






【导读】Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度
过去几年,Transformer虽稳坐AI架构「铁王座」,但其二次方复杂度带来的算力消耗和长序列处理瓶颈,限制了大模型在推理阶段处理长文本。
Mamba凭借「线性复杂度」异军突起,非常适合长序列任务,有望成为Transformer架构的替代品,但在处理全局关系上偏弱。
Mamba+Transformer混合架构可以将二者的优势互补,实现「效率」和「性能」的双丰收。
最近英伟达发布了Nemotron-H系列模型,模型尺寸为8B和56B(蒸馏版本47B),用Mamba-2层替换了Transformer中的自注意力层,关键创新在于对Transformer和Mamba的平衡,实现了高效处理长上下文的同时,还不牺牲模型性能,显著提高了推理速度,并且内存占用更少。

论文链接:https://arxiv.org/pdf/2504.03624
实验结果表明,Nemotron-H模型在准确度上优于同尺寸的开源Transformer模型(例如Qwen-2.5-7B/72B和Llama-3.1-8B/70B),同时在推理速度上提速3倍。
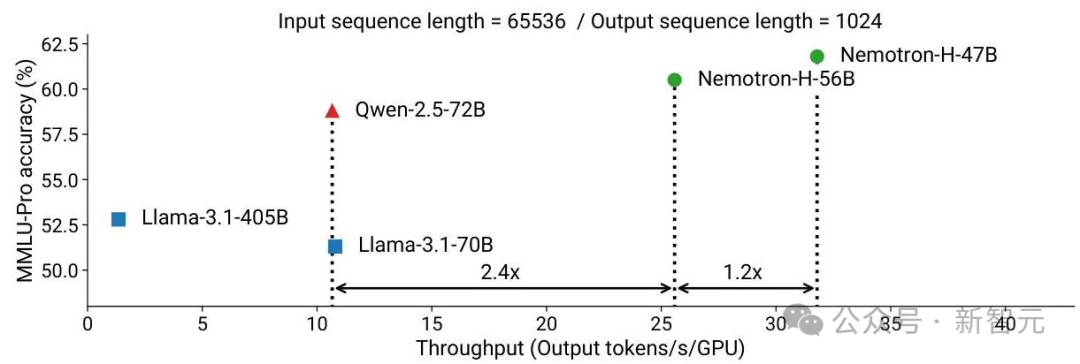
为了进一步提高推理速度并降低推理时所需的内存量,研究人员使用一种剪枝和蒸馏压缩技术MiniPuzzle,将56B尺寸的模型蒸馏为NemotronH-47B-Base,在基准的准确率上与56B模型相当,同时推理速度提升20%
