






监督式微调 (Supervised fine-tuning),也就是SFT,就是拿一个已经学了不少东西的大型语言模型,然后用一些特定的、已经标记好的数据来教它怎么更好地完成某个特定的任务。就好比你已经学会了做饭,但是要特别学会怎么做川菜,那就得用川菜的菜谱来练手。

现在大多数的大型语言模型,比如今年流行的那些,都是通过这种方式来学会怎么更好地聊天或者执行命令的。
在监督式微调的过程中,这个大型语言模型会用一种叫做监督学习的方法,通过一些已经标记好的数据来学习。它会根据任务的需要,调整自己的参数,就像是在学习怎么更好地预测下一个词或者理解一句话的意思。
这种微调通常在模型已经预训练好之后进行,目的是让模型能够更好地理解用户的指令。虽然这样做比那种没有监督的微调要费事一些,但是效果通常也更好。
至于要微调多少,那就得看任务有多复杂,还有你手上有多少数据了。比如说,你要是用OpenAI的模型,比如GPT-3.5或者GPT-4,来做点简单的风格转换,有个30到50个好例子通常就够了。
如果你想把一个基础的大型语言模型变成一个能听懂指令的模型,比如从Mistral变成Mistral Instruct,那可能就得用上万个例子来训练。
比如说,一个大概有70亿参数的大模型,它的微调训练可能需要在16个Nvidia A100 GPU上跑大概4个小时,这就算是个不错的开始了。
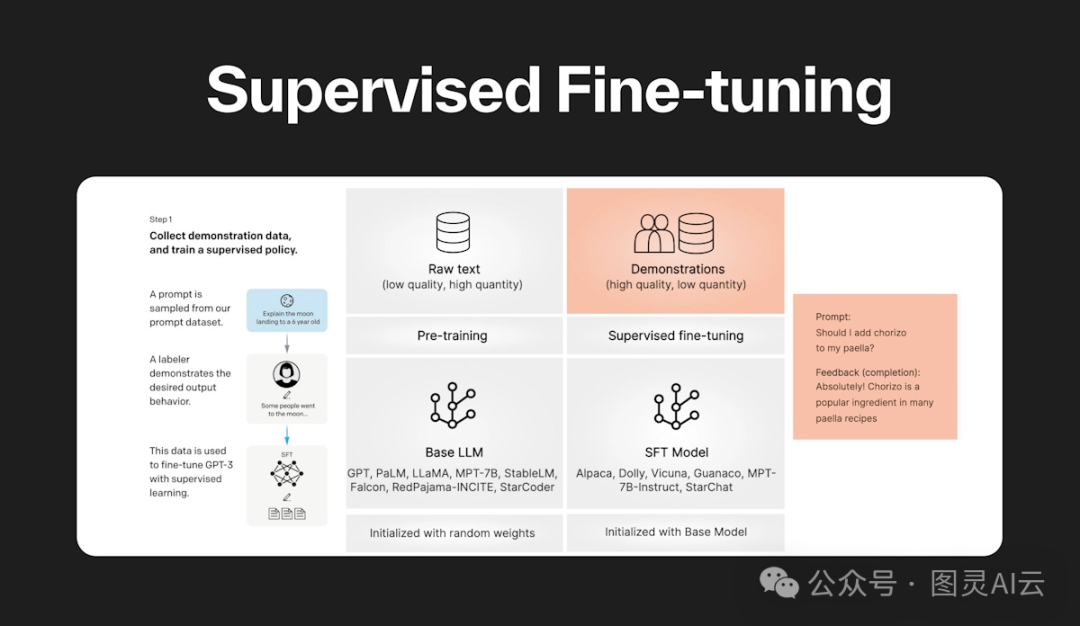
监督式微调,就像是给一个已经学了不少的模型来个特训,让它在某个具体任务上表现得更出色。这整个过程分成三步:
-
预训练:最开始,这个模型会在一大堆数据上学习,试着预测句子里的下一个词,这样它就能慢慢懂得语言的规律、语法和上下文。这个阶段就是让模型对语言有个大概的了解。
-
数据标注:接下来,得准备一些特别的数据,这些数据都是已经标记好的,告诉模型每个数据点的正确答案是什么。这些标记好的数据对监督学习来说特别重要,因为它们会告诉模型在微调时该怎么调整自己。
-
微调:最后,就是用这些已经标记好的、跟特定任务有关的数据来继续训练模型。这样模型就会调整自己,让自己在那个特定的任务上表现得更好,比如文本分类、情感分析或者问答系统。
我们说这个过程是“监督”的,是因为整个过程都是用那些已经知道正确答案的标记数据来指导学习的。这样一来,模型就能把之前学的那些广泛的语言知识,专注地用在某个特定的任务上,提高自己的准确度。
| 微调类型 | 训练数据 | 使用场景 |
|---|---|---|
| 监督式微调 | 使用标注数据 | 当你有标注数据并需要将模型适配到特定任务以提高准确性时 |
| 自监督微调 | 无需标注数据 | 当标注数据不可用,你希望模型从数据的内在结构中学习时 |
| 无监督微调 | 模型从输入数据生成标签 | 当你希望利用大量未标注数据来预训练模型,以用于下游任务时 |
| 强化学习微调 | 使用基于奖励的决策进行训练 | 当任务涉及顺序决策制定,并且有反馈可用于指导学习时 |
监督式微调好处可不少:
-
学得更精准 — 通过调整模型的参数来适应特定的任务,模型就能掌握任务特有的那些小细节和模式。
-
表现更上一层楼 — 微调能让模型用上它之前从海量数据中学到的知识和技能,这样一来,在特定任务上的表现就能更上一层楼。
-
数据用得更精明 — 哪怕手头的标注数据不多,SFT也能让模型在各种真实世界的场景中发挥出不错的效果。
-
资源用得更经济 — 比起从头开始训练一个模型,微调一个已经预训练过的模型能省下不少时间和计算资源。
-
定制化服务 — SFT能让模型的行为、写作风格或者专业知识更贴合特定的需求,无论是语气还是术语,都能和特定的风格或专业领域紧密结合。
-
避免学得太死板 — 在微调的过程中,可以通过早停、dropout或者数据增强等手段来避免模型在小数据集上学得太死板,让它能更好地适应新数据。
总的来说,监督式微调就是让模型在保持广泛知识的同时,还能在特定任务上表现得更加精准和高效。
咱们聊聊那些让大型语言模型(LLMs)变得更聪明的监督式微调技术。这些技术就像是给模型们开小灶,让它们在特定任务上表现得更出色。常见的有这么几种:
-
LoRA(低秩适应) — 这招挺巧妙,用低秩分解的方式来更新模型的权重,就像是用两个小矩阵来代替一个大矩阵,这样一来,需要调整的参数就少了,微调起来也更高效。
