







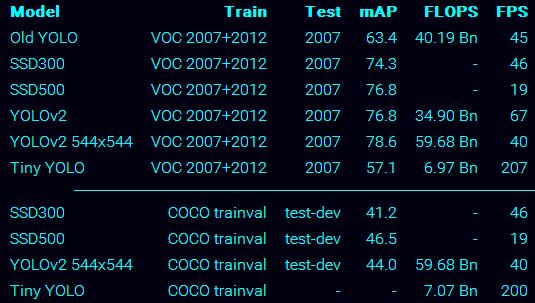
从下图可以看出,YOLOv2不管是速度还是精度都超过了SSD300,和YOLOv1相比,确实有很大的性能的提升。这名字也起的darknet,就跟黑魔法一样,是那么的奏效,不得不佩服老外的起名啊。
论文思想篇:
该论文为YOLO9000:Better, Faster, Stronger
非常值得一看的论文。
Better:
batch Normalization:在卷基层后面增加了batch Normalization,去掉了dropout层,mAP提升2%。
High ResolutionClassifier:x训练网络的时候将网络从224*224变为448*448,当然后续为了保证特征图中只有基数个定位位置,从而保证只有一个中心细胞,网络最终设置为416*416。最终实现了4%的mAP提升。
Convoutional with AnchorBoxes:作者吸收了faster RCNN中RPN的思想,去掉了yolov1中的全连接层,加入了anchor boxes,这样做的目的就是得到更高的召回率,当然召回率高了,mAP就会相应的下降,这也是人之常情。最终,yolov1只有98个边界框,yolov2达到了1000多个。mAP由69.5下降到69.2,下降了0.3,召回率由81%提升到88%,提升7%。
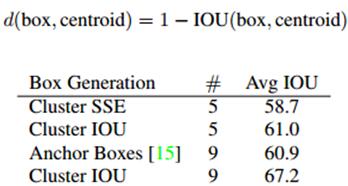
Dimension Clusters:这里作者提出了kmeans聚类,这里的K作者取值为5,这样会在模型复杂度和召回率之间达到一个好的折中。并且使用聚类的中心代替Anchor,最后使用欧式距离进行边界框优先权的衡量,欧式距离公式如下所示,距离越小说明优先权越高。在k为5 的条件下,Avg IOU从60.9提升到了61.0。在k为9的的条件下Avg IOU提升为67.2
Direction locationprediction:
引入了anchor boxes就会产生模型不稳定的问题,该问题产生于边界框位置的预测。简单的解释,如果训练的图片中的物体一张是在左面,下一张又在右面,就会产生这样的波动,显然的这个过程是不受控制的,毕竟图片中的物体位置他在哪里就在哪里。这里作者,变换了个思路,把最终预测的相对于anchor的边界框的相关系数变为预测相对于grid cell(yolo v1的机制)的相关系数,使得输出的系数在0-1直接波动,如此就解决了波动的问题。最终,使用维度聚类和直接预测边界框中心比使用anchor boxes提升了5%的mAP。(这里我可能解释的也不是很清晰,还是有点不太好表达,希望还是多看看论文,论文才是第一手的资料)。
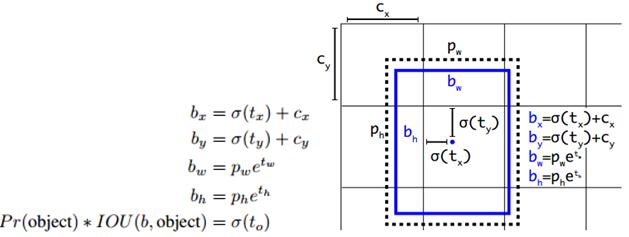
首先,yolov2边框的表示方式通过框的中心坐标bx,by,和框的宽bw,高bh这4个变量来表示。实际预测的值为tx,ty,tw,th。
由tx,ty,tw,th得到bx,by,bw,bh的详细公式如上图,其中,
cx,cy为框的中心坐标所在的grid cell 距离左上角第一个grid cell的cell个数。
tx,ty为预测的边框的中心点坐标。
σ()函数为logistic函数,将坐标归一化到0-1之间。最终得到的bx,by为归一化后的相对于grid cell的值
tw,th为预测的边框的宽,高。
pw,ph为anchor的宽,高。实际在使用中,作者为了将bw,bh也归一化到0-1,实际程序中的 pw,ph为anchor的宽,高和featuremap的宽,高的比值。最终得到的bw,bh为归一化后相对于anchor的值
