






论文地址:https://arxiv.org/abs/2209.02976
代码地址:https://github.com/meituan/YOLOv6
论文小结
YOLOv6是Anchor free检测器。来自于美团团队,是一个工业级应用的产物。由于早期一些命名问题,所以论文提出时的对比实验有与YOLOv7检测器的对比,后YOLOv6被YOLO团队承认。
总的来说,在22年的时候,与对比的YOLOv5和YOLOv7,本文提出的YOLOv6是较好的存在。
除却正常的网络设计、优化方案和数据增强方式等。本文针对重参数网络在训练和推理的不一致性,设计了针对重参数结构的量化方式(实际上就是使用了RepOptimizer,可以认为是RepVGGv2,解决了RepVGG量化不友好的问题),得到的精度还是可以的。
本文的方案为:
在网络结构上,Anchor-free的解耦检测头,在不同大小的网络架构下选择不同思路的backbone(较小模型使用单路径的repVGG,较大模型使用多分支backbone),neck采用PAN结构;训练时会添加一个自蒸馏的检测分支(预训练好的检测头);在激活函数上面,较小模型使用ReLU代替YOLOv5中的Swish激活函数,因为ReLU能在部署时融合进Conv中。
在损失函数上,分类损失使用VFL,框回归损失使用GIoU/CIoU回归框边界和使用DFL回归概率值,不采用目标损失函数,采用自知识蒸馏的方案,自知识蒸馏损失函数采用channel级的KL散度。
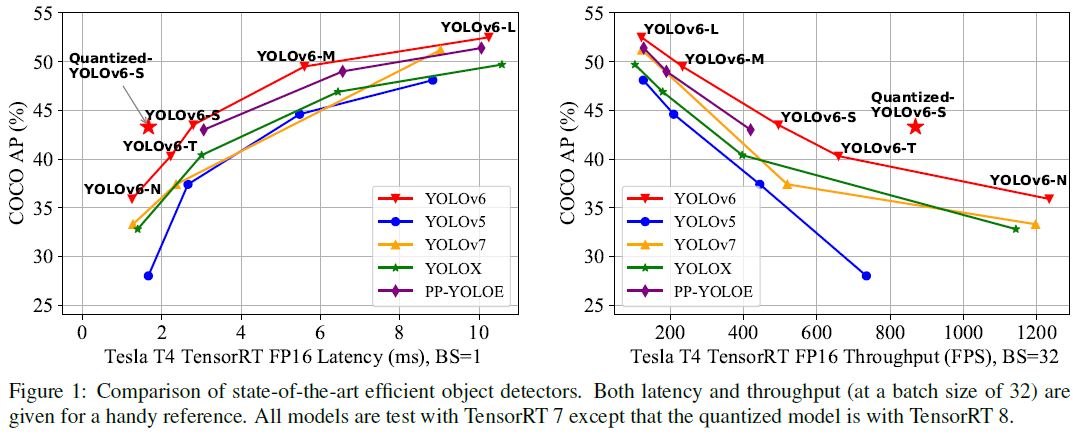
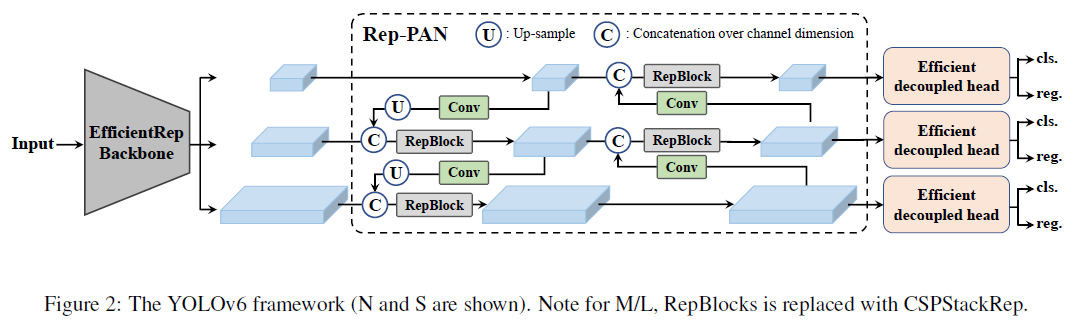
