










RL
强化学习的应用场景:何时使用强化学习?
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过与环境的交互来学习最优策略。相比于监督学习和无监督学习,强化学习在某些特定情境下具有显著优势。那么,究竟在什么情况下可以使用强化学习呢?本篇博客将详细探讨强化学习的适用场景,并提供一些实际案例来帮助理解。
强化学习的基本原理
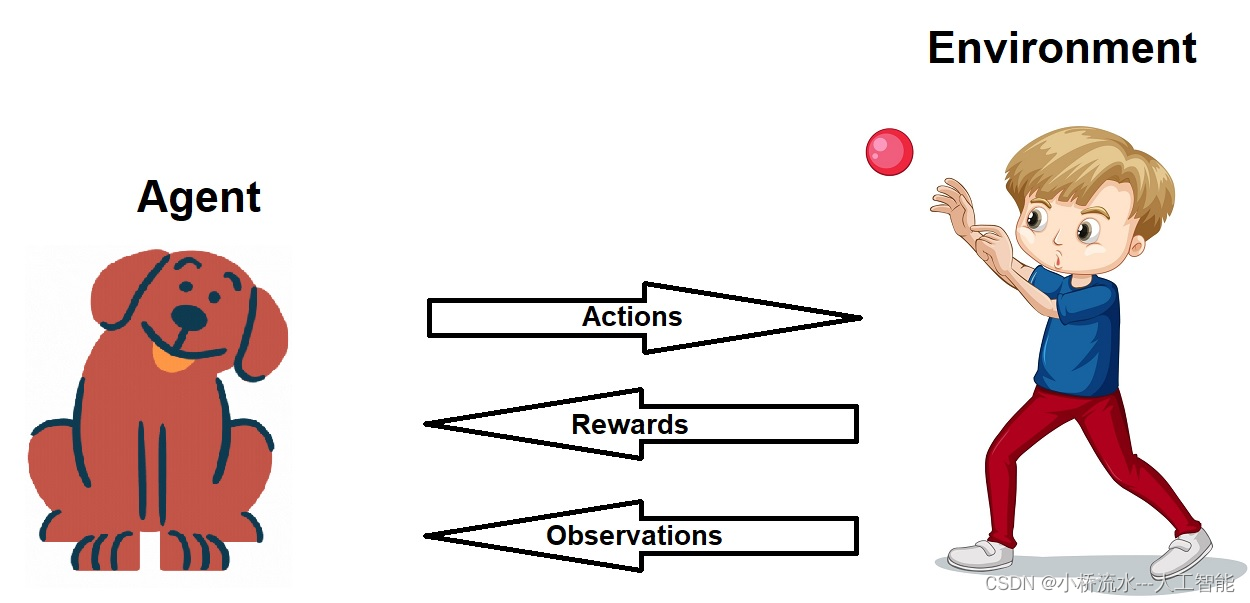
在介绍适用场景之前,我们先简要回顾一下强化学习的基本原理。强化学习通过**智能体(agent)与环境(environment)的交互来进行学习。智能体通过采取行动(action)影响环境,并根据环境反馈的奖励(reward)**来调整策略(policy)。目标是通过最大化累积奖励来找到最优策略。
强化学习的关键要素包括:
- 状态(state):智能体在某一时刻所处的具体情况。
- 行动(action):智能体在某一状态下可以采取的行为。
- 奖励(reward):智能体在采取行动后获得的反馈。
- 策略(policy):智能体在各状态下选择行动的规则。
- 价值函数(value function):预测某一状态或状态-行动对的累积奖励。
适用场景
1. 连续决策过程
强化学习特别适用于需要在多个步骤中连续决策的过程。例如,机器人控制需要在不同时间步中不断调整动作以完成任务。在这些场景中,每个决策会影响后续决策的效果,强化学习能够通过反复试验找到最优的动作序列。
2. 不完全信息
当环境的信息无法完全观测到时,强化学习能够处理部分可观测的马尔可夫决策过程(POMDP)。在这些情况下,智能体可以根据有限的信息进行推断和决策。例如,自主驾驶车辆需要在不完全了解周围环境的情况下做出驾驶决策。
3. 动态环境
当环境是动态变化的,强化学习能够通过不断学习和调整策略来适应变化。例如,金融市场是一个典型的动态环境,股票交易策略需要根据市场变化不断优化。
4. 长期回报优化
强化学习适用于那些需要最大化长期累积回报的任务。例如,在广告投放中,目标不仅是立即获得点击率,还包括用户的长期留存和转化率。通过强化学习,可以找到优化长期收益的广告策略。
5. 无明确监督信号
在一些任务中,缺乏明确的监督信号或标签数据。强化学习通过环境中的奖励信号进行自我指导和学习。例如,在游戏AI中,智能体可以通过试错法不断提高游戏策略,即使没有具体的标签数据。
实际案例
游戏AI
强化学习在游戏AI中有着广泛应用。例如,AlphaGo通过深度强化学习打败了世界顶尖围棋选手。智能体在棋盘上进行试错学习,不断优化自己的策略,最终达到超越人类的水平。
机器人控制
在机器人控制领域,强化学习帮助机器人学会复杂的动作序列。通过与环境的交互,机器人可以学会行走、抓取物体甚至进行复杂的任务,如在灾难场景中进行救援。
自主驾驶
自主驾驶汽车需要在动态环境中做出实时决策。强化学习通过不断优化驾驶策略,使得车辆能够在复杂的交通环境中安全行驶。
金融交易
在金融市场中,强化学习用于开发自动交易策略。通过分析市场数据和反馈,智能体可以学会在不同市场条件下进行交易,从而优化收益。
推荐系统
在推荐系统中,强化学习可以优化用户的长期参与度和满意度。通过分析用户的行为数据,推荐系统可以不断调整推荐策略,提供更符合用户兴趣的内容。
结论
强化学习在处理连续决策、不完全信息、动态环境、长期回报优化以及无明确监督信号等问题时具有显著优势。它通过智能体与环境的交互学习最优策略,广泛应用于游戏AI、机器人控制、自主驾驶、金融交易和推荐系统等领域。理解强化学习的适用场景有助于更好地应用这一强大的工具,解决实际问题。希望本篇博客能帮助您深入了解强化学习的应用场景,为您的研究或实际应用提供有价值的参考。

















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