论文中还提出了一种基于FP8的训练方案,使56B模型实现了与BF16训练相当的性能。
Nemotron-H架构
Nemotron-H模型由Mamba-2、自注意力层和前馈神经网络(FFN)层组成,其中总层数的8%为自注意力层,均匀分布在模型中。
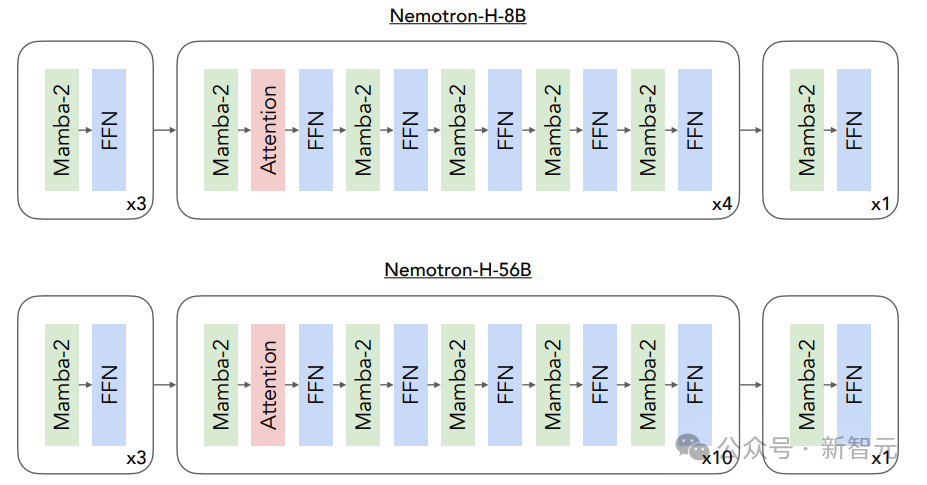
即,Nemotron-H-8B模型包含52层,其中4层为注意力层;Nemotron-H-56B模型包含118层,其中10层为注意力层,其余层平均分配为FFN层和Mamba-2层。
为了与标准Transformer模块的结构一致,研究人员提出三条设计准则:模型的第一层必须是Mamba-2层,最后一层必须是FFN层,并且自注意力层总是位于FFN层之前。

模型的具体参数
需要注意的是,8B和56B模型在FFN隐藏维度、注意力查询头和状态维度设置上存在差异;
-
对于Mamba-2层,保持默认的头维度(64)、扩展因子(2)和卷机窗口(4);
-
使用RMSNorm进行归一化;
-
不适用位置嵌入;
-
模型的嵌入层和输出层使用了独立的权重,没有使用线性层的偏置权重,也没有使用dropout;
-
在每个Mamba-2层、自注意力层和FFN层周围都加入了残差跳跃连接。
训练过程
数据准备