论文介绍
模型架构相关设计
之前的论文对一个网络进行设计的时候,都会使用同一个架构,进行不同尺度的缩放。作者认为这种大小模型的优雅一致性不是必要的,作者在YOLOv6的大小模型就使用了不同的backbone设计。在较小模型使用RepVGG(单路径结构),在较大模型使用CSPStackRep(多路径结构)。在neck的选择上,YOLOv6延续了YOLOv4和YOLOv7的PAN结构。在检测头上,YOLOv6是采用anchor-free的设计,解耦分类和框检测的结构。
无锚(anchor-free)检测器因其更好的泛化能力和解码预测结果的简单性而脱颖而出。Anchor-free的检测器有两种:基于锚点(anchor point-based)的和基于关键点回归(keypoint-based)的。YOLOv6采用的是基于锚点的范式,其框回归分支实际上预测了从锚点到边界四边的距离。
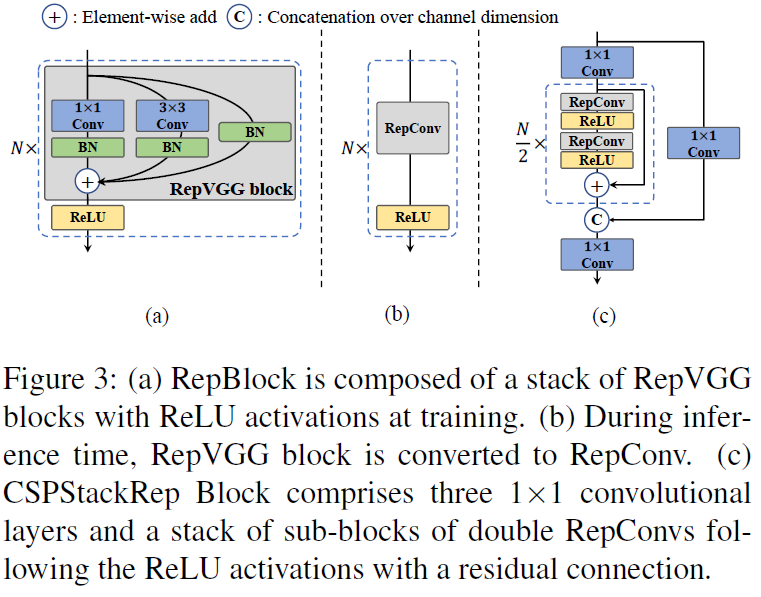
在工业应用上,量化和知识蒸馏都是常用手段。由于YOLOv6的较小模型使用了重参数结构,这样会存在推理和训练的架构不一致问题,作者使用RepOptimizer来解决RepVGG所存在的量化问题。
在知识蒸馏的应用上,作者使用pretrained的相同分支来进行知识蒸馏,对分类分支和框回归分支分别进行自蒸馏学习。教师网络是经过预训练的学生网络本身,所以称之为自蒸馏(self-distillation)。在量化训练时,教师分支仍采用浮点,学生分支采用量化。教师网络的软标签和label的硬标签之间的比例通过余弦衰减动态下降,以让学生分支在训练的不同阶段有选择地获得知识。这也是启发式的应用,在训练的早期,学生分支的能力弱,拟合教师网络的软标签比较好;随着迭代次数增加,硬标签更能增强学生分支的性能。
