






写在前面
在设备端运行的大语言模型(LLMs),即指在边缘设备上运行LLMs,因其出色的隐私保护、低延迟和节省带宽的特点而引起了广泛关注。然而,与功能更为强大的云中心相比,设备端LLMs的能力本质上受到边缘设备有限容量的制约。为了弥合基于云端的AI与设备端AI之间的鸿沟,移动边缘智能(MEI)提供了一个可行的解决方案,它通过在移动网络边缘提供AI能力,相较于云计算,在隐私保护和延迟方面都有所改善。MEI位于设备端AI和基于云端的AI之间,具备无线通信功能,且计算资源比终端设备更为强大。本文提供了关于利用MEI来优化LLMs的当代综述。首先,我们介绍了LLMs的基础知识,从LLMs和MEI讲起,接着讨论了资源高效的LLMs技术。然后,我们通过几个关键应用实例,展示了在网络边缘部署LLMs的必要性,并介绍了面向LLMs的移动边缘智能(MEI4LLM)的架构概览。随后,深入探讨了MEI4LLM的各个方面,广泛涵盖了边缘LLMs的缓存与分发、边缘LLMs的训练以及边缘LLMs的推理。最后,指出了未来的研究方向。本文旨在激励该领域的研究人员利用移动边缘计算,促进LLMs在用户附近的部署,从而在各种注重隐私和低延迟的应用场景中发挥LLMs的潜力。
一些介绍
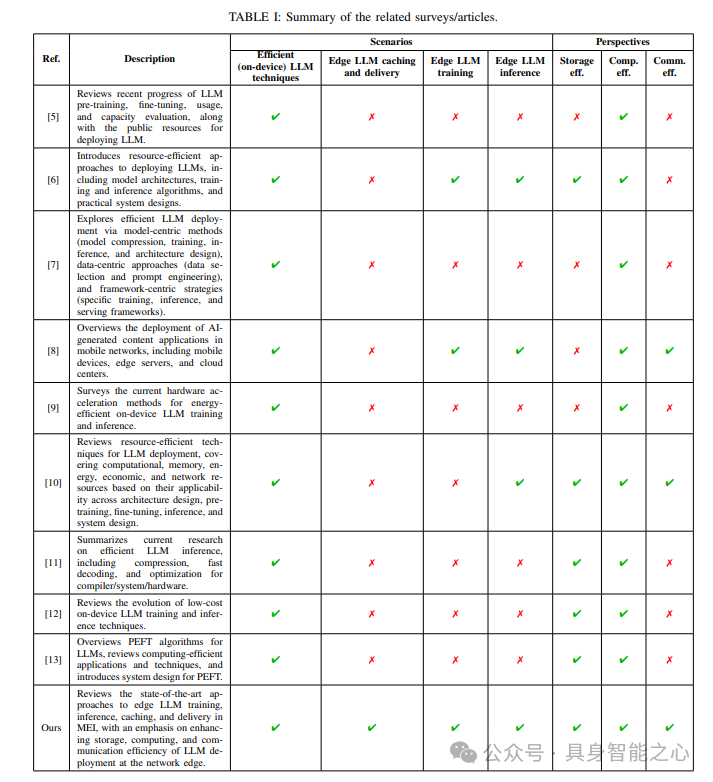
大型语言模型(LLMs)的部署远比传统深度神经网络(DNNs),如卷积神经网络(CNNs)更加资源密集,这是将LLMs推向网络边缘的主要障碍。本综述文章旨在从资源高效部署的角度,包括网络边缘的存储效率、计算效率和通信效率,对当前这一融合趋势,即移动边缘智能(MEI)与LLMs,进行当代综述。
