










在深度学习领域,特别是在自然语言处理(NLP)中,循环神经网络(RNN)和Transformer模型都扮演着举足轻重的角色。然而,随着技术的不断发展,Transformer模型逐渐崭露头角,成为许多NLP任务的首选。本文将详细对比这两种模型,帮助读者更好地理解它们的差异和优势。
一、RNN(循环神经网络)
RNN是一种特殊的神经网络结构,它能够处理序列数据。在RNN中,每个时间步的隐藏状态都依赖于前一个时间步的隐藏状态和当前时间步的输入。这种结构使得RNN能够捕捉序列中的依赖关系,特别适用于处理如文本、语音等具有时间顺序的数据。
优点:
- 捕捉序列依赖:RNN能够捕捉序列中的长期依赖关系,这对于处理文本、语音等序列数据非常重要。
- 参数共享:RNN中的参数在不同时间步之间是共享的,这降低了模型的复杂性和参数量。
缺点:
- 梯度消失/爆炸:由于RNN在反向传播过程中存在梯度消失或梯度爆炸的问题,这限制了RNN捕捉长期依赖的能力。
- 并行性差:RNN的序列特性使得其难以并行化,从而限制了模型的训练速度。
二、Transformer
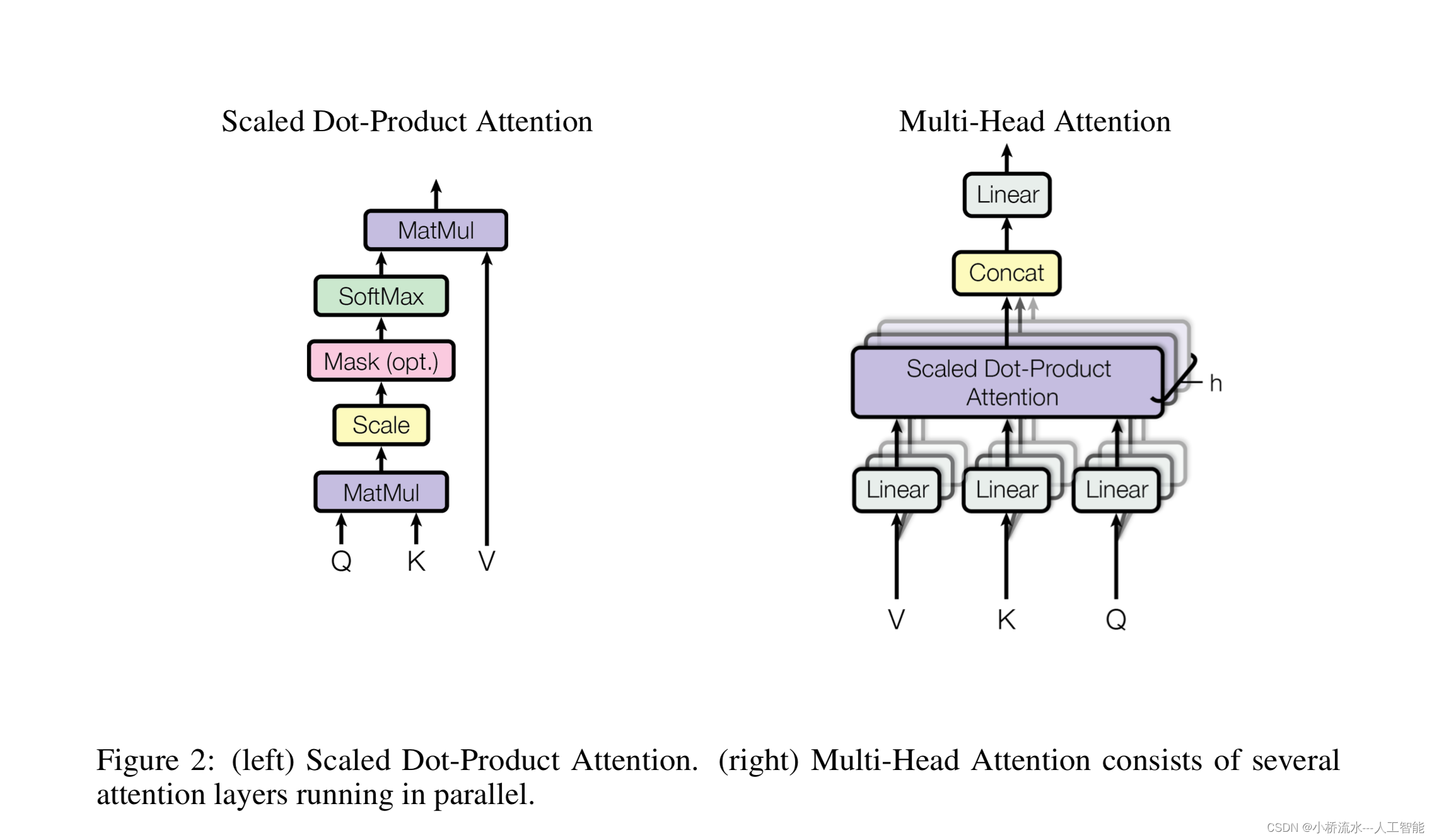
Transformer是一种基于自注意力机制的模型,它摒弃了RNN的循环结构,完全依赖于自注意力机制来处理序列数据。Transformer在多个NLP任务中都取得了显著的效果,尤其是在机器翻译等任务中。
优点:
- 捕捉长期依赖:Transformer通过自注意力机制能够捕捉序列中的长期依赖关系,克服了RNN中梯度消失/爆炸的问题。
- 并行化:Transformer的并行化能力非常强,可以大大提高模型的训练速度。
- 自注意力机制:Transformer中的自注意力机制能够同时关注序列中的所有位置,从而更好地捕捉序列中的全局信息。
缺点:
- 计算复杂度:Transformer的计算复杂度较高,特别是当序列长度较长时,其计算量会显著增加。
- 位置信息:Transformer本身不包含位置信息,需要通过额外的位置编码来补充。
三、RNN与Transformer的对比
- 结构差异:RNN采用循环结构来捕捉序列中的依赖关系,而Transformer则完全依赖于自注意力机制。这种结构差异使得Transformer在处理长序列时更具优势。
- 依赖捕捉:RNN在处理长序列时容易遇到梯度消失/爆炸的问题,导致难以捕捉长期依赖。而Transformer通过自注意力机制能够很好地捕捉长期依赖。
- 并行化:RNN的序列特性使得其难以并行化,而Transformer则具有很强的并行化能力,可以大大提高模型的训练速度。
- 全局信息:Transformer中的自注意力机制能够同时关注序列中的所有位置,从而更好地捕捉序列中的全局信息。而RNN在捕捉全局信息方面相对较弱。
总结
RNN和Transformer都是处理序列数据的强大工具,但它们在结构、依赖捕捉、并行化和全局信息捕捉等方面存在显著差异。在实际应用中,我们可以根据任务的特点和需求选择合适的模型。对于需要捕捉长期依赖和全局信息的任务,Transformer可能是一个更好的选择;而对于一些简单的序列处理任务,RNN仍然是一个有效且经济的解决方案。

















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