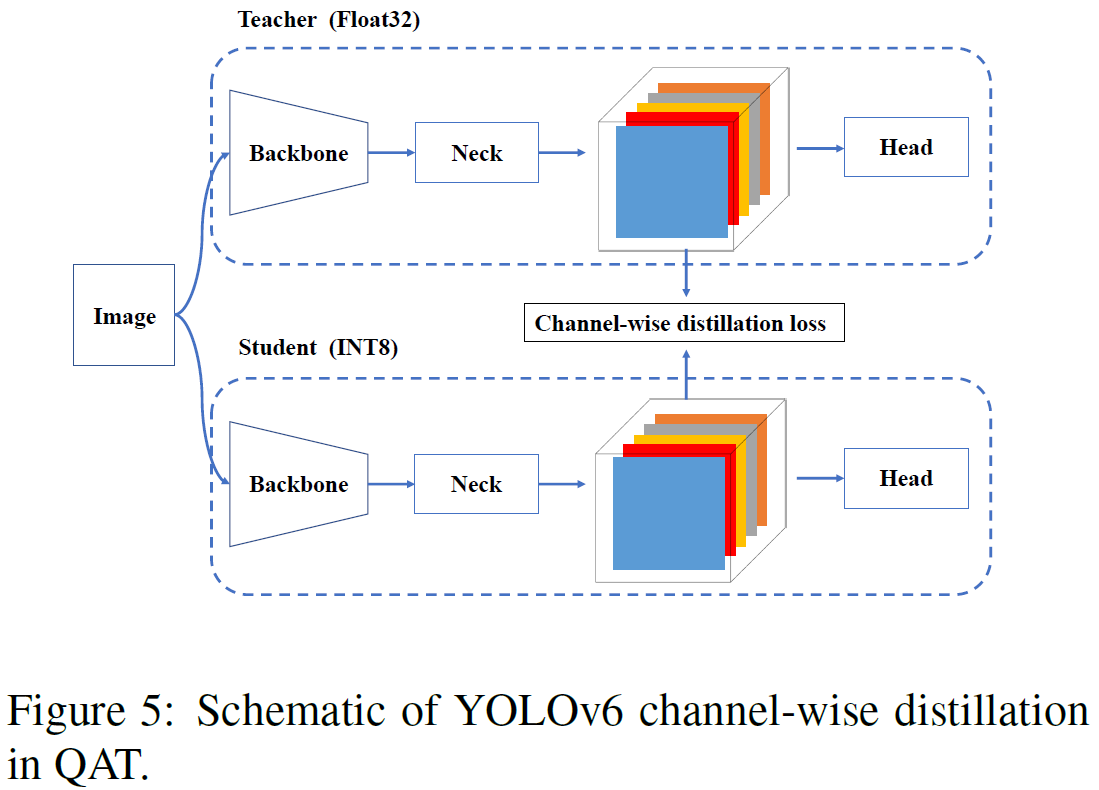
标签分配
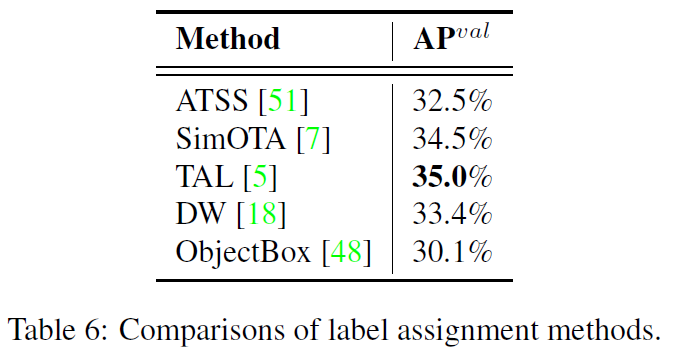
在标签分配上,作者认为TAL是更有效率和训练友好的。
在早期的时候,YOLOv6使用过SimOTA,后来发现OTA会降低训练管道的速度,且在训练过程中不稳定的情况屡见不鲜,所以后面就没使用SimOTA。
在TOOD论文上提出了任务对齐学习(Task Alignment Learning, TAL),是分类分数和预测框质量的统一指标。在之前的目标检测任务中,是依据IoU来为目标分配标签。在一定程度上,分类任务和框回归任务是不对齐的。使用TAL指标来代替IoU,在一定程度上可以缓解分类任务和回归任务的不对齐问题。
此外,作者观察到TAL 比 SimOTA带来更多的性能提升,且训练管道更加稳定。因此本文使用TAL作为默认的标签分配策略。
损失函数
在损失函数上,VariFocal Loss作为分类损失,SIoU/GIoU Loss作为回归损失。目标检测的损失函数由分类损失、框回归损失和目标损失组成。在目标损失的消融实验上,作者发现目标损失的存在会损害整体的训练指标,因此移除了目标损失。
在分类任务上,通常会使用Focal Loss来平衡难易样本和正负样本。为了解决训练和推理之间质量评估和分类使用不一致的问题(和框的位置有关),QFL(Quality Focal Loss)在FL的基础上,将分类分数和定位质量联合起来表示,用于分类分支任务的监督。下列公式中的