本文与先前关于高效LLM训练/微调及推理的综述文章有所不同。这些文章大多聚焦于提高计算效率,却忽视了通信对LLM训练、推理、缓存及分发的影响,这在移动边缘网络中是一个显著的瓶颈。
本文也与现有的关于LLM边缘部署的综述文章/论文存在差异。这些文章探讨了通过云边协同实现LLM赋能的AI服务提供,但并未讨论资源高效的部署方案,如参数高效的微调、分割推理/学习、高效的LLM缓存及分发,以及它们与无线边缘网络的相互作用。
最后,值得注意的是,本综述文章与关于“LLMs用于网络”的论文在本质上不同,后者的设计目标是利用LLMs来优化边缘网络,而不是利用边缘计算来支持LLMs。与相关综述文章/论文的对比见表I。本文的主要贡献概括如下:
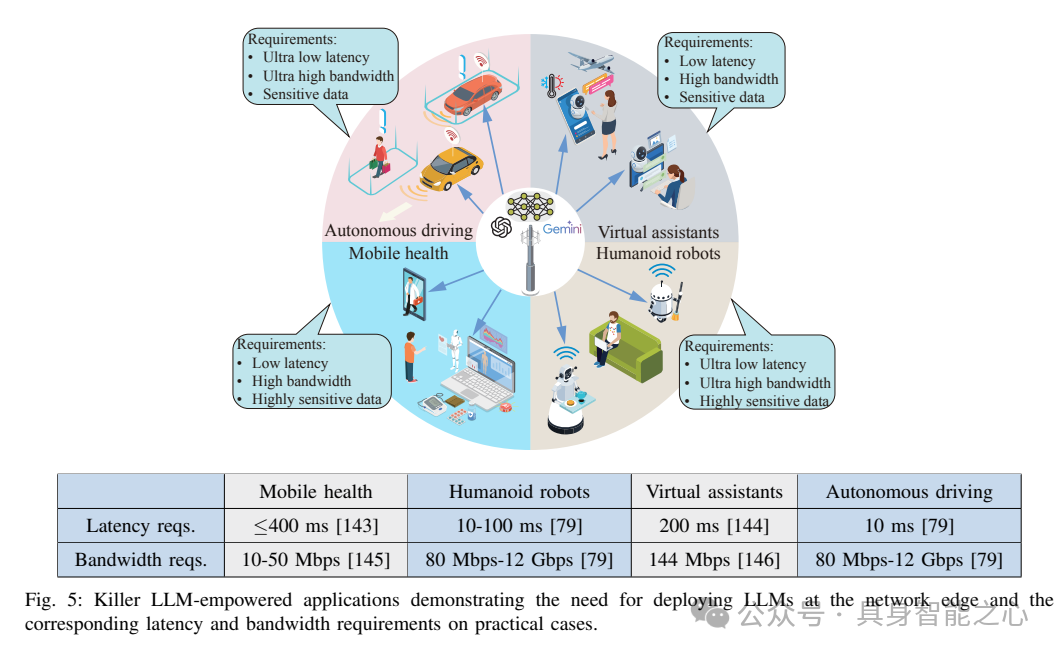
- 介绍了推动大型语言模型(LLMs)在网络边缘部署的应用场景。尽管LLMs的应用案例已在其他地方得到广泛讨论,但我们将基于这些应用的服务需求,强调在移动边缘提供这些应用的必要性或益处。
- 首次全面调查了6G边缘网络如何促进LLM的缓存与分发、训练及推理,包括边缘LLM的缓存与分发、边缘LLM的训练以及边缘LLM的推理。将特别关注LLM的资源高效部署,以提高网络边缘LLM的存储、通信和计算效率。