σ(t0)表示预测的边框的置信度,为预测的边框的概率和预测的边框与ground truth的IOU值的乘积。
Fine-Grained Features:有别于faster rcnn和SSD采用多尺度的特征图进行预测,yolov2提出了一个全新的思路,作者引入了passthrough layer,这个层的作用就是将上一层特征图的相邻像素都切除一部分组成了另外一个通道。例如,将26*26*512的特征图变为13*13*2048的特征图(这里具体的实现过程需要看作者的源码,但是,为了解释这个变化过程,可以做这样的解释,就是将一个26*26的图的像素放到4个13*13的图中,水平每2个像素取1个,垂直也是每2个像素取一个,一共就可以得到2*2=4个,512*4=2048),使得特征图的数目提高了4倍,同时,相比于26*26的特征图,13*13的特征图更有利用小目标物的检测,
该改进使得mAP提升1%。
Multi-Scale Training:这里作者提出的训练方法也很独特,在训练过程中就每隔10batches,随机的选择另外一种尺度进行训练,这里,作者给出的训练尺度为{320,352,……,608},这个训练的方法,使得最终得到的模型可以对不同分辨率的图像都能达到好的检测效果。
Faster:
这里,vgg16虽然精度足够好,但是模型比较大,网络传输起来比较费时间,因此,作者提出了一个自己的模型,Darknet-19。而darknetv2也正式已Darknet-19作为pretrained model训练起来的。
Stronger:
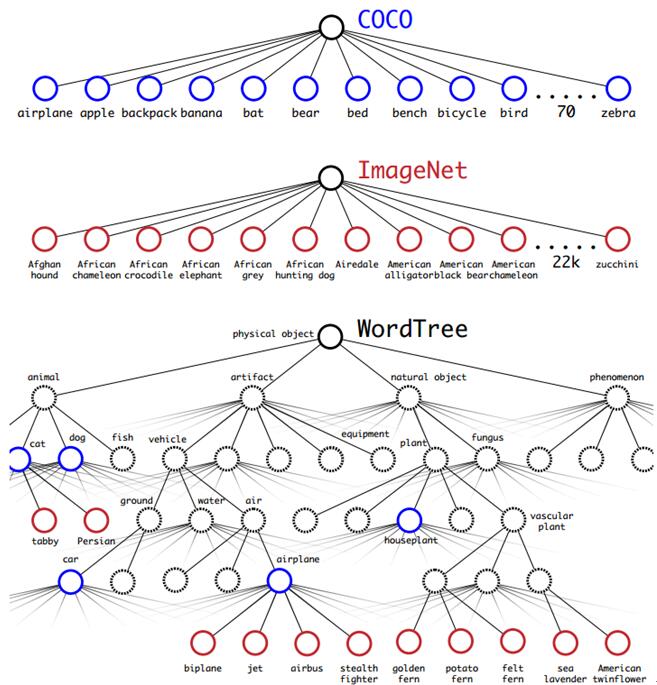
这里作者的想法也很新颖,解决了2个不同数据集相互排斥(mutualy exclusive)的问题。作者提出了WordTree,使用该树形结构成功的解决了不同数据集中的排斥问题。使用该树形结构进行分层的预测分类,在某个阈值处结束或者最终达到叶子节点处结束。下面这副图将有助于WordTree这个概念的理解。
linux篇:
安装步骤:
git clone https://github.com/pjreddie/darknet
cd darknet
vim Makefile
修改,GPU=1 OPENCV=1
wget http://pjreddie.com/media/files/yolo.weights
make
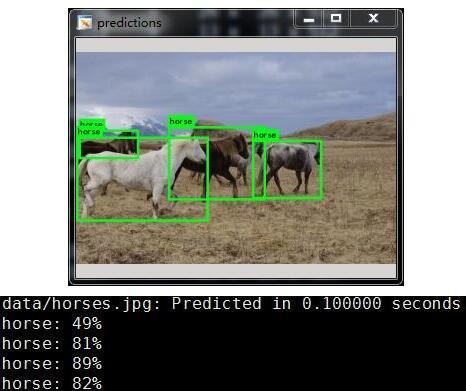
./darknet detect cfg/yolo.cfg yolo.weights data/horses.jpg
运行效果:
测试环境centos+titanx
程序下载链接:
https://github.com/pjreddie/darknet
http://pjreddie.com/darknet/yolo/
windows篇:
windows下的修改,主要就是将一些变量的定义放在每个函数的最前面即可。整个修改过程不是很难,参考darknetv1的修改,完全可以改出darknetv2 的windows的版本。
这里就不在赘述修改细节,有疑问欢迎留言。
最后贴一个cpu和gpu下运行的时间和效果图
进入到darknetv2根目录,运行下面的命令,
darknet.exe detect ./cfg/yolo.cfg yolo.weights ./data/horses.jpg
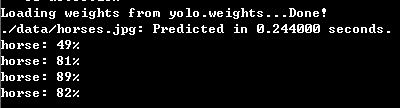
结果如下,运行环境,win7+至强E3cpu+750ti大将,左面为GPU版本,右面为CPU版本,