q
q
q 是质量评估值,通常与边界框的IoU相关,表示样本的定位质量。VFL(VariFocal Loss)在FL的基础上加了一个自学习的系数。YOLOv6采用的是VFL。
L
F
L
=
−
α
t
(
1
−
p
t
)
γ
l
o
g
(
p
t
)
L
Q
F
L
=
−
α
t
(
1
−
p
t
)
γ
l
o
g
(
p
t
)
∗
q
L
V
F
T
=
−
α
t
(
1
−
p
t
)
γ
l
o
g
(
p
t
)
∗
w
\begin{aligned} L_{FL}&=-\alpha_t(1-p_t)^\gamma log(p_t) \\ L_{QFL}&=-\alpha_t(1-p_t)^\gamma log(p_t)*q \\ L_{VFT}&=-\alpha_t(1-p_t)^\gamma log(p_t)*w \end{aligned}
LFLLQFLLVFT=−αt(1−pt)γlog(pt)=−αt(1−pt)γlog(pt)∗q=−αt(1−pt)γlog(pt)∗w
在框回归任务上,有坐标回归和框质量回归的细分任务。坐标回归从一开始的
L
1
L_1
L1损失到现在基本都是IoU损失(GIoU/CIoU/SIoU等),作者在YOLOv6-N/T中使用SIoU,其他使用GIoU。
框质量回归,实际上是一个0-1的概率回归。之前的检测任务重采用交叉熵等损失函数回归。本文介绍了DFL(Distribution Focal Loss)方法和DFLv2方法。DFL将边界框位置的连续分布简化为离散的概率分布来处理目标检测中的不确定性。