- 指出了LLMs与移动边缘智能融合的几个关键研究方向,包括面向LLMs的绿色边缘AI和安全边缘AI。
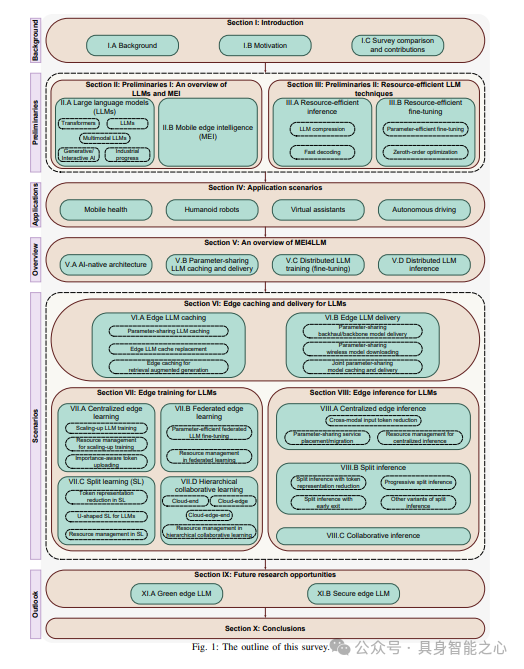
大语言模型(LLMs)与移动边缘智能(MEI)概述
最新的相关综述汇总:
移动边缘智能(MEI)已成为一种将人工智能与移动边缘计算相结合的有前途的范式,彻底改变了移动服务和应用的格局。MEI的发展源于多种技术进步的融合,包括物联网(IoT)设备的普及、移动网络的部署以及人工智能算法的成熟。这些发展使得MEI能够克服传统以云为中心的架构的局限性,通过在网络边缘提供本地化的AI训练/推理和数据处理能力。
通过整合人工智能(AI)与通信技术,移动边缘智能(MEI)框架使移动网络能够提供超越通信的服务,为万物智联奠定了坚实基础。在此背景下,“集成AI与通信”的应用案例已被纳入6G国际移动通信(IMT)框架建议中。在标准化方面,电信标准化组织3GPP和国际电信联盟(ITU)分别在各自的白皮书中描绘了边缘智能的前景。ITU-3172基于机器学习(ML)应用对延迟的敏感要求,阐明了在网络边缘托管ML功能的必要性。在3GPP发布的5G标准化第18版中,MEI旨在支持分布式学习算法、拆分AI/ML以及高效的AI模型分发。接下来将详细阐述具体内容。首先,边缘网络将全面支持边缘学习,如联邦学习,这使得边缘服务器能够从多个分布式边缘设备聚合模型更新和知识,从而提高AI/ML模型的性能。其次,在5G边缘网络上拆分AI/ML可以促进在具有相互冲突需求(如计算密集型、能耗密集型、隐私敏感型和延迟敏感型需求)的设备上部署AI应用。