训练数据从来源上大体上可以分为多语言、网络爬取、学术、代码、维基百科和数学数据,这种数据组合可以全面覆盖通用知识,同时在编程和数学等领域培养强大的专业能力。
其中多语言数据涵盖了九种语言:德语、西班牙语、法语、意大利语、葡萄牙语、中文、日语、韩语和俄语。
研究人员设计数据组合时,确保所有相同质量的数据源权重相似,而高质量的数据源权重会高于低质量的数据源。
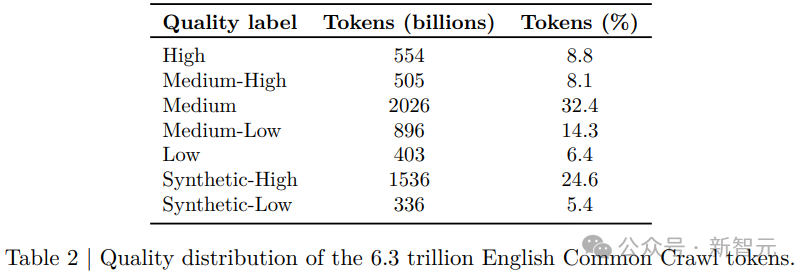
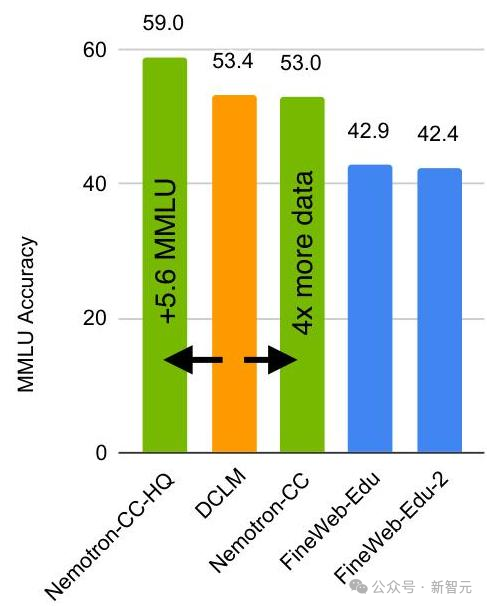
在训练56B尺寸的模型时,使用了大约20万亿个token的数据,其中,网页爬取数据占比最大,达到了59%,其次是代码数据,占20%,学术内容占8.8%
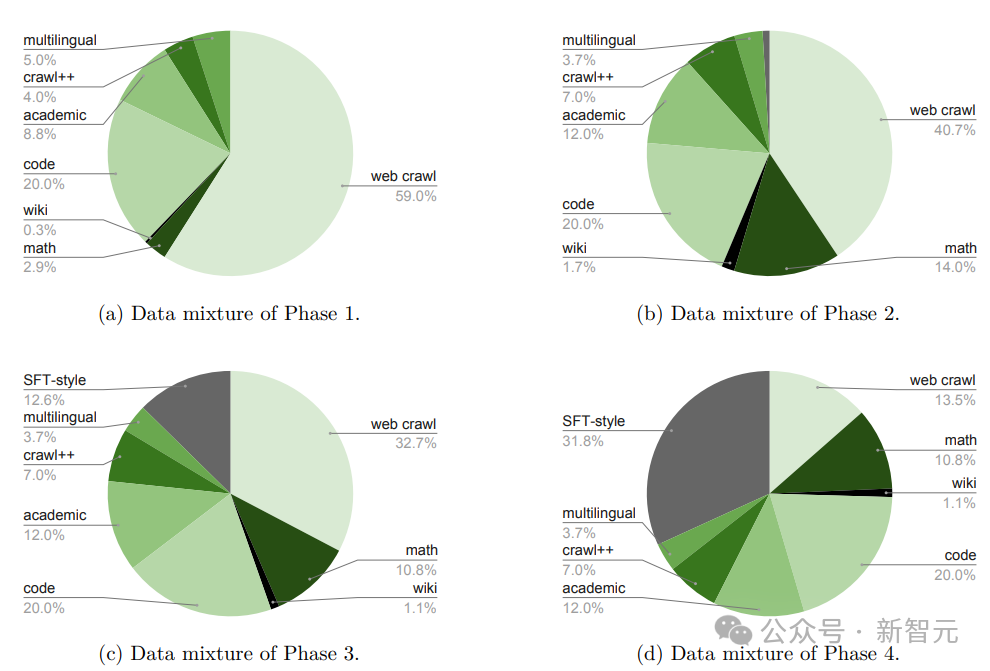
在预训练Nemotron-H基础模型时,研究人员采用了分阶段的数据混合方法:
第一阶段,使用一种促进数据多样性的数据组合;在第二和第三阶段,主要使用高质量的数据集(例如维基百科),其中第二阶段为训练进度达到60%时,第三阶段为训练进度达到80%时;第四阶段则使用最后3800亿个训练token
在后训练阶段,研究人员调整了数据的分布,更加注重有监督的微调(SFT)样本。
FP8训练策略
Nemotron-H训练的一个创新在于使用8位浮点数(FP8),在降低内存需求和计算成本的同时,还能保持模型的质量,主要包括以下关键点:
采用逐张量(per-tensor)的当前缩放技术,以提高训练的稳定性。
