.nn.functional as F
# 定义多尺度融合的ECA注意力模块的类
class MSECAAttention(nn.Module):
def __init__(self, kernel_sizes=[3, 5, 7]):
super().__init__()
self.gap = nn.AdaptiveAvgPool2d(1) # 定义全局平均池化层,将空间维度压缩为1x1
# 定义多个不同核大小的1D卷积,用于处理不同尺度通道间的关系
self.convs = nn.ModuleList([nn.Conv1d(1, 1, kernel_size=k, padding=(k - 1) // 2) for k in kernel_sizes])
self.sigmoid = nn.Sigmoid() # Sigmoid函数,用于激活最终的注意力权重
# 权重初始化方法
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out') # 对Conv2d层使用Kaiming初始化
if m.bias is not None:
init.constant_(m.bias, 0) # 如果有偏置项,则初始化为0
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1) # 批归一化层权重初始化为1
init.constant_(m.bias, 0) # 批归一化层偏置初始化为0
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001) # 全连接层权重使用正态分布初始化
if m.bias is not None:
init.constant_(m.bias, 0) # 全连接层偏置初始化为0
# 前向传播方法
def forward(self, x):
y = self.gap(x) # 对输入x应用全局平均池化,得到bs,c,1,1维度的输出
y = y.squeeze(-1).permute(0, 2, 1) # 移除最后一个维度并转置,为1D卷积准备,变为bs,1,c
# 分别应用不同核大小的1D卷积并存储结果
scale_results = []
for conv in self.convs:
scale_y = conv(y)
scale_results.append(scale_y)
# 融合多尺度结果
y = sum(scale_results) / len(scale_results)
y = self.sigmoid(y) # 应用Sigmoid函数激活,得到最终的注意力权重
y = y.permute(0, 2, 1).unsqueeze(-1) # 再次转置并增加一个维度,以匹配原始输入x的维度
return x * y.expand_as(x) # 将注意力权重应用到原始输入x上,通过广播机制扩展维度并执行逐元素乘法
总结
改进后的ECA模块:
一、多维度信息交互创新
- 跨尺度通道交互:MSECA 模块首次在 ECA 框架内引入多尺度通道交互机制。传统 ECA 局限于单一尺度的通道注意力计算,而本模块通过不同核大小卷积并行处理,实现了跨尺度的通道信息交流与整合,能捕捉到从细粒度到粗粒度多层面的通道依赖关系,极大丰富了特征表达的维度与深度。
- 空间 - 通道协同优化:在多尺度处理过程中,间接促进了空间与通道信息的协同优化。不同尺度的卷积操作对空间信息有不同程度的聚合与抽象,与通道信息的融合使模型能同时从空间分布和通道语义两个维度精准定位关键信息,提升整体特征表示的准确性与完整性。
二、动态适应性增强
- 数据自适应尺度调整:MSECA 模块具备根据输入数据自动调整尺度关注重点的能力。在不同数据分布下,多尺度卷积输出的相对重要性会动态变化,融合策略能自适应地捕捉这种变化并合理分配权重,使模型对各类数据特征的适应性显著提高,减少了因数据差异导致的性能波动。
- 任务驱动的参数微调:针对不同任务需求,MSECA 模块的多尺度参数(如核大小组合)可进行灵活微调。这种任务驱动的适应性调整能够确保模块在不同应用场景下(如图像分类、目标检测等)都能以最优的参数配置聚焦关键信息,提升模型在复杂任务体系下的通用性与性能表现。

















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









