







1:nuScenes数据集

https://zhuanlan.zhihu.com/p/295549692

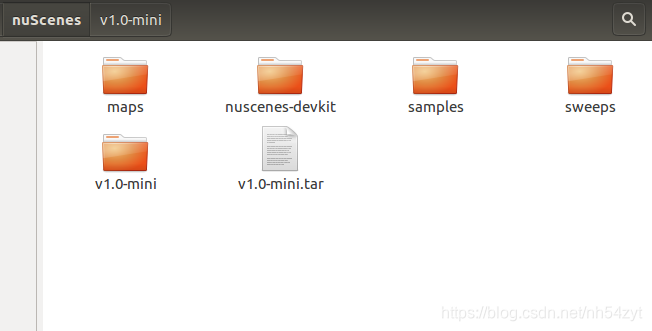
点云数据集

针对cuda10.0 spconv版本
安装cu100版本
torch-1.3.0+cu100-cp37-cp37m-linux_x86_64.whl
torchvision-0.4.1+cu100-cp37-cp37m-linux_x86_64.whl
2:Culane数据集
CULane由安装在六辆由北京不同驾驶员驾驶的不同车辆上的摄像机收集。收集了超过55小时的视频,并提取了133,235帧。数据示例如上所示。我们将数据集分为88880个训练集,9675个验证集和34680个测试集。测试集分为正常和8个挑战性类别,分别对应于上述9个示例。
https://zhuanlan.zhihu.com/p/295549692
如果使用百度云,请确保driver_23_30frame_part1.tar.gz 和 driver_23_30frame_part2.tar.gz中的图像解压缩后位于一个文件夹“ driver_23_30frame”中,而不是两个单独的文件夹中。
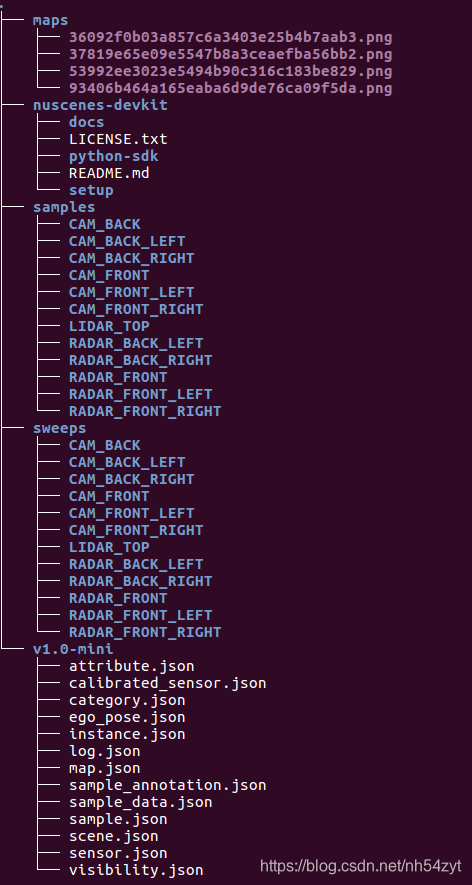
数据集文件夹应包括:
1.培训与验证的图像和注释:
- driver_23_30frame.tar.gz
- driver_161_90frame.tar.gz
- driver_182_30frame.tar.gz 对于每个图像,将有一个.txt注释文件,其中每个行给出车道标记关键点的x,y坐标。
2.测试图像和注释:
- driver_37_30frame.tar.gz
- driver_100_30frame.tar.gz
- driver_193_90frame.tar.gz
3.培训/认证/检测列表:
- list.tar.gz 对于用于训练的train_gt.txt,每行的格式为“输入图像,每个像素的标签,四个0/1数字,指示从左到右存在四个车道标记”。
- Train&val的车道分段标签:
-laneseg_label_w16.tar.gz ,它是从原始注释生成的。注意: training&val集的原始注释(不是分段标签)在2018年4月16日之前不正确。要更新到正确的版本,您可以下载“
annotations_new.tar.gz”并覆盖原始注释文件或下载training&val集再次。
可视化:
import os
import numpy as np
import sys
sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')
import cv2 as cv
root_name = "/home/laneseg_label_w16/driver_23_30frame/05151640_0419.MP4"
img_root_name = "/home/driver_23_30frame/05151640_0419.MP4"
img_path = os.listdir(root_name)
print('img_path:',img_path)
for i in img_path:
if os.path.splitext(i)[1]==".png":
print (i)
img = cv.imread(root_name +"/"+ i)
for x in range(img.shape[0]):
for y in range(img.shape[1]):
px = img[x,y]
#print(px)
if px[0] == 2:
img[x,y] = 200
cv.imshow("vis",img)
img = cv.imread(img_root_name +"/"+ i.split('.')[0]+'.jpg')
cv.imshow("vis_img",img)
cv.waitKey(0)
CULane训练的文件结构:
包括存放 车道线关键点的txt;
车道线图片和车道小label1的图片以及对应txt路径
├── annotations_new
│ ├── driver_161_90frame
│ ├── driver_182_30frame
│ └── driver_23_30frame
├── laneseg_label_w16
│ ├── driver_161_90frame
│ ├── driver_182_30frame
│ └── driver_23_30frame
├── laneseg_label_w16_test
│ ├── driver_100_30frame
│ ├── driver_193_90frame
│ └── driver_37_30frame
├── list
│ ├── test_split
│ ├── test.txt
│ ├── train_gt.txt
│ ├── train.txt
│ ├── val_gt.txt
│ └── val.txt
├── show_lane.py
├── test_set
│ ├── driver_100_30frame
│ ├── driver_193_90frame
│ └── driver_37_30frame
└── train_set
├── driver_161_90frame
├── driver_182_30frame
└── driver_23_30frame
3:Camera摄像头
焦距选择,
2.8mm到16mm情况
轨道用12ms
双目6mm,25mm

