








Convolutional Recurrent Neural Network(CRNN),华科白翔老师组的作品,An End-to-End Trainable Neural Network for Image-based Sequence Recognition and ItsApplication to Scene Text Recognition
整体流程:
CNN+biLSTM+CTC

网络结构:

网络的结构综合了CNN+RNN,
(1) 其中Max pooling中的窗口大小为1*2,保证提出的特征具有横向的长度,有利于比较长的文本的识别
(2) CNN+RNN的训练比较困难,所以加入了BatchNorm,有助于模型收敛
(3) 在300dpi的分辨率下,一个中文汉字的宽度大约为50pix,一个英文字母的宽度大约为20pix,作者上面提供的网络模型,经过4个pooling和最后一个卷积(valid模式),总共会使得原图的宽度缩小pow(2,5)倍,即缩小32倍。而实际使用中,假设都使用一个像素预测一个结果,一个英文字母最多可以缩小20倍,一个中文最多可以缩小50倍。所以作者32倍的缩放对英文会有问题。我这里的建议是,将第三个或者第四个pooling的stride改为(1,2),这样就会使得最终的宽度只缩小16倍。从而满足实际需要。
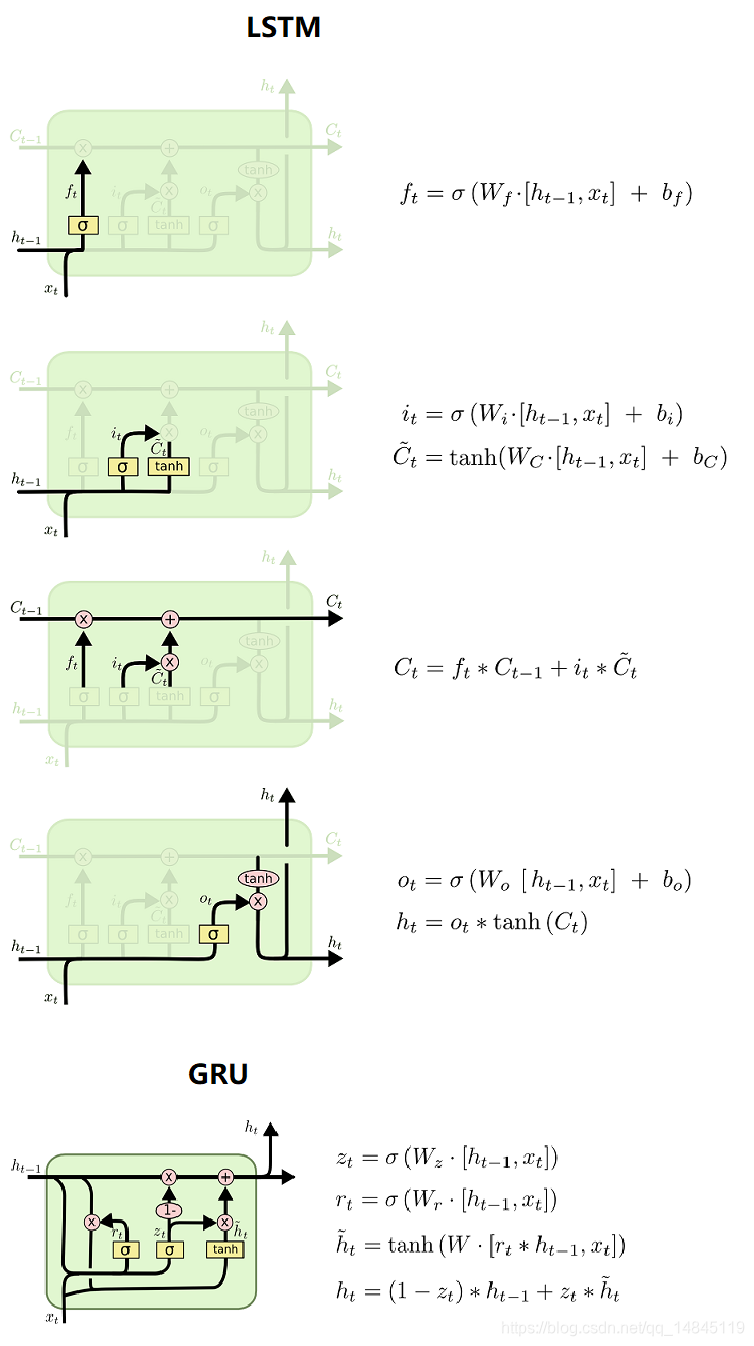
LSTM,GRU结构:
lstm包含3个sigmoid,2个tanh,一个加法操作,4个全连接,共6个公式,
gru包含2个sigmoid,1个tanh,一个加法操作,2个全连接,共4个公式,
优势:
(1) 可以端到端训练
(2) 不需要进行字符分割和水平缩放操作,只需要垂直方向缩放到固定长度既可,同时可以识别任意长度的序列
(3) 可以训练基于词典的模型和不基于词典的任意模型
(4) 模型速度快,并且很小,本人原始ckpt模型100M,固化后40M,量化后只有10M。
自己的一些改进:
(1)网络最开始的1~2层使用crelu操作,可以节省前1~2层的一半计算量。
(2)使用stride=2的卷积代替pooling操作,会有一点点精度的损失,但是可以减少一半计算量。
(3)使用1维卷积替换lstm,可以实现加速,精度基本不变。当然也会引入一些变化,主要表现在训练更容易发散。因此这个操作之后,需要将学习率较修改前加倍的下降。这样来保证持续稳定的训练。
(4)对于英文法文中空格,多字母,少字母的情况,引入EP loss(Edit Probability),参考论文Edit Probability for Scene Text Recognition,提升明显
