







课程信息
课程主讲:王树森(史蒂文斯理工学院计算机科学系的终身制助理教授)
课程内容:基本概念、价值学习、策略学习、Actor-Critic方法、AlphaGo、Monte Carlo (蒙特卡洛)
课程资料:https://github.com/wangshusen/DRL
下载链接:https://pan.baidu.com/s/1XpTgny_Vr0LobBsuYF4KkA 密码:x0wb
B站搬运地址:https://www.bilibili.com/video/BV12o4y197US
数学基础
概率
概率密度函数(Probability Density Function,PDF)
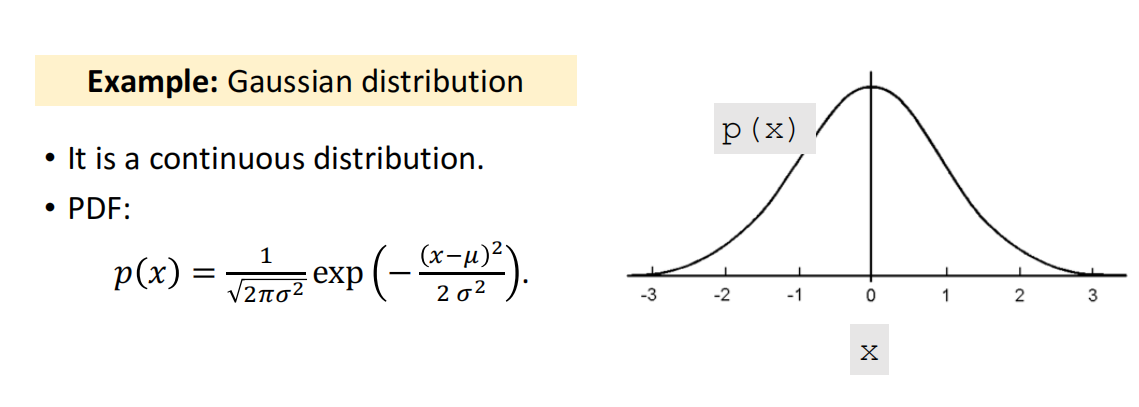
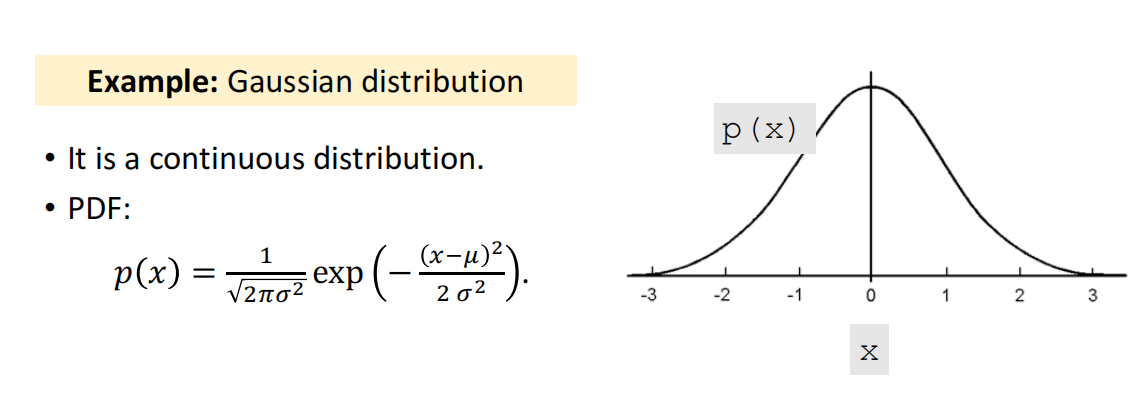
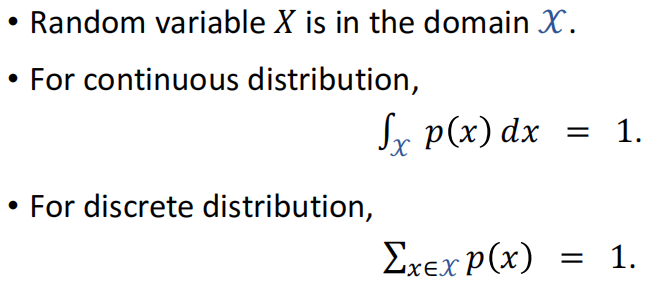
期望(Expectation)
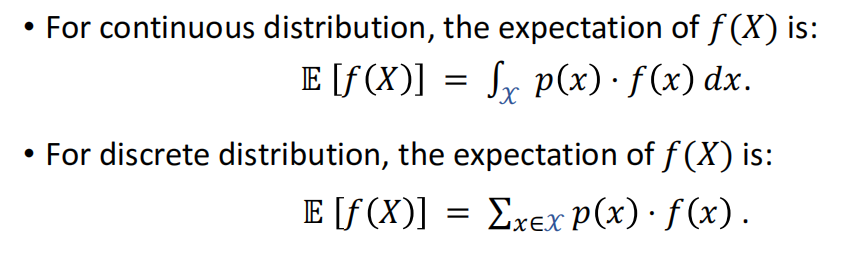
基本概念
属性
agent:操作主体,智能体
state:几个状态
action:执行动作
police:执行策略
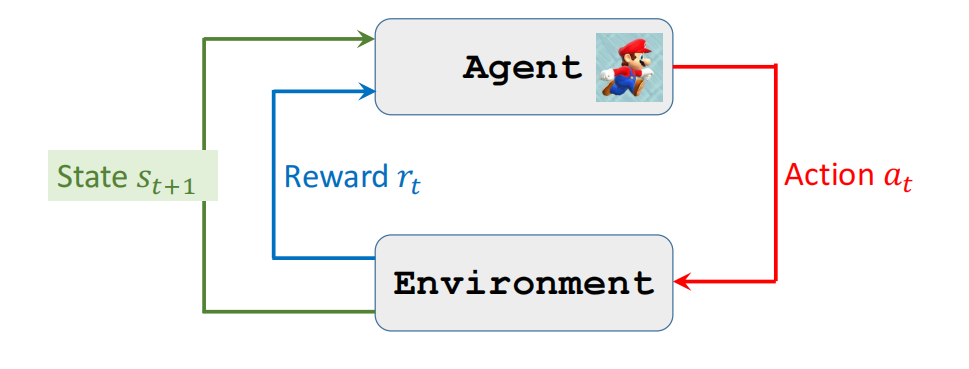
反馈
Reward

Value Function评估函数


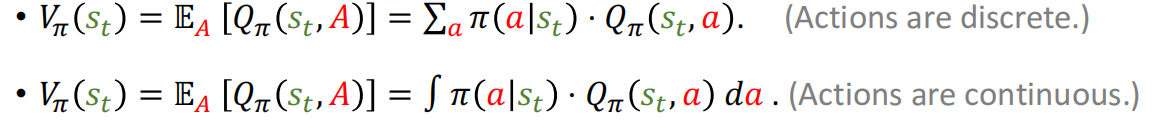

玩游戏
AI的目的就是学习
π
\pi
π函数或者
Q
Q
Q函数

gym的安装
gym官方网站:https://github.com/openai/gym
1.使用命令安装gym环境,安装所有环境
pip install gym[all] -i https://pypi.tuna.tsinghua.edu.cn/simple
2.使用如下代码进行测试
import gym
env = gym.make("LunarLander-v2", render_mode="human")
env.action_space.seed(42)
observation, info = env.reset(seed=42)
for _ in range(1000):
observation, reward, terminated, truncated, info = env.step(env.action_space.sample())
if terminated or truncated:
observation, info = env.reset()
env.close()
总结


















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