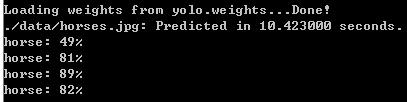
使用cudnn编译后,运行时间,左面为yolo模型,右面为tiny-yolo模型(cudnn版本为v5.1)


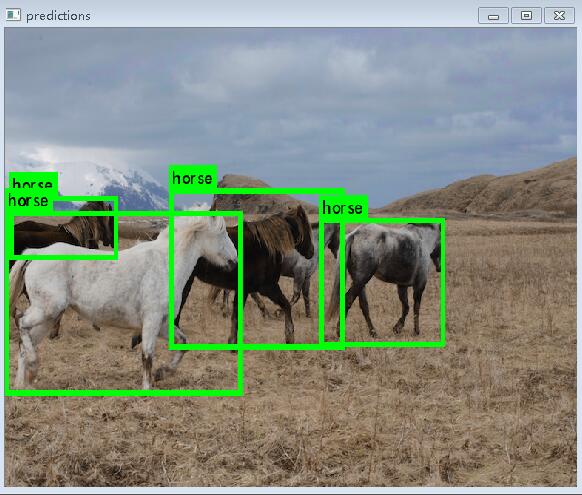
和darknetv1相比,很大的区别就是v1原来的模型750M,2G显存的显卡根本跑不起来,现在v2的模型变小,就可以跑起来了,从速度上来看,还是有点慢,和SSD的速度相比,直接差了1半,这里想说一下,为什么论文中写的速度比ssd快,而测试下不是呢?因为上面的测试都是没有使用cudnn,如果使用的这个,速度会快很多。
windows版本的链接大家可以参考,https://github.com/AlexeyAB/darknet
训练篇:
这里假定我要实现一个简单的人脸检测。
(1)首先就是数据集的准备,这里建议使用python+QT开发的抠图小工具,labelImg。
(2)模仿VOC的格式建立相应的文件夹,执行,
tree -d
目录结构显示如下,
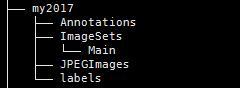
其中,my2017为我自己的数据集起的名字,你也可以起别的名字,Annotations存放XML文件,Main中存放,train.txt,val.txt,test.txt,txt中只写图片的名字,一行一个。JPEGImages中存放图片。labels中存放由XML生成的txt文件。
(3)修改scripts下面的voc_label.py,将数据集的目录修改为自己的目录,然后执行
python voc_label.py就会生成labels文件夹,以及文件夹下面的txt标记。

(4)修改,cfg/voc.data
class为训练的类别数
train为训练集train.txt
valid为验证集val.txt
names为voc.names,里面为自己训练的目标名称
backup为weights的存储位置
classes= 1
train = /dataSet /2017_train_all.txt
valid = /dataSet /2017_val.txt
names = /opt/darknetv2/data/voc.names
backup = /home/darknet_result_tiny_all/
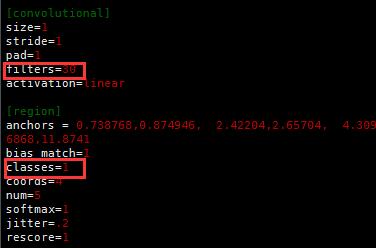
(5)修改cfg/tiny-yolo.cfg
最后一个卷基层,filters和最后一个region的classes,
其中,filters=num×(classes + coords + 1)=5*(1+4+1)=30,这里我只有1个类别。
(6)执行下面的语句进行训练,
./darknet detector train ./cfg/voc.data ./cfg/tiny-yolo.cfg ./darknet19_448.conv.23
训练完毕就可以生成weights文件,
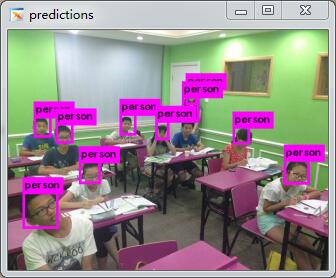
(7)测试,执行下面语句,
./darknetdetect ./cfg/tiny-yolo.cfg /home/darknet_result_tiny_all/tiny-yolo_final.weights ./data/jiaoshi.jpg运行结果如下,















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