例如,在边缘拆分推理中,AI模型被划分为子模型,其中计算密集型和能耗密集型的子模型被卸载到5G边缘服务器(如基站)。边缘服务器可以使用边缘侧的子模型和从边缘设备上传的中间数据进行推理。最后,高效的AI模型下载确保了当边缘设备需要适应新的AI任务和环境时,能够以低延迟将AI模型传输到边缘设备。例如,当驾驶环境发生变化时,自动驾驶车辆需要在1秒内从5G边缘服务器下载一个新的AI模型。为了将基于网络的AI算法集成到5G网络中,MEI框架需要满足边缘服务器与边缘设备之间高速稳定数据链路的需求。这些链路可以确保持续以高且稳定的上行数据速率将中间数据/模型更新上传到边缘服务器,并在需要时以高下行数据速率突发下载AI模型到边缘设备。此外,MEI的核心是利用数据源靠近边缘计算设备(如智能手机、笔记本电脑和可穿戴设备)的优势,使智能决策更接近数据源。这种分布式计算范式相较于传统的集中式架构具有诸多优势,包括降低延迟、提高带宽利用率、保护数据隐私以及增强对网络故障的韧性。
在应用方面,移动边缘智能(MEI)在多个领域如智慧医疗、自动驾驶和智慧城市等都有着重大影响。例如,在医疗领域,MEI能够实现对患者健康数据的实时监控,并在紧急情况下促进及时干预。同样,在智慧城市中,MEI有助于智能交通管理、环境监测和能源优化,从而推动可持续发展并提升生活质量。边缘智能也见证了显著的工业进步,特别是随着边缘计算技术的普及和5G网络的到来。