内参和小孔成像:
https://blog.csdn.net/weixin_41977337/article/details/111941234

估算理论相机内参方法:
通俗的讲像元就是每张图片的最小构成单元,就是一幅图像中每个小像素格,每个像素格均为正方形因此可以理解为像元的长宽是一样的;
(像元尺寸)=(传感器的高度)/(最大像素高度)=(传感器的宽度)/(最大像素宽度)
注:传感器的高度和宽度是定值 相机确定好了就不会改变;
但是图像的像素值是可以改变的,选用最大像素值就是选用没有更改的图片的像素值,即这个情况下的像素宽高比和相机传感器的宽高比是一定的,最后在高度方向算出的像元尺寸是一致的,符合理论。如果选用不同的像素值来计算可能造成宽高比不一致 ,计算出的像元尺寸不符合。
像元的物理尺寸大小:d x =F w/W , dy =Fh / H ;
像素为单位的主点坐标:u0 =X/dx , v0 =Y /dy ;
内参参数包括:
针孔相机模型的内参包含6个(f,κ,fx,fy,u0,v0);
f 为相机的焦距,单位一般是mm。
fx = f/dx, fy = f/dy,分别称为x轴和y轴上的归一化焦距。
一个像素的实际物理尺寸在x方向和y方向分别为dx和dy,dx,dy 为像元尺寸。
dx和dy表示x方向和y方向的一个像素分别占多少个单位,是反映现实中的图像物理坐标关系与像素坐标系转换的关键(可以理解为像元密度)。
(u0,v0 )为图像中心,u0,v0表示图像的中心像素坐标和图像原点像素坐标之间相差的横向和纵向像素数偏移量(以像素为单位)。
为了不失一般性,在相机的内参矩阵中,添加一个扭曲参数,在图像物理坐标系中的扭曲因子为。对于大多数标准相机,该扭曲参数为0。
k:表示径向畸变量级,如果k为负值,畸变为桶型畸变,如果为正值,那畸变为枕型畸变,初始值为0。

fx fy
估算方法:

内参标定方法:
https://www.cnblogs.com/wangguchangqing/p/8335131.html
正常情况,单应性矩阵求解:
这样一组匹配点对p1和p2就可以构造出两项约束,于是自由度为 8 的单应矩阵可以通过 4 对匹配点算出组
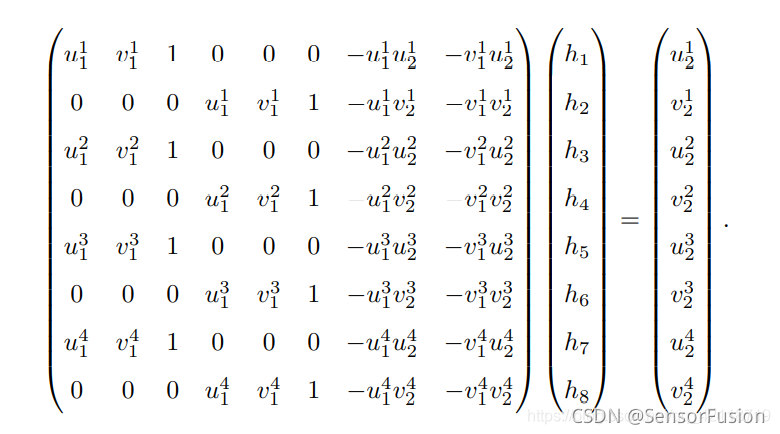
上述方程组采用直接线性解法通常很难得到最优解,
初值基础上进行非线性优化:

所以实际使用中一般会用其他优化方法,如奇异值分解、Levenberg-Marquarat(LM)算法等进行求解。

那么张正友标定:
上面我们推导的单应性矩阵是在相机运动的情况下进行的,但是相机标定的过程中相机是静止的,而运动的棋盘格标定板。在张正友标定中,用于标定的棋盘格是三维场景中的一个平面P,其在成像平面的像是另一个平面p,
单应性矩阵就是指两个平面之间的映射关系,
准确的来说是世界坐标系和像素坐标系之间的映射关系。
https://blog.csdn.net/qq_42118719/article/details/112347552
标定图片需要使用标定板在不同位置、不同角度、不同姿态下拍摄,最少需要3张,以10~20张为宜。
步骤:
1、从照片中提取棋盘格角点。
2、估算理想无畸变的情况下,五个内参和六个外参。
3、应用最小二乘法估算实际存在径向畸变下的畸变系数。
4、极大似然法,优化估计,提升估计精度.

又由于,R是旋转矩阵,则其是正交矩阵,也就是其任意两个列向量的内积为0,列向量的模为1。
|||||||||||||||||||||||||||||||||||||||||||
故有:
则对于一幅棋盘标定版的图像(一个单应矩阵)可以获得两个对内参数的约束等式



3D平面和2D平面约束
相机标定,双目之间标定
1:基础矩阵
2:单应性矩阵

图像去畸变原理
https://blog.csdn.net/dreamguard/article/details/83096071
函数调用Python
https://blog.csdn.net/qq_30815237/article/details/87622654
径向畸变去除方法