将模型中最初的四个和最后四个矩阵乘法(GEMM)操作保持在BF16精度,以确保关键部分的高精度处理;
在训练过程中,FP8训练逐渐与BF16训练收敛,最终达到类似的性能水平。
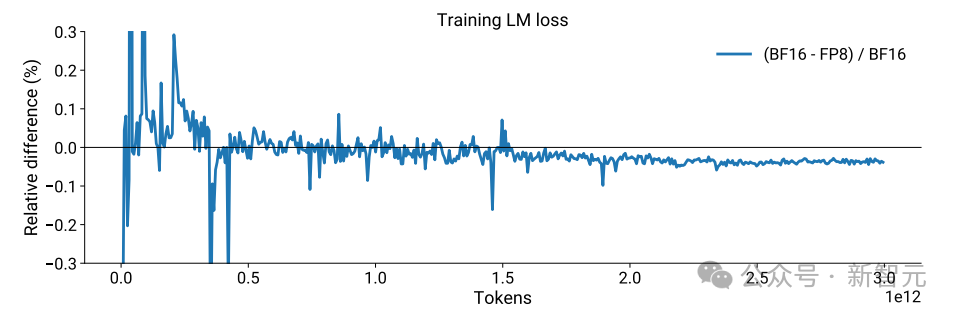
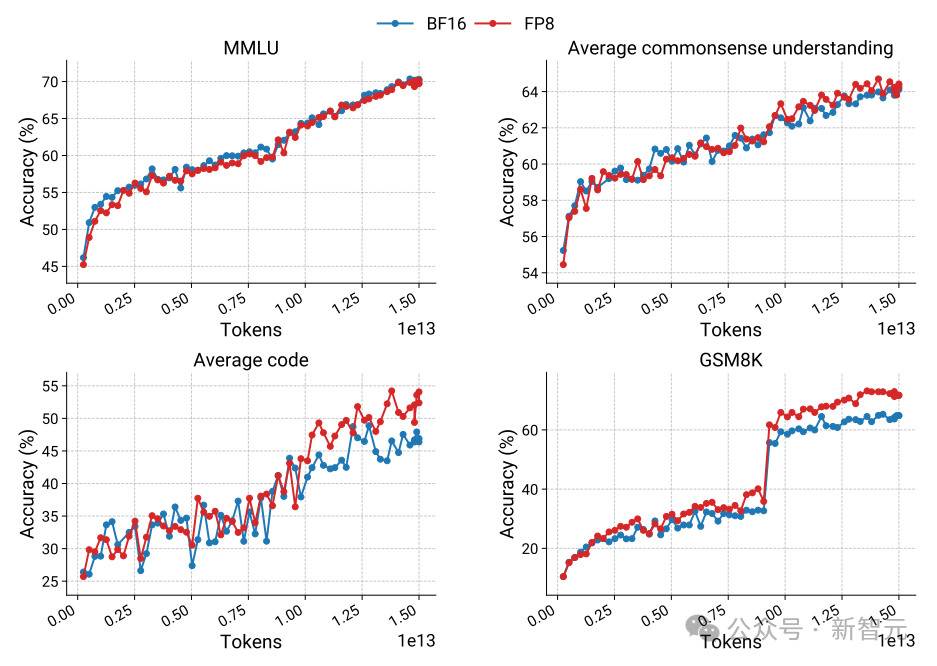
实验结果表明,FP8训练在多种基准测试中能够达到或超过BF16训练的性能,不仅提高了训练效率,还通过在MMLU、常识理解、代码生成和GSM8K等基准测试中的表现,证明了其在保持或提升模型质量方面的有效性
模型压缩
为了进一步提高模型部署的效率,研究人员开发了一种新型压缩框架MiniPuzzle的,结合了剪枝、神经架构搜索和知识蒸馏技术。
MiniPuzzle压缩框架的工作流程如下图所示,展示了从预训练模型到压缩模型的转变过程,包括重要性评估、神经架构搜索和蒸馏等步骤。

MiniPuzzle方法包含五个阶段:
1. 重要度估计: 分析每一层对模型性能的贡献。
2. 层重要度分析: 研究人员需要分析出哪些层对模型性能的贡献最大。
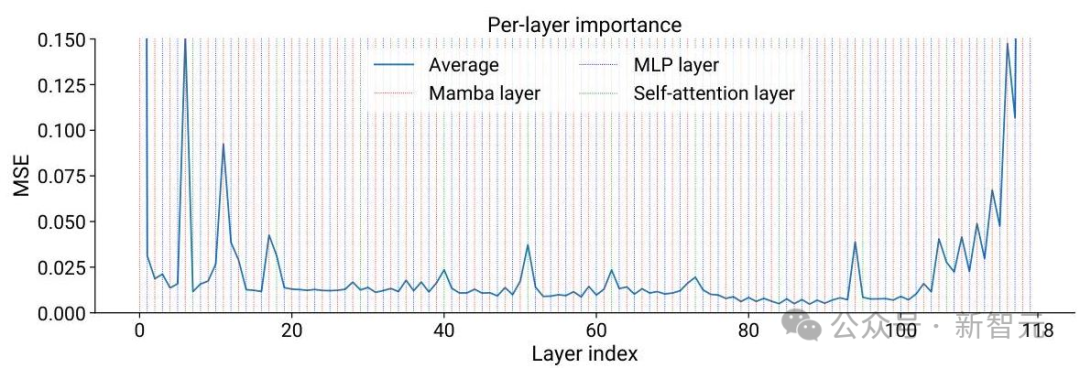
3. 条件神经架构搜索: 探索不同压缩架构方案,在每个候选压缩模型中保留不同的层。

4. 内存与性能权衡: 根据内存使用量和准确度对模型进行评估,对候选架构的内存负载与基准性能进行权衡。