微软、谷歌、亚马逊和英伟达等领军企业已经开发了边缘AI平台,以支持实时AI服务。对于边缘AI赋能的物联网应用,微软的“Azure IoT Edge”、谷歌的“Cloud IoT”、亚马逊的“Web Services IoT”以及英伟达的“EGX”等平台提供了边缘AI解决方案,为从实时视频分析、智能家居到工业物联网的广泛应用带来了实时AI服务。
显然,MEI4LLM不过是MEI(移动边缘智能)的一个特例。然而,在边缘训练和部署大量大型语言模型(LLM)的需求可以成为推动MEI发展的关键因素。一方面,下一代MEI的原则,包括推动AI与通信的全面融合,与边缘LLM的需求高度契合。另一方面,LLM对资源的极端需求推动了MEI的边界拓展。具体而言,MEI4LLM必须具备以下特点:1)原生支持模型拆分和跨互联边缘节点的并行训练/推理,以促进超大规模模型的部署;2)无线网络和资源高效LLM训练/推理技术的集成设计,如参数高效微调和token(表征)减少,以使LLM部署具有成本效益。本质上,与传统MEI相比,MEI4LLM主要关注探索资源管理和高效AI技术的集成设计,以在有限的通信-计算资源下支持LLM。
资源受限的LLM技术
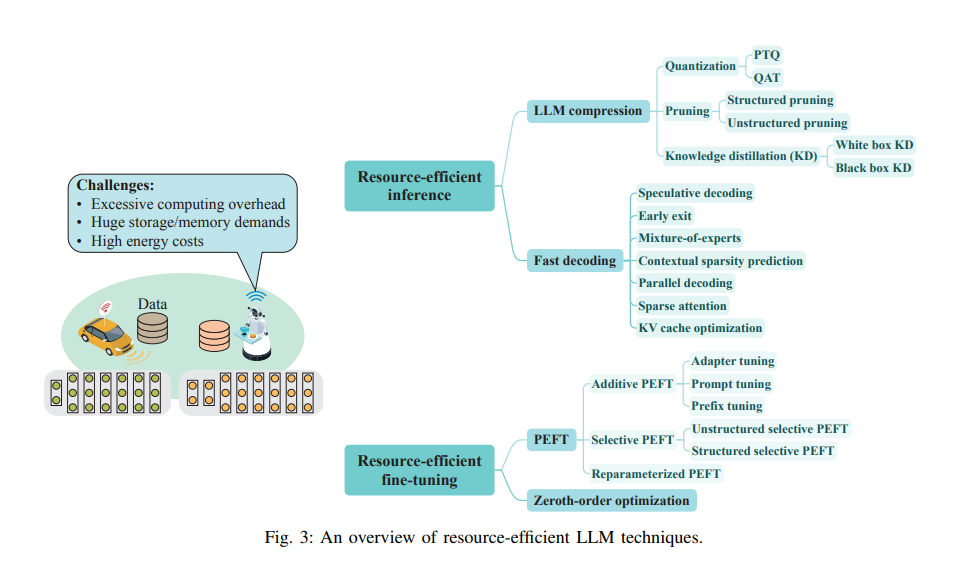
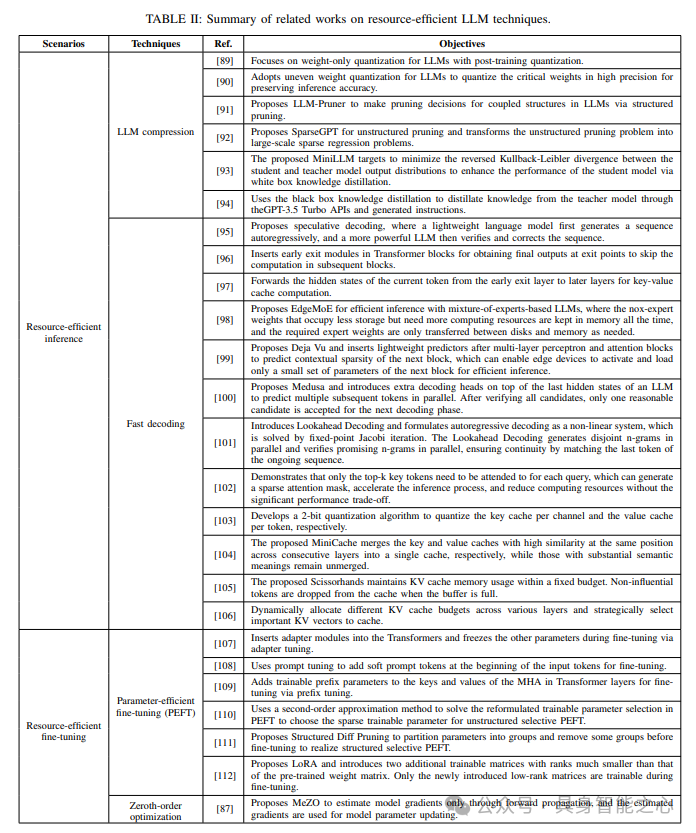
资源有限的fine-tuning
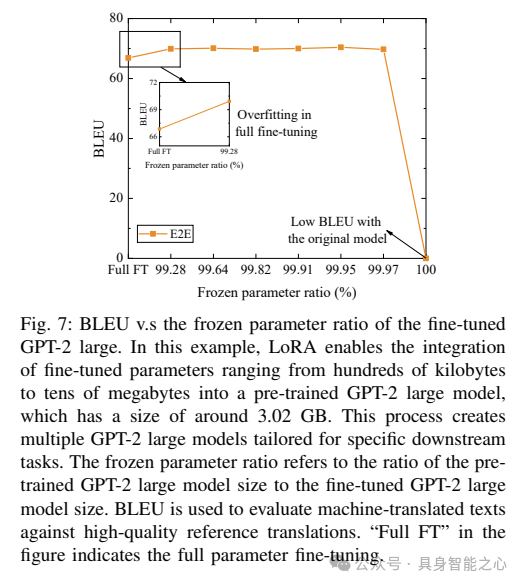
