适用于:
Microsoft Visual C++ .NET 2003
Microsoft Visual C++ Toolkit 2003
Microsoft Visual Studio .NET
摘要:演示了 Visual C++ 2003 编译器提供的众多代码优化功能中的几项功能。(8 页打印页)
本文是 Visual C++ Toolkit 2003 随附的代码示例的一部分,可从以下网址下载:http://msdn.microsoft.com/visualc/vctoolkit2003。
 本页内容
Microsoft?Visual C++?Toolkit 2003 包含优化 C++ 编译器。大多数开关相当简明,并且已经在 Visual C++ 产品的多个版本中存在,但仍然有两个开关比较新,并且无须重写代码就能够显著提高速度。它们是 /GL (Whole Program Optimization) 和 /G7(它能产生为 Pentium 4 或 AMD Athlon 优化的代码)。还有一个选项 /arch:SSE2,它能产生针对 SSE2 寄存器和指令而优化的代码。 示例代码经过了三项测试:
| 1. | 调用作为内联候选函数的函数。 | | 2. | 执行大量浮点乘法和加法运算。 | | 3. | 执行大量整数乘法和加法运算。 |
完整程序优化 示例代码定义了两个非常类似的函数:Add() 和 DisplayAdd()。DisplayAdd() 会显示到屏幕,因此不太可能被内联: void DisplayAdd(int a, int b)
{
cout << a << " + " << b << " = " << a + b << endl;
cout << "Return address from " << __FUNCTION__
<< " " << _ReturnAddress() << endl;
}
_ReturnAddress 是一个内部函数,它报告控制将在何处返回。可使用它来标识内联函数。 Add() 在 gl-g7.cpp 中声明,同时还声明一个由它设置的全局变量: void* inlineReturnAddress; // set in Add()
int Add(int a, int b); // implementation in module.cpp
实现位于 module.cpp 中: int Add(int a, int b)
{
inlineReturnAddress = _ReturnAddress();
return a+b;
}
要编译该程序且不使用 Whole Prgram Optimization,请使用以下命令行: cl /O2 /ML /EHsc GL-G7.cpp module.cpp
要运行测试 1,请使用以下命令: gl-g7 1
应该看到与以下内容类似的输出(数值地址会有所不同): 1 + 2 = 3
Return address from DisplayAdd 00401D0A
1 + 2 = 3
Return address from Add 00401D13
Return address from Test1 00402125
Add() 的返回地址与 Test1() 的返回地址不同:Add() 没有被内联。 现在,使用 /GL 重新编译: cl /O2 /ML /EHsc /GL GL-G7.cpp module.cpp
再次运行测试 1,应该看到如下所示的输出: 1 + 2 = 3
Return address from DisplayAdd 00401242
1 + 2 = 3
Return address from Add 0040179F
Return address from Test1 0040179F
现在,Add() 和 Test1() 的返回地址相同:Add() 在Test1() 内部内联,即使它的代码来自另一个文件。
为 Intel Pentium 4 或 AMD Athlon 优化代码 /G7 是 Microsoft?Visual Studio?.NET 2003 中的新增选项;它通过选择与其他场合不同的指令,产生为 Pentium 4 或 AMD Athlon 优化的代码。在对整数进行乘法运算(尤其是将一个整数乘以一个在编译时已知的常数)的例程中,性能方面的改善最为明显。 测试 2 演示了可能获得的速度方面的改善: #define INT_ARRAY_LEN 100000
int intarray[INT_ARRAY_LEN];
int intCalculate()
{
int total = 0;
for (int i = 1; i < INT_ARRAY_LEN; i++)
{
total += intarray[i-1]*7;
}
return total;
}
void Test2()
{
int var1 = 2;
int i;
for (i = 0; i < INT_ARRAY_LEN; i++)
{
intarray[i] = i*5;
var1 += 2;
}
LARGE_INTEGER start, end;
LARGE_INTEGER freq;
SetThreadAffinityMask(GetCurrentThread(), 1);
QueryPerformanceFrequency(&freq);
QueryPerformanceCounter(&start);
double total = 0;
for (i = 0; i < 100000; i++)
{
total += intCalculate();
}
QueryPerformanceCounter(&end);
cout << "Total = " << total << endl;
cout << (end.QuadPart - start.QuadPart)/(double)freq.QuadPart << " seconds" << endl;