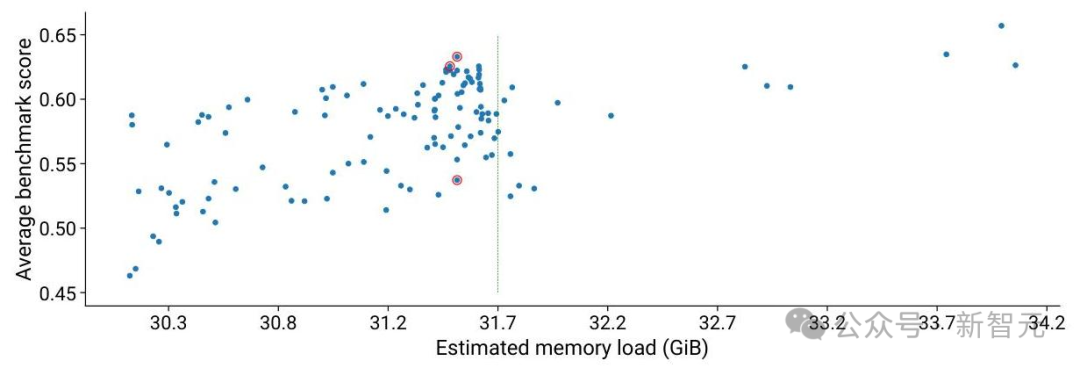
5. 知识蒸馏: 通过训练,使压缩后的模型能够匹配甚至超越原始模型的能力。
通过这一过程,Nemotron-H-56B模型成功被压缩为Nemotron-H-47B模型,参数减少了16%,同时保持了相当的准确度,并将推理吞吐量提高了20%。
实验结果
Nemotron-H模型在性能和效率方面相较于其他基于Transformer的模型取得了显著进步。
推理吞吐量
混合架构使得推理速度大幅提升,尤其是在处理长序列时:
- Nemotron-H-56B的推理吞吐量比Qwen-2.5-72B和Llama-3.1-70B高出多达3倍。
- Nemotron-H-8B在类似准确度水平下,比Qwen-2.5-7B的吞吐量高出1.8倍。
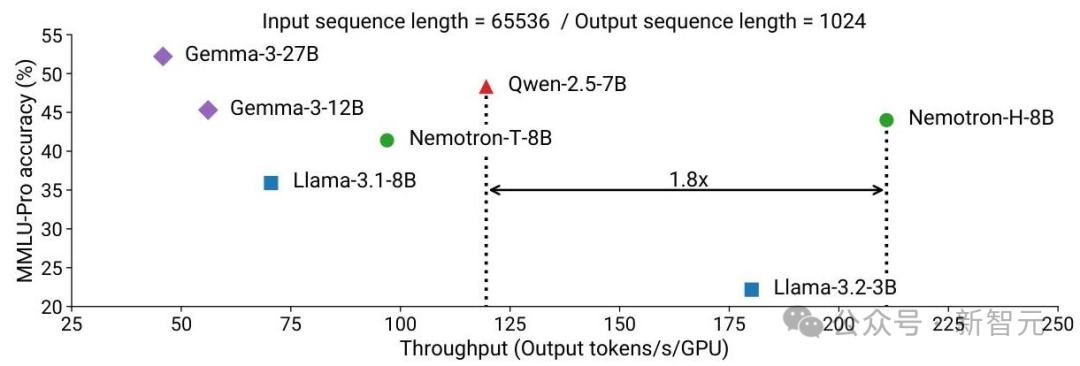
效率提升在处理长序列(例如65,536个token)时尤为明显,突显了Mamba层在输出token时计算复杂度固定的优势。
多基准测试中的准确度
尽管架构发生了变化,但Nemotron-H模型在广泛的基准测试中仍保持了强劲的性能表现。
在评估的17项任务中,Nemotron-H-56B在16项任务中的表现优于Llama-3.1-70B,在数学推理任务上表现尤为出色。
应用与多功能性
Nemotron-H模型可以进行扩展,以适应各种应用场景。
-