与推理相比,设备上大型语言模型(LLM)的训练需要显著更高的内存和计算资源。例如,计算LLM OPT-13B的梯度所需的内存是推理所需内存的12倍。然而,由于LLM微调所需的计算资源远少于全参数训练,因此在设备上部署LLM时广泛采用了LLM微调。
参数高效微调:参数高效微调(PEFT)已成为LLM微调的一个显著解决方案,它通过在微调过程中仅更新少数参数来实现。流行的PEFT技术可以分为三种主要类型,即加法PEFT、选择性PEFT和再参数化PEFT,下面将详细阐述这些类型。
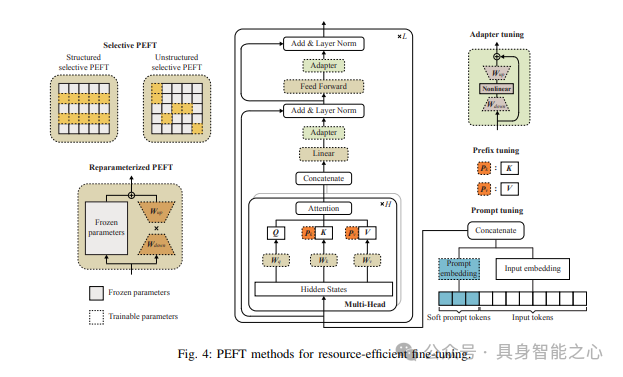
零阶优化:零阶优化是一种新颖的模型训练技术,它仅通过前向传播来估计梯度更新。这种方法大大减轻了计算负担,因为前向传播(相当于推理)所需的计算资源远少于训练过程中的反向传播。具体来说,与流行的一阶优化器(如Adam)相比,零阶优化器无需在训练过程中存储反向传播的中间结果,从而显著降低了大型语言模型(LLM)训练中的内存消耗。
应用场景
MEI4LLM概述与应用
LLM的边缘缓存与传输
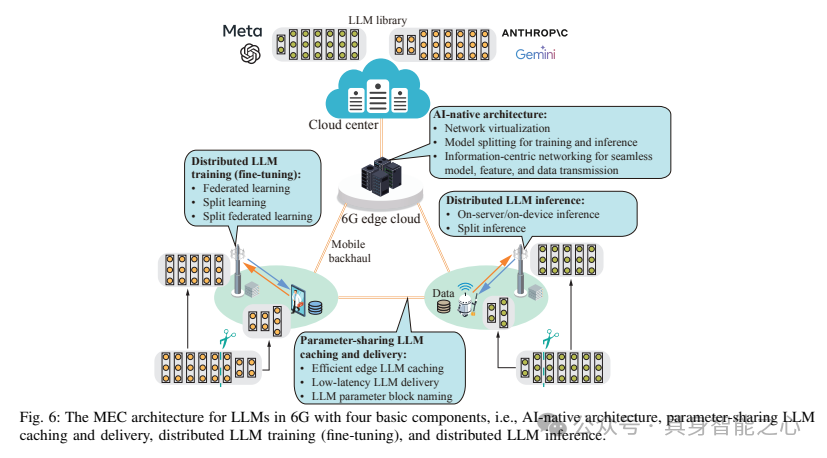
边缘LLM缓存与传输在LLM的训练和推理中都扮演着不可或缺的角色,是边缘LLM部署的基石。与传统的边缘服务/内容缓存与传输相比,边缘LLM缓存与传输的主要区别在于利用了LLM中普遍存在的参数共享性,旨在提高边缘网络的存储和通信效率。虽然传统深度神经网络(DNN)中也可能存在参数共享性,但由于PEFT技术的广泛应用,参数共享性在LLM中更为普遍且重要,这需要我们特别关注其设计。