}
上述代码使用了一些在 kernel32.dll(它是 Microsoft?Windows? 的一部分)中实现的计时函数。这些函数以及它们使用的数据类型在 windows.h 中定义。为减小该示例中的依赖性,在 gl-g7.cpp 中提供了这些函数的原型,并且定义了相应的数据类型。QueryPerformanceCounter 保存了起始时间或结束时间,而QueryPerformanceFrequency 得到一个值,经过除法运算得到起始时间与结束时间的差值,从而得到以秒为单位的运行时间。对SetThreadAffinityMask 的调用减少了多处理器计算机上的人工作业。 该例程执行了大量整数乘法。要在不使用处理器专有指令的情况下编译它,请使用以下命令行: cl /O2 /ML /EHsc GL-G7.cpp module.cpp
要为 Pentium 4 或 AMD Athlon 计算机编译它,请使用以下命令行: cl /O2 /ML /EHsc /G7 GL-G7.cpp module.cpp
要运行测试 2,请使用以下命令行: gl-g7 2
在 Pentium 4 或 AMD Athlon 计算机上,/G7 版本的运行速度提高了 10% 以上。上述代码可以在不带适当芯片的计算机上运行,但与在编译时未使用/G7 的版本相比,速度稍微慢一点。
Streaming SIMD Extensions 2 如果您确信在为具有 SSE2 支持的计算机(例如 Pentium 4 或 AMD Athlon 计算机)生成代码,则可以使用 /arch:SSE2 选项。这样产生的代码将不能在其他芯片上运行,但速度更快,尤其是对含有大量浮点算法的例程而言。 测试 3 执行与测试 2 极为相似的浮点计算: #define ARRAY_LEN 10000
double array[ARRAY_LEN];
double Calculate()
{
double total = 0;
for (int i = 1; i < ARRAY_LEN; i++)
{
total += array[i-1]*array[i];
}
return total;
}
void Test2()
{
double var1 = 2;
int i;
for (i = 0; i < ARRAY_LEN; i++)
{
array[i] = var1;
var1 += .012;
}
LARGE_INTEGER start, end;
LARGE_INTEGER freq;
SetThreadAffinityMask(GetCurrentThread(), 1);
QueryPerformanceFrequency(&freq);
QueryPerformanceCounter(&start);
double total = 0;
for (i = 0; i < 100000; i++)
{
total += Calculate();
}
QueryPerformanceCounter(&end);
cout << "Total = " << total << endl;
cout << (end.QuadPart - start.QuadPart)/(double)freq.QuadPart << " seconds" << endl;
}
要在不使用处理器专有指令的情况下编译它,请使用以下命令行: cl /O2 /ML /EHsc GL-G7.cpp module.cpp
要想仅为 Pentium 4 或 AMD Athlon 计算机编译它,请使用以下命令行: cl /O2 /ML /EHsc /G7 /arch:SSE2 GL-G7.cpp module.cpp
要运行测试 3,请使用以下命令行: gl-g7 3
在 Pentium 4 或 AMD Athlon 计算机上,/G7 /arch:SSE2 版本的运行速度大约提高了 10%。上述代码在不带适当芯片的计算机上不能运行。
如果有 Visual Studio 所有上述选项都可以在“Project Properties”对话框中使用。
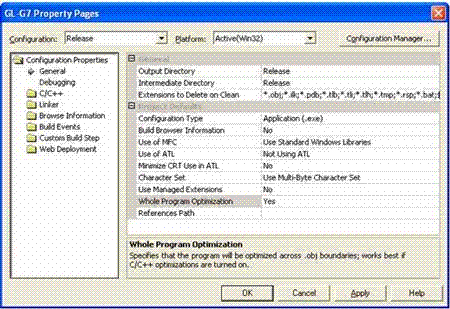
图 1. 常规项目属性
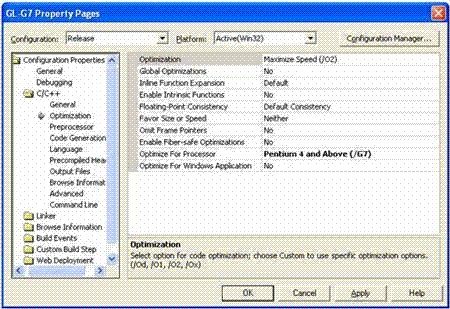
图 2. C/C++ 优化选项

图 3. C/C++ 代码生成选项
如果您要为特定芯片生成定制版本,可以创建多种配置,每种配置都带有不同的选项组合。
小结 不同的程序以不同的方式响应优化。尽管逐个模块的优化也不错,但添加完整程序优化可带来明显的改善。因为您不需要更改代码就可以使用它,所以没有理由不这样做。 如果您的大多数用户或所有对性能敏感的用户都拥有 Pentium 4 或 AMD Athlon 计算机,请使用 /G7 选项为这些用户生成更快速的代码,同时应记住这样的代码对于您的其他用户将会稍微慢一些。如果您要为 Pentium 4 或 AMD Athlon 计算机创建特定的优化版本,请同时使用 /arch:SSE2 选项以获得最佳性能。
相关书籍 Microsoft Visual C++ .Net 2003 Kick Start(作者:Kate Gregory) 关于作者 Kate Gregory 是 Microsoft 地区主管,她是一位 C++ MVP,并且是《Microsoft Visual C++ .NET 2003 Kick Start》一书的作者。她是Gregory Consulting 的创立合伙人,该公司在整个北美提供咨询和开发服务,致力于使用前沿技术进行软件开发、项目集成、技术写作、顾问以及培训。 转到原英文页面 | 










 1684
1684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