#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace std;
using namespace cv;
//
string distort_image_file="/home/chen/slambook2/ch5/imageBasics/distorted.png";
int main() {
//读图
Mat image_distort=imread(distort_image_file,CV_8UC1);
imshow("未去畸变的图像",image_distort);
waitKey(0);
Mat image_undistort=image_distort.clone();
//去畸变参数
double k1 = -0.28340811, k2 = 0.07395907, p1 = 0.00019359, p2 = 1.76187114e-05;
// 内参
double fx = 458.654, fy = 457.296, cx = 367.215, cy = 248.375;
//去畸变
for (size_t v=0;v<image_distort.rows;v++){
for (size_t u=0;u<image_distort.cols;u++){
double x=(u-cx)/fx,y=(v-cy)/fy; //畸变的空间坐标
double r_2=x*x+y*y; //计算r的平方
//去畸变的P点坐标
double x_undistort=x*(1+k1*r_2+k2*r_2*r_2)+2*p1*x*y+p2*(r_2+2*x*x);
double y_undistort=y*(1+k1*r_2+k2*r_2*r_2)+2*p2*x*y+p1*(r_2+2*y*y);
//去畸变后的图像坐标
double u_undistort=fx*x_undistort+cx;
double v_undistort=fy*y_undistort+cy;
//插值
if(u_undistort>=0 && v_undistort>=0 && u_undistort<image_distort.cols && v_undistort<image_distort.rows){
image_undistort.at<uchar>(v,u)=image_distort.at<uchar>((int)v_undistort,(int)u_undistort);
}
else{
image_undistort.at<uchar>(v,u)=0;
}
}
}
imshow("去畸变的图像",image_undistort);
waitKey(0);
destroyAllWindows();
return 0;
}
Linux基于V4L2的摄像头图像采集
一、V4L2的定义
V4L2(Video For Linux Two) 是内核提供给应用程序访问音、视频驱动的统一接口,在Linux中,视频设备是设备文件,可以像访问普通文件一样对其进行读写,摄像头在/dev/videoN下,N可能为0,1,2,3… 一般为0。
二、工作流程
Step1:初始化摄像头。打开设备->检查和设置设备属性->设置帧格式
Step2:启动采集命令。申请帧缓冲->内存映射->帧缓冲入队列->开始采集->帧缓冲出队列->重新入队列循环采集
Step3:停止采集命令
Step4:关闭摄像头
三、常用的结构体(参见/usr/include/linux/videodev2.h)
struct v4l2_requestbuffers reqbufs;//向驱动申请帧缓冲的请求,里面包含申请的个数
struct v4l2_capability cap;//这个设备的功能,比如是否是视频输入设备
struct v4l2_input input; //视频输入
struct v4l2_standard std;//视频的制式,比如PAL,NTSC
struct v4l2_format fmt;//帧的格式,比如宽度,高度等
struct v4l2_buffer buf;//代表驱动中的一帧
v4l2_std_id stdid;//视频制式,例如:V4L2_STD_PAL_B
struct v4l2_queryctrl query;//查询的控制
struct v4l2_control control;//具体控制的值
四、常用的控制命令
VIDIOC_REQBUFS:分配内存
VIDIOC_QUERYBUF:把VIDIOC_REQBUFS中分配的数据缓存转换成物理地址
VIDIOC_QUERYCAP:查询驱动功能
VIDIOC_ENUM_FMT:获取当前驱动支持的视频格式
VIDIOC_S_FMT:设置当前驱动的频捕获格式
VIDIOC_G_FMT:读取当前驱动的频捕获格式
VIDIOC_TRY_FMT:验证当前驱动的显示格式
VIDIOC_CROPCAP:查询驱动的修剪能力
VIDIOC_S_CROP:设置视频信号的边框
VIDIOC_G_CROP:读取视频信号的边框
VIDIOC_QBUF:把数据从缓存中读取出来
VIDIOC_DQBUF:把数据放回缓存队列
VIDIOC_STREAMON:开始视频显示函数
VIDIOC_STREAMOFF:结束视频显示函数
VIDIOC_QUERYSTD:检查当前视频设备支持的标准,例如PAL或NTSC。
例如:
//打开
#include <fcntl.h>
int open(const char *device_name, int flags);
//关闭
#include <unistd.h>
int close(int fd);
实验使用UVC摄像头,插入后自动生成设备“/dev/vedio0”,
打开关闭实例如下
int fd = open("/dev/video0",O_RDWR);
close(fd);
4 CurveLanes

4 TX2T外接双目相机ZED
下载ZED SDK
https://www.stereolabs.com/developers/release/
chmod +x ZED_SDK_Ubuntu16_v2.7.1.run
./ZED_SDK_Ubuntu16_v2.7.1.run


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