视觉-语言能力: 基础模型通过NVLM-D架构扩展,创建了视觉-语言模型(VLM),在VQAv2、GQA和VizWiz等基准测试中表现出色,显示出混合架构对多模态任务的适应性。
-
代码生成: 模型在与代码相关的任务上表现尤为出色。训练数据中包含大量代码数据(占比20%),使得模型能够理解和生成多种编程语言的高质量代码。
-
长文本处理: 混合架构的一个显著优势是能够高效处理长文本。Nemotron-H-8B模型经过专门的长文本处理能力微调,在RULER基准测试和其他长文本评估任务中表现出色。
-
针对不同能力的数据分布: 研究人员针对不同的训练阶段精心调整了数据分布,以培养特定的能力,通过调整不同数据类型(网页爬取、代码、数学、学术等)的比例,可以在不需要架构变更的情况下增强模型的特定能力。比如针对STEM能力优化时,训练数据增加了数学和代码内容的比重。
Mamba架构简介
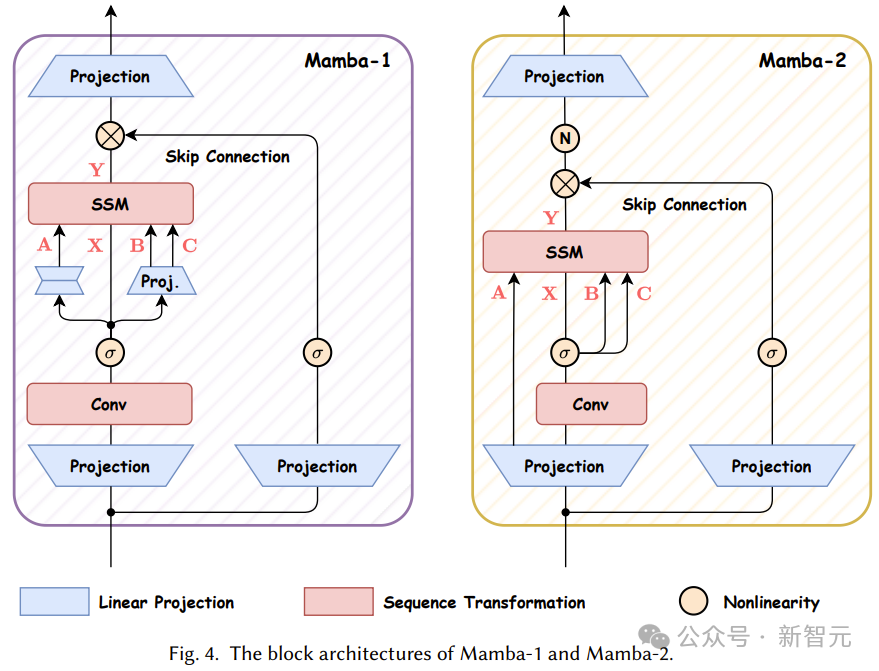
原版Mamba架构
Mamba是一种新型的序列建模架构,通过选择性状态空间模型(Selective State Space Model, SSM)和硬件优化算法,将计算复杂度降低到线性级别O(L),能够高效处理长达百万级的序列长度,推理速度比Transformer快5倍,在短序列任务中也实现了超越Transformer的性能。
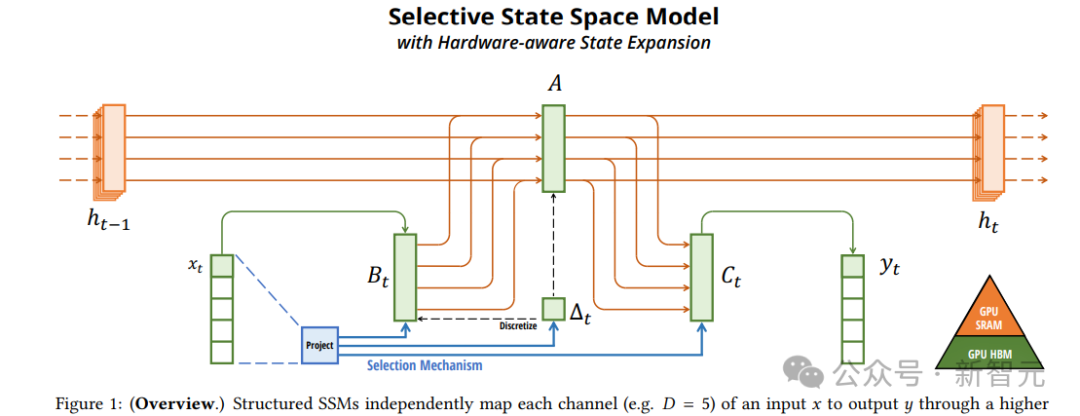
