







深度学习技术的迅速发展为我们带来了前所未有的机遇和挑战。许多从业者,无论是初学者还是有经验的开发者,都是在这一技术快速发展的某个阶段开始他们的学习之旅。然而,我在实践中发现,很多人在训练过程中并没有充分利用硬件资源,也常常对如何识别和解决硬件瓶颈感到困惑。为此,我撰写了这篇博客,旨在帮助更多的初学者和那些不清楚如何发现和解决硬件瓶颈的从业者。通过这篇文章,我希望能提供一些有效的方法和策略,使大家能以最小的成本和代价,有效地识别训练中的瓶颈,从而充分发挥硬件的潜力,优化模型训练过程。—— AI Dreams, APlayBoy Teams!
博客首发地址:一文搞懂深度模型训练中的硬件瓶颈分析 - 知乎
目的
现在,我们将深入探讨在深度学习模型训练过程中可能遇到的各种硬件瓶颈,包括GPU、CPU、内存和IO瓶颈。我们不仅会分别分析这些硬件资源在训练过程中的作用和瓶颈表现,还将讨论如何进行整体硬件资源的分析,以确保它们协同工作,最大限度地提高训练效率。
直接目的:提高GPU使用率
-
核心目标:充分发挥GPU的计算潜力,以加快模型训练。
-
实施策略:包括调整批量大小以提供更多并行任务给GPU,优化数据预处理和加载流程以减少等待时间,以及选择或设计与GPU并行处理能力相匹配的模型架构。
间接目的:全面提升性能
-
加速训练过程:通过高效的硬件利用,显著减少模型的训练时间。
-
提高资源利用率:合理分配CPU、GPU、内存和存储资源,以提高整体的成本效益。
-
增强模型质量:更快的训练速度和更优的资源配置使得模型实验更加广泛,有助于提升模型的性能和准确度。
-
确保稳定性与可靠性:优化硬件配置可减少因资源限制导致的训练中断或失败,保障训练流程的顺利进行。
-
降低能耗:提高硬件效率的同时降低能源消耗,符合环保要求并减少运营成本。
-
减少训练成本:通过高效的硬件利用,降低长期的训练费用,实现经济高效的模型训练。
GPU瓶颈分析
分析命令
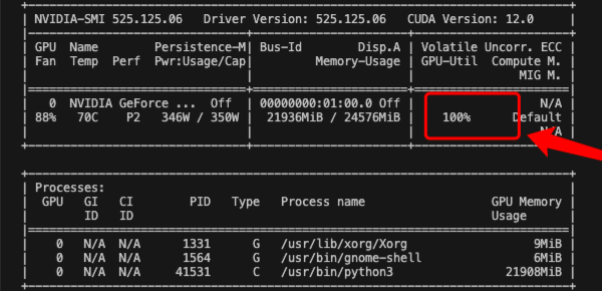
nvidia-smi 是 NVIDIA 提供的一个非常强大的工具,用于监控和管理与 NVIDIA GPU 相关的各种信息。在深度学习中,它经常被用来查看显存使用情况、GPU利用率等,以此判断模型训练的状态。以下是 nvidia-smi 输出的一些关键指标以及如何根据这些指标判断模型训练状态:
-
GPU利用率(GPU-Util): 这个指标显示了GPU的利用率百分比。在模型训练时,理想情况下这个数字应接近100%,这意味着GPU资源被充分利用。如果这个数值较低,可能意味着GPU没有被充分利用,或者训练过程受到CPU或IO(输入输出)的限制。
-
显存使用(Memory-Usage): 这个指标显示了GPU显存的使用情况。显存的充分利用往往是高效训练的关键。如果显存使用率很高,接近GPU显存的上限,可能会导致显存溢出错误。而如果显存使用率很低,则可能意味着模型没有充分利用GPU资源。
-
温度(Temp): 显示GPU的当前温度。过高的温度可能会导致GPU性能降低,甚至自动降频以防过热。
-
功率使用(Power Usage): 显示GPU的当前功率使用情况。功率的使用可以间接反映GPU的工作负载。
-
风扇速度(Fan Speed): 显示风扇速度,这也是一个检查GPU工作是否过热的指标。
判断模型训练状态
-
GPU利用率低:可能意味着GPU等待CPU处理数据,或者IO速度成为瓶颈。这种情况下,可能需要优化数据加载过程,使用更快的数据预处理方法,或者提高数据批量大小。
-
显存使用过高:可能导致显存溢出错误。可以尝试减小批量大小或简化模型。
-
显存使用过低:可能没有充分利用GPU资源。可以尝试增大批量大小或使用更复杂的模型。
-
温度过高:可能需要检查机箱的散热情况,或降低GPU的工作负载。