它考虑了数据中的模糊性和不确定性。特别是在真实边界框边界模糊的情况下,有助于提高框的定位精度。DFL的设计旨在减少低质量预测的影响,以提高模型的整体性能。DFLv2在DFL的基础上增加了一个轻量级的子网络。但因为DFL和DFLv2在作者实验中效果差不多,以及DFL和DFLv2在较小模型中会较大程度地降低训练速度,所以作者只在YOLOv6-M/L中使用DFL。
FCOS和YOLOX都是Anchor-free的方法,他们都使用了object Loss。YOLOv6也进行了该项损失的相关试验,但没有得到正效果,因而没有添加该损失项。
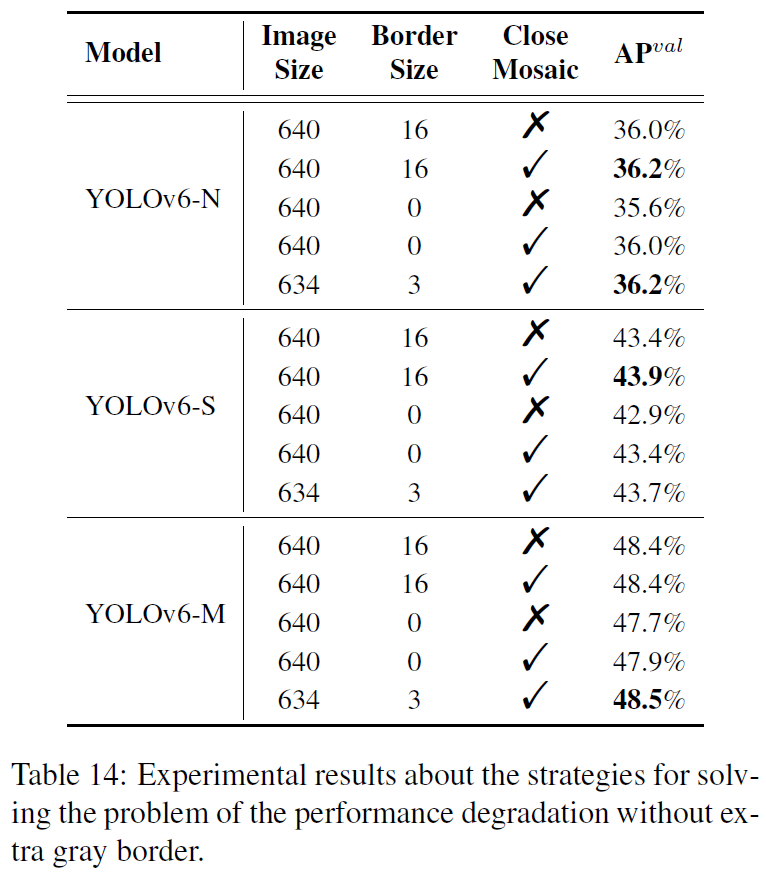
图像灰阶边界
在YOLOv5和YOLOv7的测试上,都会给图像加一个灰色边界,这样能帮助检测器识别图像边缘的目标(尽管灰边没有有效信息)。灰边界会降低推理速度,但没有灰边界性能又会下降。
YOLOv6也应用了该技巧,但进行了训练管道上的改进。
作者假定该问题来自于Mosaic增强时对灰边的pading。为验证这一点,作者在最后几个epochs的训练迭代上丢掉了Mosaic增强(又称之为淡化策略)。验证结果为:本文的模型可以在不降低推理速度的情况下保持甚至提高性能。
模型量化
使用RepOptimizer能够使得RepVGG这种重参数结构设计的网络,在推理时的特征分布有所收敛,这有利于PTQ。
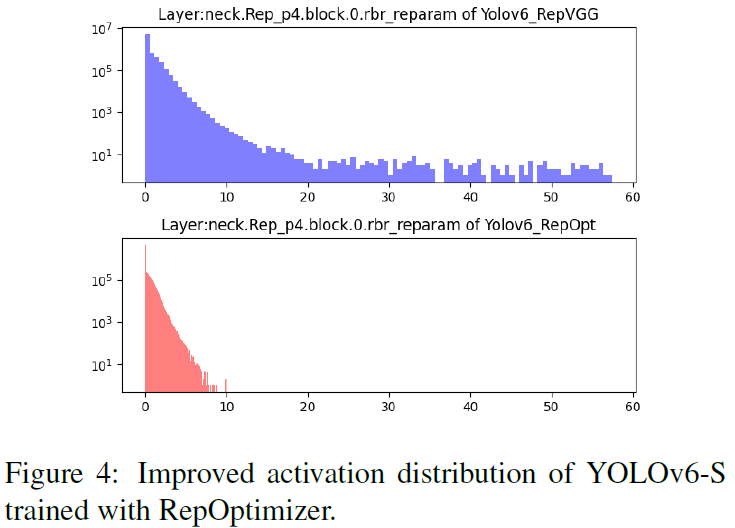
在YOLOv6第一版代码的时候,作者选择将部分对量化敏感的Layers保留在浮点推理。衡量量化敏感程度的指标,有使用MSE、SNR、余弦相似度等衡量量化前后的分布相似度,也有选择观察量化前后的AP指标的。在第二版代码的时候,就对全部结构进行量化了。