1) Edge LLM Caching
边缘模型缓存可以通过提前将AI模型分发到无线边缘服务器来实现低模型下载延迟。与用于计算卸载的服务放置不同,边缘模型缓存侧重于缓存AI模型,以便从边缘服务器下载到终端用户。AI模型缓存的设计目的是在服务质量(QoS)要求范围内为更多用户提供模型。这种范式使用户能够直接从边缘服务器获取AI模型,而不是访问远程云数据中心,从而避免了过高的下载延迟。然而,实施边缘LLM缓存面临几个挑战:1)LLM缓存的存储空间有限:服务提供商旨在尽可能多地在边缘服务器上放置流行的LLM,以提高缓存命中率并降低用户的模型下载延迟。然而,LLM的巨大体积对其在边缘服务器上的存储构成了重大挑战;2)LLM边缘缓存(替换)成本高:随着时间的推移,之前缓存的LLM可能不再符合不断变化的用户需求。为了解决这一问题,服务提供商可能会替换边缘服务器上的LLM,以更好地适应最新的请求。但是,这些大规模模型的放置会导致巨大的通信开销,并对移动回程网络造成沉重负担。接下来,将介绍参数共享模型缓存,以应对上述挑战。

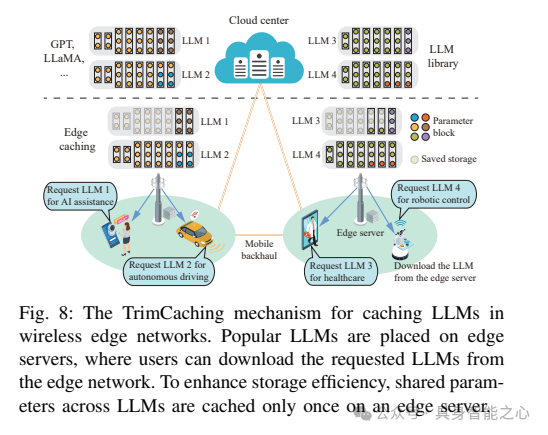
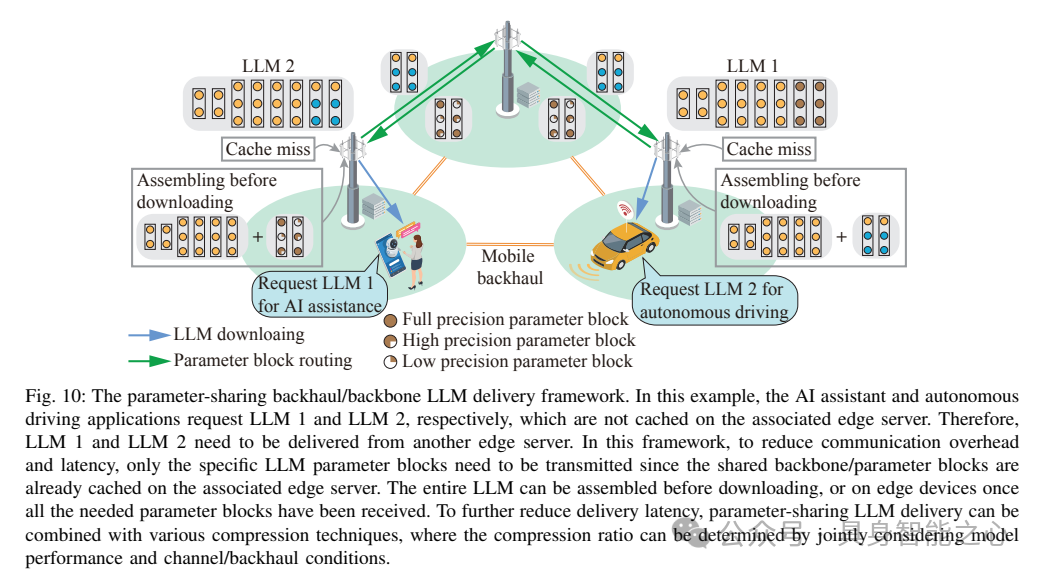
2)Edge LLM Delivery