通过 nvidia-smi 提供的这些信息,我们可以对模型的训练状态进行初步的判断,并对训练过程进行相应的调整。下面我针对具体现象和可能出现的原因来做分析:
原因分析
单个GPU利用率低的原因
-
CPU瓶颈:CPU处理数据速度跟不上GPU,导致GPU等待。
-
IO限制:数据从硬盘或网络到GPU的传输速度慢。
-
小批量大小:批量大小设置过小,GPU未充分利用。
-
模型复杂度:简单模型可能无法充分利用GPU能力。
-
内存带宽限制:数据从内存到GPU的传输速度成为限制因素。
多个GPU利用率低的原因
-
全局数据处理瓶颈:所有GPU都在等待数据处理或加载。
-
网络通信瓶颈:分布式训练中的网络带宽不足。
-
不适当的并行策略:数据并行或模型并行策略设置不当。
-
软件框架和驱动问题:深度学习框架或GPU驱动配置不佳。
多个GPU间歇性空闲的原因
-
异步数据处理问题:数据加载和预处理的不连续性。
-
模型同步问题:模型并行中的GPU等待其他GPU同步。
-
负载不均衡:工作分配给各GPU不均匀。
解决策略
-
优化数据处理和IO:加速数据处理和加载,减少GPU等待时间。
-
调整批量大小:增加批量大小以提高GPU利用率。
-
平衡模型复杂度和GPU能力:选择或设计合适复杂度的模型。
-
优化网络和并行策略:在分布式训练中优化网络带宽和数据/模型并行策略。
-
调优软件和硬件配置:确保深度学习框架和GPU驱动配置正确。
-
负载均衡:确保工作在各GPU间均匀分配。
通过这些策略,无论是单GPU还是多GPU环境,都可以有效提高GPU的利用率,确保训练过程高效稳定。总的来说,理解和优化GPU利用率涉及对整个训练流程的细致考量,包括数据处理、模型设计、并行策略以及硬件和软件的配置。
CPU和内存瓶颈分析
htop解释
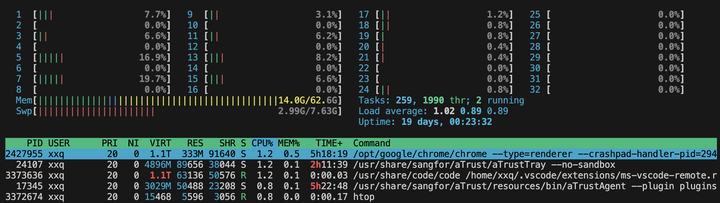
htop 是一个在许多Linux系统上常用的交互式进程查看器,它提供了一个详细且动态的视图,展示了系统中正在运行的进程及其资源占用情况。当用于分析CPU瓶颈时,以下是 htop 命令输出的一些关键指标以及它们的解释:CPU使用率:
-
htop 显示了系统中每个CPU核心的使用率。
-
如果所有核心的利用率都很高,这可能表示CPU正在满负荷运行。
-
高CPU使用率可能意味着CPU是模型训练的瓶颈,尤其是当GPU等待CPU处理数据时。
内存使用率:
-
htop 提供了当前内存(RAM)使用量的信息。
-
如果内存使用率非常高,可能会影响CPU的数据处理效率,因为系统可能需要使用慢速的交换空间(swap)。
进程信息:
-
列出了系统中所有正在运行的进程,包括PID(进程ID)、用户、优先级、内存占用等信息。
-
可以通过观察哪个进程占用了大量CPU资源来确定是否是训练过程造成的负载。
负载平均值:
-
显示了过去1分钟、5分钟和15分钟的平均负载值。
-
负载平均值高于CPU核心数通常意味着有过多的进程等待CPU资源,可能是瓶颈的迹象。
线程和优先级:
-
显示每个进程的线程数和优先级,帮助了解并发执行情况。
-
过多的线程可能导致上下文切换频繁,影响CPU效率。
判断模型训练状态
CPU 使用率:
-
观察CPU核心的使用率。如果大部分或所有核心的使用率接近100%,表明CPU正在高强度工作,很可能成了来训练的瓶颈。这可能意味着模型训练正处于密集的计算阶段,
-
如果CPU使用率较低,可能表明CPU不是训练过程的瓶颈,或者训练过程可能正在等待GPU处理、数据加载或其他IO操作。
内存使用率:
-
检查内存占用情况。如果内存使用率很高,接近或达到系统的最大容量,可能导致交换使用(swap usage),这会显著减慢训练速度。
-
内存使用率较低可能表明内存资源充足或数据集规模较小。
进程和线程:
-
查看与模型训练相关的进程,如Python或其他深度学习框架的进程。高CPU使用率的相关进程可能表明模型正在进行密集的训练计算。
-