论文实验
YOLOv6使用和YOLOv5一样的优化器和学习策略。带着动量、LR余弦衰减的SGD,使用warm-up、group weight decay和EMA。
采用两个强增强方法(Mosaic/Mixup)。前者拼接图像,后者叠加图像。
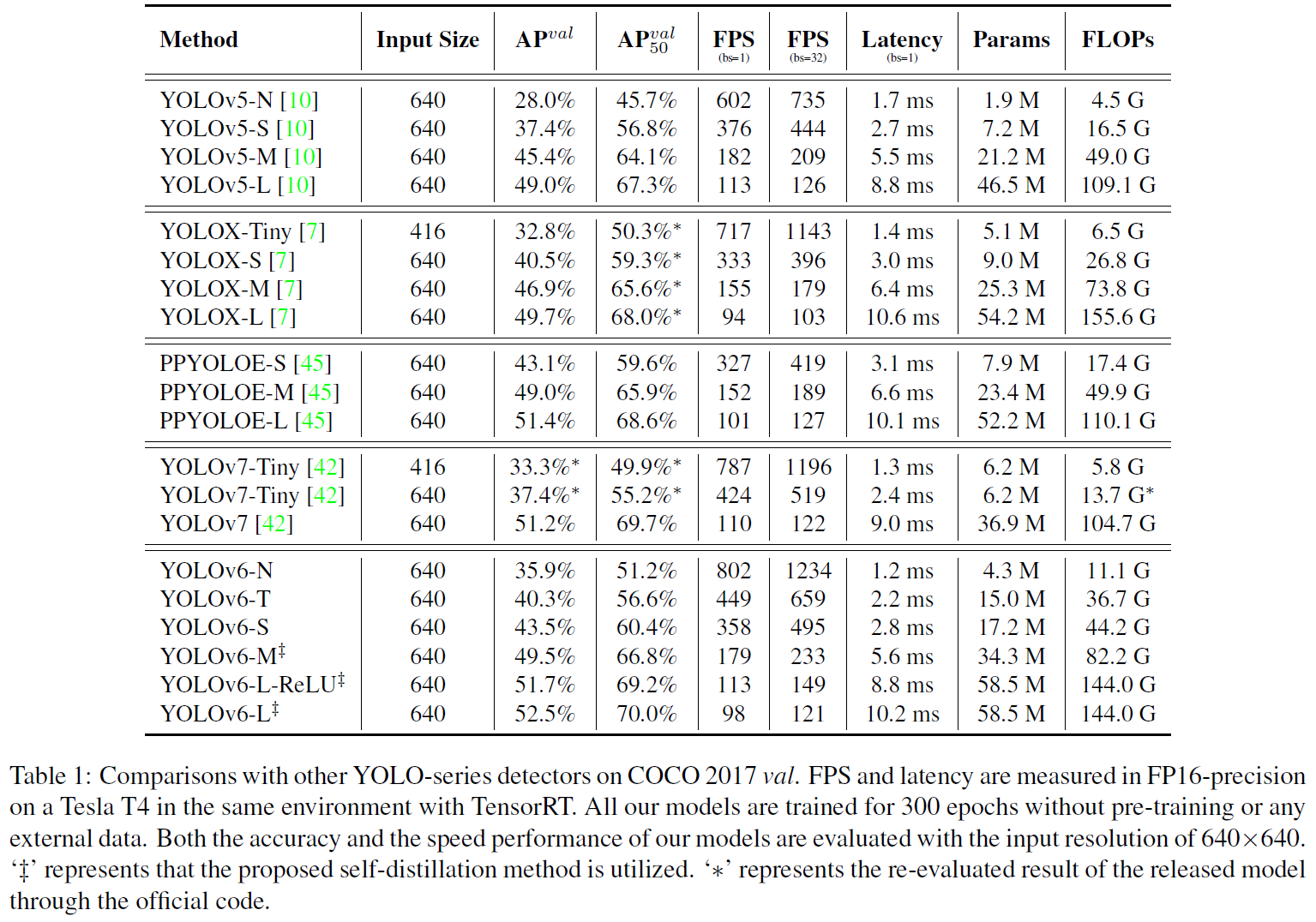
在COCO2017训练和验证。训练使用 8 8 8张NVIDIA A100 GPUs,速度测试使用 1 1 1张NVIDIA Tesla T4 GPU,TensorRT版本默认使用7.2。
因为是工业界出品,所以不关注FLOPs和参数量,关注的是部署时的速度性能,包括BS为
1
1
1和
32
32
32时的吞吐量。
结果如下图所示,在小模型上,YOLOv6在吞吐量和延迟都有更好的表现。在中大模型上,YOLOv6在相似速度的情况下有更高的AP。将SiLU替换成ReLU,大模型(YOLOv6-L)也能更快更精确。
消融实验
网络设计
多分支网络在分类任务表现好,但因为平行度下降,会导致延迟上升,所以作者在较小网络中选择RepVGG这样的单路径网络。VGG这样的单路径网络,有更高的平行度,占用更少内存。但RepVGG如果要扩大网络规模,则需要指数级的增长,所以不如多分支网络靠谱。
检测头上,是解耦了分类识别和框回归的特征。在框回归上,YOLOv6选择了anchor-free的思路,减少了输出通道以及关于anchor的后处理。
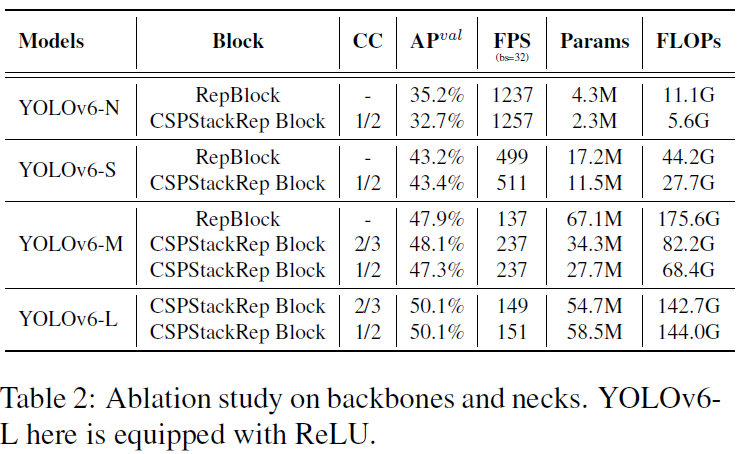