从缓存位置将模型传输到终端用户的关键步骤是高效延迟的模型传输。这一过程包括回程/骨干网内的模型路由和通过无线接入链路进行的模型下载,面临着以下挑战:1) 过高的回程/骨干网传输延迟:当请求的LLM(大型语言模型)未缓存在相关边缘服务器上时,LLM需要在边缘网络内进行路由。然而,与传统AI模型相比,LLM的模型尺寸要大得多。因此,LLM的路由需要在回程流量适中的边缘服务器之间进行;2) 显著的无线下载延迟:AI模型的下载需要低延迟,以满足终端用户的QoS(服务质量)要求。如3GPP所设想,自动驾驶应用要求AI模型的下载在1秒内完成。然而,LLM庞大的模型尺寸阻碍了快速下载,使其极难满足严格的服务延迟要求。这要求采取以下解决方案。

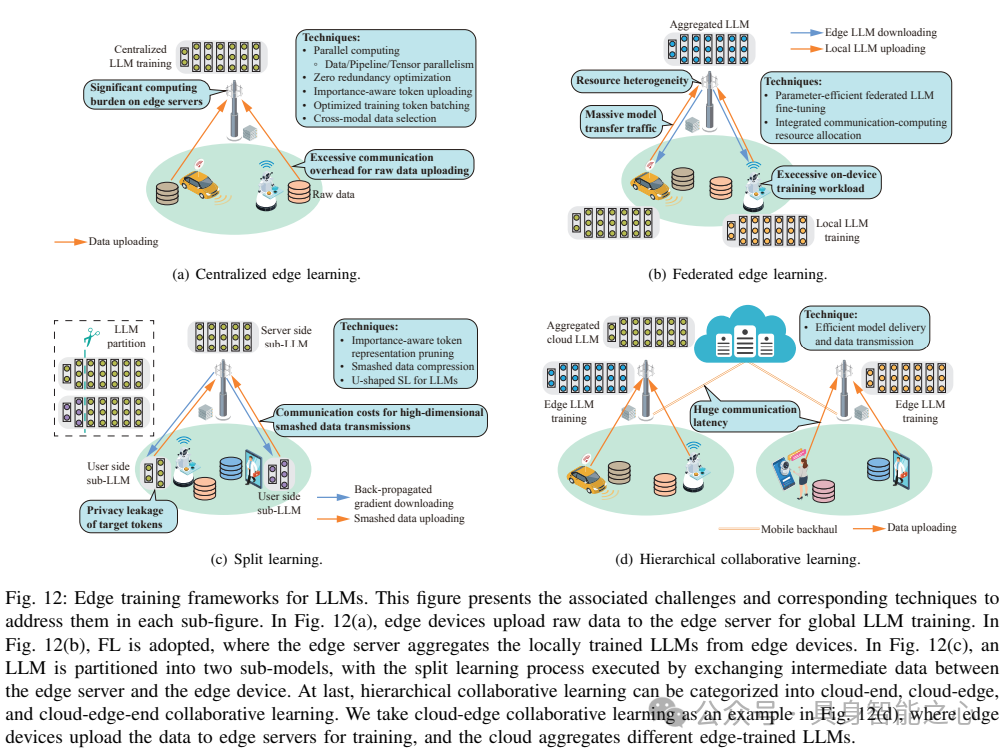
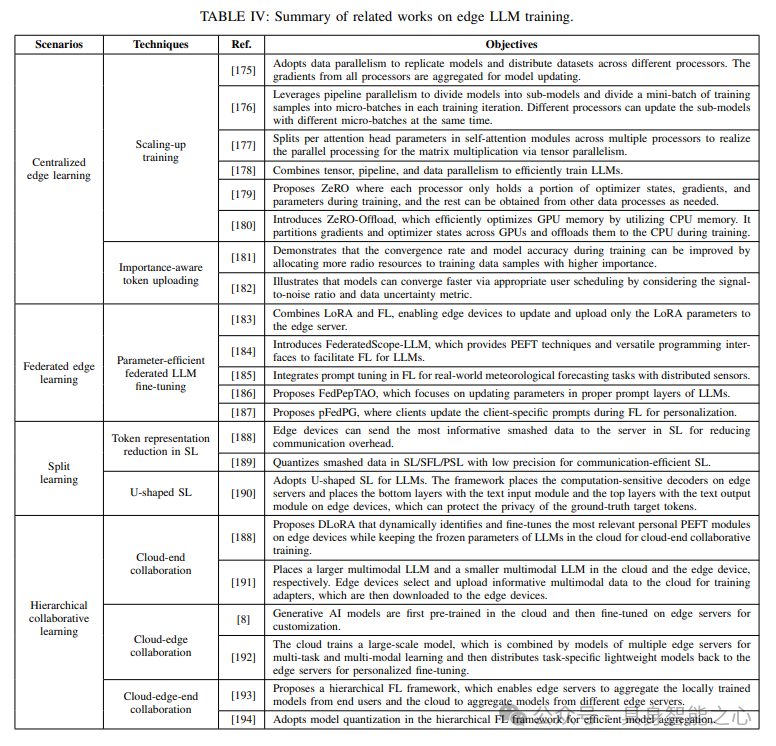
LLMs的边缘训练
边缘端的LLMs推理
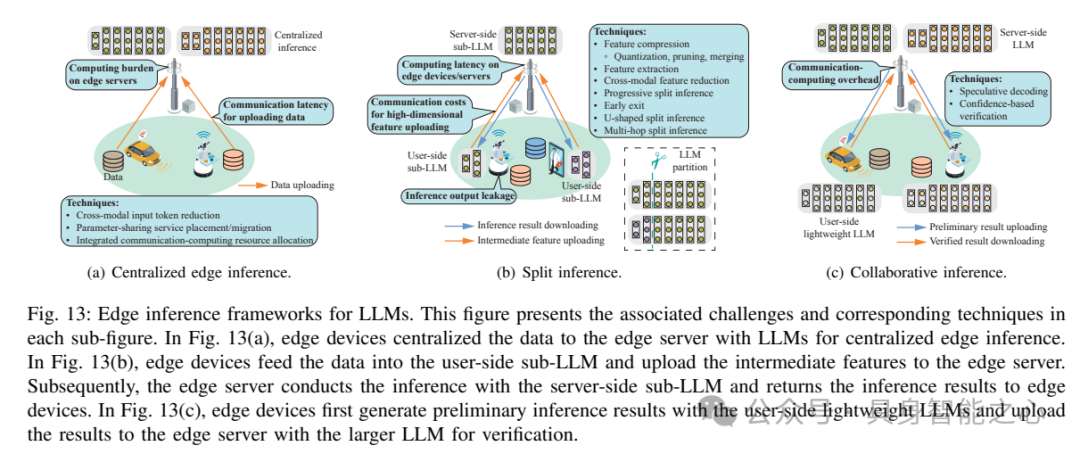
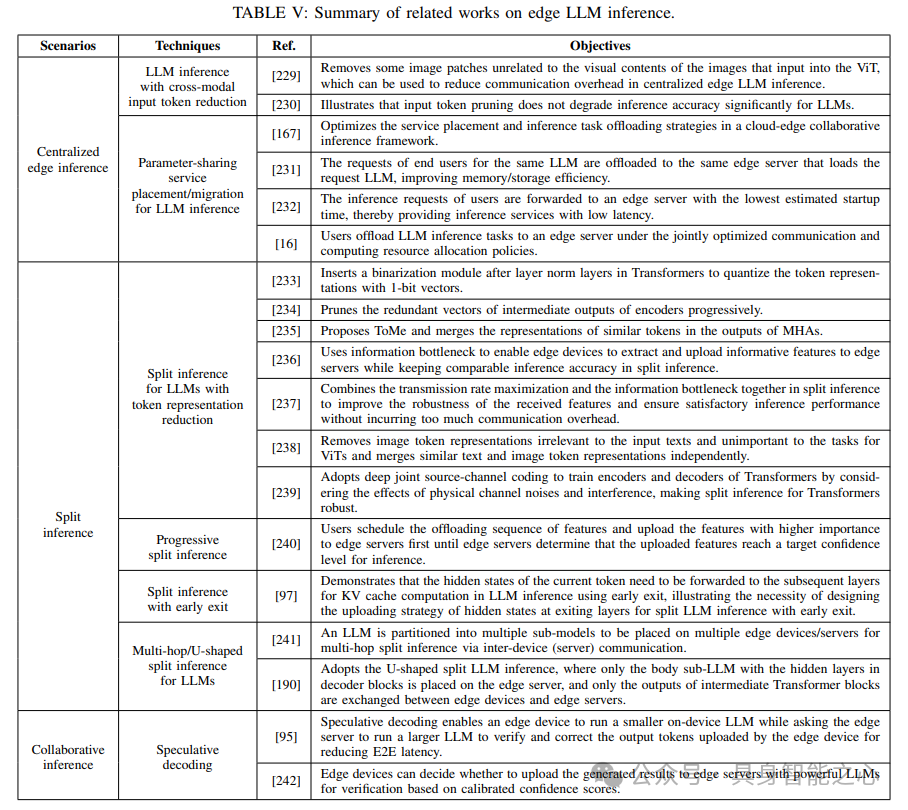
边缘LLM(大型语言模型)推理利用边缘计算,基于训练良好的LLM为终端用户提供推理服务。边缘LLM推理与传统边缘推理框架的主要区别在于,它利用LLM的特性(如多模态性、参数共享性和自回归过程)来加速推理过程。边缘LLM推理可分为三种框架:集中式边缘推理、分割推理和协作推理。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









