






向大家介绍一款全新的开源OCR模型——RolmOCR!这款由Reducto AI团队基于阿里巴巴强大的Qwen2.5-VL-7B-Instruct视觉语言模型微调而来的利器,不仅在速度和效率上实现了显著提升(据称处理速度相比其前身olmOCR提升了约40%),更在处理棘手的手写体和倾斜文档方面达到了超过92%的惊人准确率。它不仅仅是一个OCR工具,更是一个能理解文档视觉布局和语义内容的智能助手。
AI快站下载
https://aifasthub.com/reducto/RolmOCR
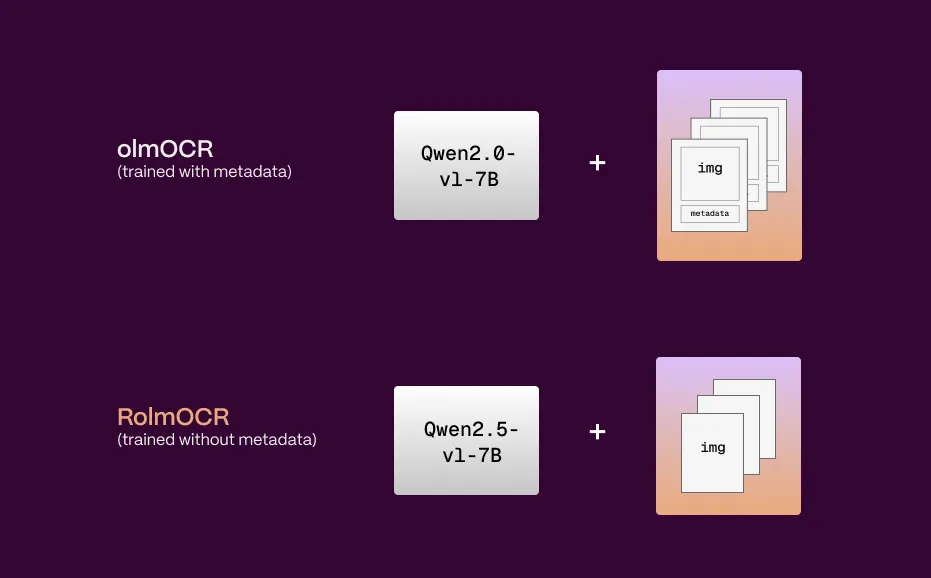
核心优势一:基于强大Qwen2.5-VL,性能更上一层楼
RolmOCR的强大并非偶然,它站在了巨人的肩膀上。其基础模型是来自阿里巴巴的Qwen2.5-VL-7B-Instruct,一个拥有70亿参数的尖端视觉语言模型(VLM)。Qwen2.5-VL本身就具备出色的图像理解、视觉问答和图文关联能力。
RolmOCR通过在Qwen2.5-VL上进行精心微调,不仅继承了其强大的视觉和语言理解基因,还针对OCR任务进行了专项优化。这意味着RolmOCR不仅能“看懂”图像中的文字,更能理解文字所处的上下文环境,例如识别表格结构、判断复选框状态,甚至将图像区域与相关文本进行语义链接。这为处理复杂文档和实现更智能化的信息提取奠定了坚实的基础。
核心优势二:速度与效率革命:处理速度提升40%,内存占用更低
效率是衡量OCR模型实用性的关键指标。RolmOCR在这方面表现尤为突出。相较于其前身olmOCR,RolmOCR在模型结构和处理流程上进行了优化:
- 速度更快: 优化后的模型推理速度更快,据Reducto AI团队信息,相比olmOCR,其处理速度提升了约40%(具体提升幅度可能因硬件和任务复杂度而异)。这意味着在处理大量文档时,可以显著缩短等待时间。
- 内存占用更低: RolmOCR在运行时对计算资源,特别是显存(VRAM)的需求更低。这降低了部署门槛,使得在资源相对有限的环境中运行高性能OCR成为可能。
- 无需元数据: 与olmOCR不同,RolmOCR在处理PDF文档时不再强制依赖其元数据。这不仅简化了处理流程,减少了用户提供额外信息的麻烦,还缩短了处理指令(prompt)的长度,进一步降低了处理时间和VRAM占用。
这些优化使得RolmOCR成为一个既强大又高效的选择,特别适合需要快速、大规模处理文档的应用场景。
核心优势三:攻克倾斜与手写:旋转鲁棒性显著增强,准确率超92%
倾斜文档和手写体一直是传统OCR技术的“老大难”问题。RolmOCR针对性地解决了这一痛点。
- 旋转鲁棒性: 开发团队在训练数据中特别加入了约15%经过旋转处理的文档图像。这种数据增强策略极大地提升了模型对非标准方向文档的识别能力。无论是轻微倾斜还是大幅度旋转的文档,RolmOCR都能更准确地识别其中的文字内容。
- 高准确率: 正是得益于先进的模型架构和针对性的训练,RolmOCR在处理包含手写体和倾斜文字的文档时,识别准确率能够超过92%(此数据通常基于特定基准测试集,实际效果可能因字体、清晰度等因素变化)。这对于处理扫描质量不佳或包含手写笔记的文档来说,是一个巨大的福音。
核心优势四:超越传统OCR:理解布局、表格、复选框的全能选手
RolmOCR的能力远不止于简单的文字提取。它利用其强大的视觉语言理解能力,实现了对文档更深层次的解析:
- 布局理解: 能够识别文档的整体布局,区分标题、段落、列表等元素。
- 表格识别: 不仅能提取表格内的文字,还能理解表格的行列结构,甚至可以根据自然语言指令提取特定单元格或整行/列的数据。
- 复选框与表单处理: 可以识别复选框是否被勾选,并提取表单中填写的内容。
- 基于提示的交互(Prompt-based Interaction): 用户可以通过自然语言向RolmOCR提问,让它从文档中提取特定的信息。例如,你可以问:“这份合同的甲方是谁?”或者“表格中‘总计’金额是多少?” RolmOCR会尝试理解你的问题并在文档中找到答案。
这种超越传统OCR的“智能”特性,使得RolmOCR在自动化数据录入、智能文档审核、知识提取等领域具有巨大的应用潜力。
应用场景
RolmOCR的应用场景十分广泛,包括但不限于:
- 文档数字化: 将纸质文档、扫描件快速转化为可编辑、可搜索的电子文本。
- 自动化数据录入: 自动从发票、收据、表单中提取关键信息,减少人工录入成本。
- 智能表单处理: 识别并提取各类申请表、调查问卷的内容。
- 金融票据识别: 处理银行对账单、支票等金融文件。
- 档案管理与检索: 对历史档案进行数字化处理,并实现基于内容的智能检索。
- 教育领域: 识别手写笔记、试卷,辅助教学评估。
总结与展望
RolmOCR的发布,无疑为开源OCR领域注入了新的活力。它基于强大的Qwen2.5-VL视觉语言模型,实现了速度、效率、准确性(尤其在处理手写和倾斜文档方面)的显著提升,并具备了超越传统OCR的文档理解能力。
AI快站下载
https://aifasthub.com/reducto/RolmOCR

















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