从上表2可以看出,在YOLOv6-N上,多分支远不如单分支;在YOLOv6-S上,两者相差不大。
多分支网络的设计由上图 3( c )展示的CSPStackRep堆叠,多用了残差分支和 1 × 1 1\times 1 1×1 Conv。
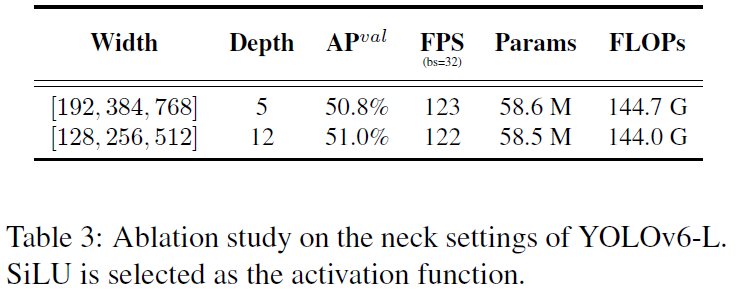
在YOLOv6-L上实验了宽度和深度的影响,最后结论见下表,为:细长比宽浅略微好一点。
在网络结构的组成上,SiLU(
S
i
L
U
(
x
)
=
x
∗
σ
(
x
)
=
x
1
+
e
−
x
SiLU(x)=x*\sigma(x)=\frac{x}{1+e^{-x}}
SiLU(x)=x∗σ(x)=1+e−xx)激活函数是被选择最多的。一般认为该损失函数能得到较好的结果且不会导致过多计算消耗。但因为SiLU不能融入到Conv中,所以ReLU会是一个在部署时更快的激活函数。
如下表所示,Conv+SiLU有更高的精度,RepConv+ReLU有更好的速度精度平衡。所以在最终选择上,作者在YOLOv6-N/T/S/M的较小模型使用RepConv+ReLU,在YOLOv6-L上使用Conv/SiLU用以提升训练速度和改善性能。

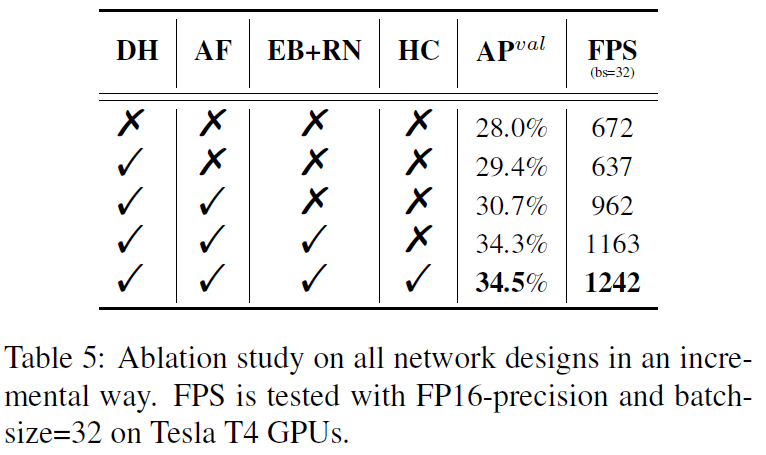
以YOLOv5-N作为baseline,测试各个组件的提升。
解耦检测头带来
1.4
%
1.4\%
1.4%的AP提升,增加
5
%
5\%
5%的延时。
Anchor-Free带来
1.3
%
1.3\%
1.3%的AP提升,速度提升了
51
%
51\%