选择性SSM的思路是,通过让模型参数依赖于输入内容,实现对信息的选择性传播和遗忘,过滤无关信息,从而提高对密集模态(如语言和基因组)的建模能力。
Mamba中的硬件感知并行算法,可以避免显式存储扩展状态,利用GPU的内存层次结构优化计算过程,实现线性时间复杂度,并显著提升推理速度。

论文链接:https://arxiv.org/pdf/2312.00752
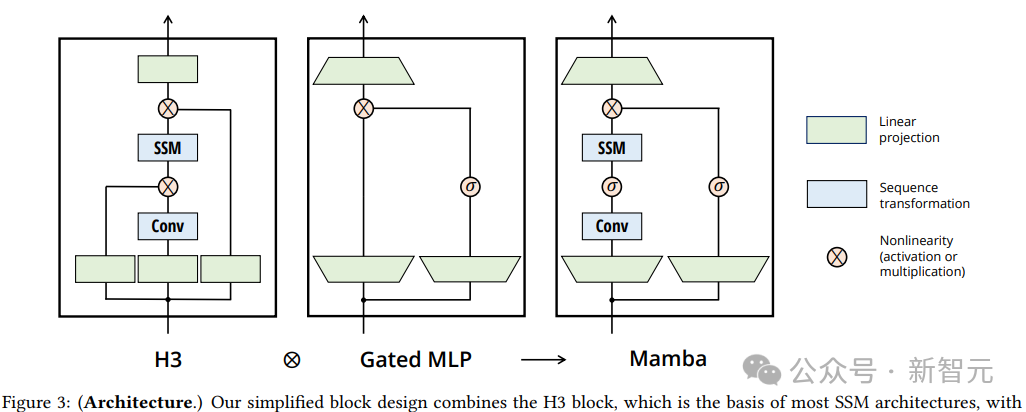
Mamba-2架构
Mamba-2结合了状态空间模型(SSMs)和注意力机制,基于State Space Duality (SSD) 框架,通过结构化矩阵的分解和优化算法,实现了线性扩展的训练效率。
与Mamba相比,Mamba-2对核心层进行了优化,简化了状态转移矩阵的结构,并引入了更大的头维度,从而显著提高了训练效率,速度提高了2-8倍;还引入了多头结构和张量并行等技术,进一步增强了模型的表达能力和并行计算效率,在大规模训练和推理中更加高效。
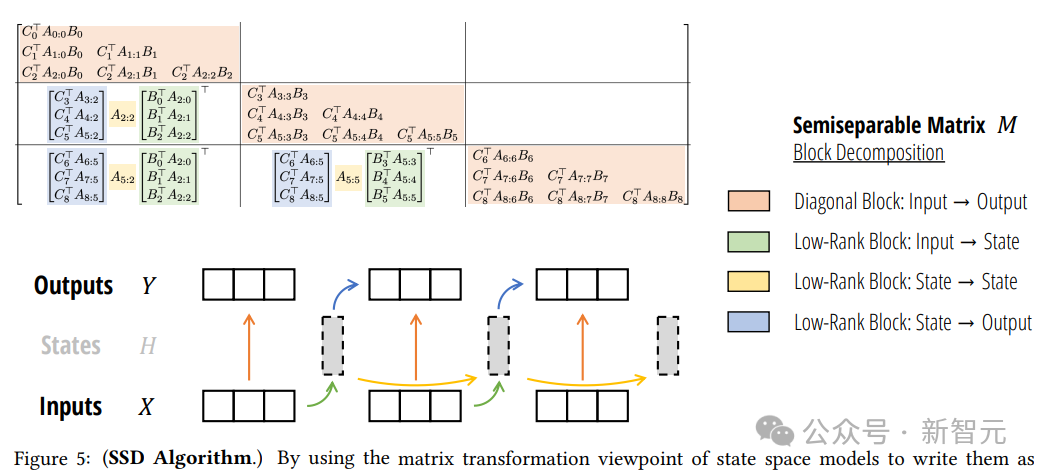
在实验中,Mamba-2在语言建模和多查询关联回忆任务上均优于Mamba和基于注意力的模型。

论文链接:https://arxiv.org/abs/2405.21060
参考资料:
https://arxiv.org/pdf/2504.03624
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