进程的线程数也可以提供信息。大量线程可能意味着并行处理正在进行,但也可能导致上下文切换,影响效率。
系统负载平均值:
-
系统的负载平均值高于CPU核心数通常表明系统过载,可能是由于模型训练导致。
其他指标:
-
检查是否有频繁的上下文切换或I/O等待,这些也可能影响模型训练的效率。
解决策略
1. 高CPU使用率
-
优化模型代码:优化数据预处理和模型代码,提高计算效率。
-
多线程或多进程:在数据加载和预处理阶段使用多线程或多进程,以更好地利用多核CPU。
-
减轻CPU负担:如果可能,将一些计算任务转移到GPU上,特别是对于可以并行化的任务。
2. 内存使用率高
-
减少数据批量大小:降低批量大小可以减少每次训练迭代中的内存需求。
-
优化数据管道:确保数据管道高效,避免不必要的数据复制和存储。
-
使用数据生成器:使用数据生成器而非一次性加载整个数据集到内存中。
3. 高I/O等待
-
使用更快的存储介质:如使用SSD代替传统HDD。
-
预加载数据:在训练前预加载数据到内存中,减少读取时间。
-
改进数据格式:使用更高效的数据格式,如HDF5,减少加载和解析数据的时间。
4. 高系统负载
-
负载均衡:如果系统运行了多个重负载进程,尝试减少同时运行的任务数量。
-
优化训练配置:调整训练参数(如批量大小、学习率等),避免过度负载。
5. 过多的上下文切换
-
优化线程数量:调整线程数量,避免创建过多的线程导致频繁的上下文切换。
6. 处理其他问题
-
更新软件和库:确保使用的深度学习框架和相关库是最新版本,以利用最新的性能优化。
-
硬件升级:在必要时,考虑升级CPU或增加内存容量。
IO瓶颈分析
如果通过分析确认CPU和内存并不是训练瓶颈,那么IO(输入/输出)瓶颈可能是导致模型训练效率低下的原因之一。IO瓶颈通常发生在数据从存储设备加载到CPU或GPU的过程中。以下是可能表明IO瓶颈的情况,以及如何进行分析:
iotop解释
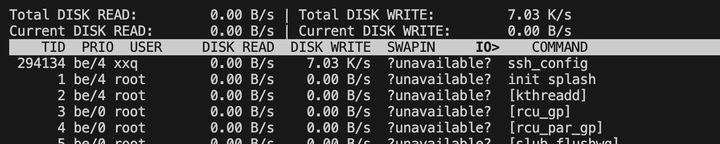
iotop 是一个用于监控磁盘I/O使用情况的工具,类似于 top,但专注于I/O操作。使用 iotop,您可以看到哪些进程正在对磁盘进行读写操作,以及这些操作的强度。以下是 iotop 命令输出的关键指标解释以及如何用它来分析IO瓶颈:
-
总I/O带宽使用:显示所有进程的总I/O带宽使用情况,包括读写速度。
-
单个进程的I/O:列出单个进程的I/O使用情况,包括进程ID、用户、读写速度和I/O百分比。
-
I/O类型:显示I/O操作的类型,如磁盘读、磁盘写或交换操作。
-
排序和过滤:可以按I/O使用率排序或过滤显示特定类型的进程,以便更容易地识别高I/O使用的进程。
判断模型训练状态
1. 监控和评估I/O活动
-
使用iotop监控:利用 iotop 持续监控磁盘的读写活动,观察I/O使用率和等待时间。
-
比较I/O活动与磁盘性能上限:了解所使用磁盘的最大I/O能力(包括读写速度上限),并将其与实时监控数据进行比较。如果I/O使用远低于磁盘的性能上限,那么I/O可能不是瓶颈。
2. 分析模型和数据需求
-
理解模型需求:分析模型训练过程中对数据的需求。某些类型的训练,如大规模图像或视频处理,自然需要更高的I/O吞吐量。
-
考虑数据预处理:评估数据预处理步骤是否在I/O阶段造成瓶颈,如复杂的数据增强或转换操作。
3. 识别和解决潜在问题
-
I/O瓶颈确认:如果I/O使用接近或达到磁盘性能上限,且伴随CPU和GPU利用率不高,则I/O可能是瓶颈。
-
硬件升级:如果硬件是限制因素,考虑使用更快的存储设备,例如固态硬盘(SSD)。
-
优化数据管道:改进数据加载和预处理策略。考虑使用更高效的数据格式,减少不必要的数据操作,或实现更好的并行数据加载。
4. 持续监控和调整
-
动态调整策略:根据训练进度和资源使用情况动态调整数据处理和存储策略。
-
长期观察:即使当前未发现明显的I/O瓶颈,也应持续监控I/O性能,因为随着数据量和模型复杂度的变化,I/O需求可能会增加。