(5)IBN结构,提升明显
(6)DropBlock结构,提升明显
(7)生成数据和真实数据由易到难的混合交叉训练,提升明显
(8)对于阴阳文字,背景前景反转,等问题,引入随机数乘加操作,提升明显
(9)对于有下划线的文字,大量标注有下划线的真实样本,提升明显
(10)需求:手机拍照的图片会有方向的问题在里面,需要有4个角度的纠正(0,90,180,270)。但是0度和180度,90度和270度是很难纠正。这里采用识别结果的反馈进行纠正。
首先一张正的图片经过ctc解码后会输出predict sequence和prob。将该图片倒转180度也会输出这2个结果,但是这样输出的置信度prob将会比原来正着的大。(因为tf默认的prob是所有识别序列中最大的一个值的log,输出的值为负值,越小越好)。这时会引入一个问题,只根据这个值也可以进行判别,但是准确性不高。这时就需要对解码这部分进行修改,不是输出最大值的log,而是输出了所有值的sigmoid,然后求mean操作,这样就会得到这样的结论。正的图片预测的prob将会比翻转180度的该值要高(输出的值为0~1的正值,越大越好)。
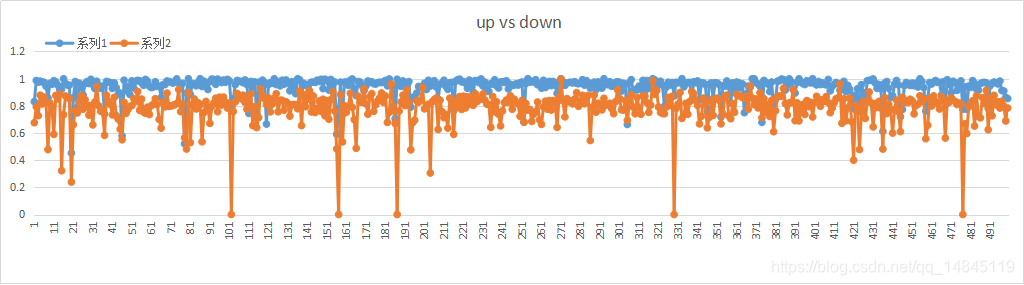
上图是使用500张图片进行验证的结果(蓝色表示正着的图片行,红色表示反着180度的图片行)。证明该改进的可行性。
然后对网络结构进行修改,最后的全连接层之前,将featuremap翻转180度,这样分别通过2个全连接层,同时输出原始图片和翻转180度后图片的结果。也就是说,只需要1次的网络前向,就可以同时获得2个结果,然后取得分高的结果就可以。
这样即使角度分类错误,也可以通过识别进行纠正。这个改进除了可以获得1次forward收益2个结果外,还可以对原来的模型有一定精度的提升。
(11)将单字分割和crnn识别相结合,最终可以得到每个字的位置,并且分割的结果和crnn识别的结果相互对应,不会出现分割出4个字,识别出5个字,或者各种位置不对应的情况。最终一遍网络前向就可以得到识别结果和单字位置信息。


其中红色为检测的文本行框,绿色为分割的结果。
(12)基于0,1编码的空格loss,可以大大改善英文中空格的识别率,5%个点的猛升。
References:
http://mc.eistar.net/~xbai/CRNN/crnn_code.zip
https://github.com/bgshih/crnn
https://github.com/Belval/CRNN


















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