-
QLoRA(量化LoRA) — 这是LoRA的一个升级版,它在内存使用上更节省,特别适合那些大块头的语言模型。
这些技术都属于参数高效微调(PEFT)的范畴,目的就是让微调过程既省资源又高效。
除了LoRA和QLoRA,还有其他一些技巧:
-
基本超参数调整 — 这就像是给模型调校引擎,通过手动调整学习率、批量大小和训练周期数等超参数,直到模型的表现达到最佳。
-
迁移学习 — 这种方法是让模型在已经学会的基础上,再用标注数据来学习新的特定任务。
-
多任务学习 — 这就像是让模型同时学几门课,这样它就能学会在不同任务之间找到共通点。
-
少样本学习 — 当可用的标注数据不多时,这种方法能让模型利用有限的信息来做出预测。
-
任务特定微调 — 这种方法就是让模型全身心投入到一个特定任务中,通过调整所有层的参数来提高性能。
-
奖励建模 — 这招是通过给模型设定奖励,让它在标注数据集上学习,从而更准确地预测结果。
-
近端策略优化 — 这种方法用人类反馈来指导模型,就像是有个教练在旁边指导,帮助模型在特定任务上做得更好。
-
比较排名 — 这招是训练模型去判断不同输出的相关性或质量,就像是让模型学会自己给自己打分,从而提高输出的质量。
这些技术就像是模型的私人教练,帮助它们在特定领域里变得更加专业。
| 微调方法 | 描述 | 使用场景 |
|---|---|---|
| LoRA(低秩适应) | 减少可训练参数 | 当你需要在有限的计算资源下进行高效的微调时使用 |
| QLoRA(量化LoRA) | LoRA的内存效率变体 | 当内存限制是一个问题,并且你需要微调大型模型时使用 |
| 超参数调整 | 手动调整学习率和批量大小 | 当你需要通过参数调整来优化模型性能时使用 |
| 迁移学习 | 在特定任务上进行微调 | 当你有新任务的标注数据,并希望利用预训练的知识时使用 |
| 多任务学习 | 同时在多个任务上进行训练 | 当你希望模型学习跨任务的共享表示时使用 |
| 少样本学习 | 在少量标注示例上进行训练 | 当标注数据稀缺,你希望利用模型的现有知识时使用 |
| 任务特定微调 | 在任务特定数据上训练整个模型 | 当你需要为特定任务调整所有模型层时使用 |
| 奖励建模 | 在有正确答案的标注数据集上进行训练 | 当你需要模型基于奖励准确预测标签时使用 |
| 近端策略优化 | 使用人类反馈的强化学习进行微调 | 当任务涉及从人类偏好中学习以提高性能时使用 |
| 比较排名 | 训练模型根据相关性对输出进行排名 | 当你需要模型生成高质量、相关性强的输出时使用 |
这些微调技术就像是给大型语言模型(LLMs)穿上了定制的外衣,让它们能够更好地适应各种特定的任务和领域。这样一来,模型不仅性能更上一层楼,而且能更精准地理解和生成语言,无论是处理自然语言、做翻译、写摘要还是分析情感,都能大显身手。
不过,监督式微调LLMs的时候也会遇到一些常见的挑战:
-
过拟合 — 就是模型在训练数据上表现太好,以至于在新的、没见过的数据上就懵了。这在机器学习里挺常见的,微调的时候也得留心。
-
超参数调整 — 这就像是调琴弦,如果调得不好,模型学起来可能就慢了,或者学完也用不好。找到合适的超参数是个技术活,也挺费时间。
-
数据质量问题 — 微调的效果好不好,很大程度上取决于你给模型喂的数据质量如何。如果数据不靠谱,模型学出来的效果可能也就不理想。
-
灾难性遗忘 — 有时候模型在学新东西的时候,会不小心把以前学过的重要知识给忘了,这在微调的时候就可能会发生。
-
性能不一致 — 有时候模型在处理一些特殊情况或者少见的样本时,表现可能会不稳定,或者在理解上下文的时候,如果信息太少,也会影响表现。
要解决这些问题,咱们得用上一些策略。比如,可以用网格搜索或者贝叶斯优化这样的自动化技术来调整超参数,这样能更高效地找到最佳设置。对付过拟合和灾难性遗忘,可以试试看知识蒸馏这样的技术。当然,保证数据的质量和相关性也特别重要。最后,微调的过程得持续监控,不断分析错误,然后一点点改进。这样,模型就能越学越好,越来越聪明。



















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