解决策略
1. 改进数据存储格式
-
合并小文件:将多个小数据文件合并成较大的单个文件,以减少磁盘寻道时间和提高读取效率。
-
采用高效文件格式:使用如HDF5或TFRecord这类支持高效读写的文件格式,这些格式优化了大规模数据集的存储和访问。
2. 优化数据读取机制
-
预加载和缓存:在训练开始前预加载数据到内存中,或者实现数据缓存机制,以减少对磁盘的依赖。
-
并行读取:使用多线程或异步I/O来并行读取数据,特别是从大文件中读取时,这可以显著提高I/O效率。
3. 硬件改进
-
升级存储设备:使用SSD代替HDD,因为SSD具有更快的读写速度和更低的寻道时间。
-
增加内存容量:更多的内存意味着可以将更多数据预加载到内存中,减少读取次数。
4. 网络存储优化
-
提高网络带宽:如果数据存储在远程服务器或云平台上,确保网络带宽足够高,以避免网络成为瓶颈。
-
优化网络存储协议:使用高效的网络存储协议和配置,如NFS或iSCSI,根据存储和网络环境进行优化。
5. 数据流水线调整
-
调整数据管道:优化数据加载和预处理的管道,减少不必要的数据操作,确保管道中的每一步都尽可能高效。
-
平衡计算和I/O:在数据管道设计时,平衡计算密集型操作和I/O操作,避免任何一方成为瓶颈。
6. 持续监控和调整
-
性能监控:持续使用工具如 iotop 监控I/O性能,确保所做的优化有效。
-
动态调整:根据实时的监控结果和训练需求调整存储策略和数据处理流程。
整体硬件资源分析过程
1 系统资源使用监控
-
利用 htop 和 nvidia-smi 等工具监控CPU和GPU的使用率,以及内存占用情况。高利用率可能意味着这些资源被充分利用,而低利用率则可能指示存在瓶颈或不平衡的资源分配。
2 I/O性能分析
-
使用 iotop 或相似工具监控磁盘I/O活动。持续的高I/O使用或长时间的I/O等待可能表明磁盘速度是训练效率的限制因素。对于基于网络的数据存储或分布式训练,还应考虑网络带宽和延迟的影响。
3 资源匹配与平衡
-
确保CPU和GPU之间性能匹配,避免任一方成为瓶颈。同时,检查并确保系统资源如CPU核心被均衡使用,以提高整体效率。
4 模型和数据管道分析
-
评估模型架构的复杂度是否与当前硬件配置相匹配,并分析数据预处理和加载步骤的效率。考虑是否可以通过优化这些步骤来提高整体训练效率。
5 性能瓶颈诊断
-
使用专业的性能分析工具进行深入诊断,以便更精确地定位瓶颈。根据分析结果,尝试调整训练参数和硬件配置。
6 综合评估与优化
-
综合所有监控和分析数据,全面评估硬件资源的使用情况。根据这一综合评估,制定并实施针对性的优化策略,如硬件升级、数据管道优化或模型调整。
通过这一详细的分析过程,可以全面了解深度学习训练中的硬件资源使用状况,并有效地识别和解决性能瓶颈。这不仅有助于提高训练效率,还能确保资源得到最佳利用。
结束语
非常感谢您花时间阅读到这里。希望这篇博客能为您在深度学习训练过程中的硬件资源分析提供一些有用的见解和方法。无论您是初学者还是经验丰富的专业人士,有效的资源分析总是能带来训练效率的显著提升。每次训练都是一个学习和成长的机会,不仅仅是对机器学习模型的训练,也是对我们自己的训练。在这个快速发展的领域中,不断学习和适应是必不可少的。愿这些信息能助您一臂之力,在深度学习的世界里更加自如地驾驭技术挑战。再次感谢您的阅读,期待与您共同成长于这个充满可能的领域!
在本篇6000字的AI探索之旅的尾声,感谢每位朋友的陪伴,我的所有博客首先在知乎发布,如果大家有疑问、见解,欢迎留言、讨论。您的点赞、关注是我持续分享的动力。APlayBoy,期待与您一起在AI的世界里不断成长!

















 7894
7894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