51%。速度的提升是因为少了
3
×
3\times
3×的预设锚,输出通道维度低。
EfficientRep Backbone+Rep-PAN neck,带来
3.6
%
3.6\%
3.6%的AP提升,速度提升
21
%
21\%
21%。
优化的解耦检测头(optimized decoupled head, hybrid channels, HC)带来
0.2
%
0.2\%
0.2%的AP提升,和
6.8
6.8
6.8的速度提升;
训练策略
标签分配上,SimOTA和TAL是最好的 2 2 2条策略。考虑到训练的稳定性和更好的性能,作者选择了TAL。
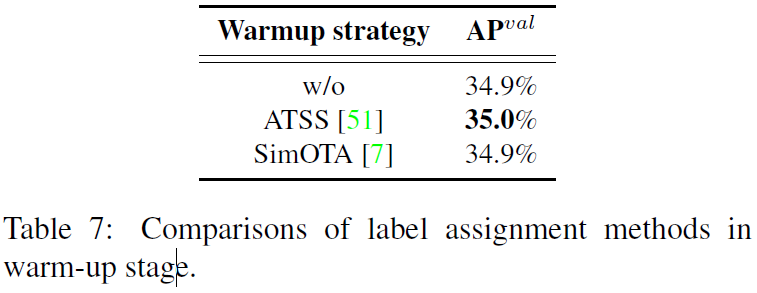
训练早期有没有warm-up以及使用何种策略warm-up得出的模型效果是差不多的。
自蒸馏的消融实验如下。分类和边框回归的蒸馏都有所提升,weight decay的带来的提升也不少。

灰阶边界填充,对于使用Mosaic数据增强的淡出策略相关消融实验如下图所示。使用淡出策略后,无论是否使用灰阶边界填充,都能达到甚至超过没有淡出策略的训练管道指标。当设置输入图像为 634 × 634 634\times 634 634×634,加上长度为 3 3 3的灰阶边界填充,即 640 × 640 640\times640 640×640,超过了 ( 640 + 16 ) × ( 640 + 16 ) (640+16)\times(640+16) (640+16)×(640+16)的原始管道。
量化效果
PTQ量化策略上,使用RepOptimizer,YOLOv6的PTQ量化指标有巨大提升。
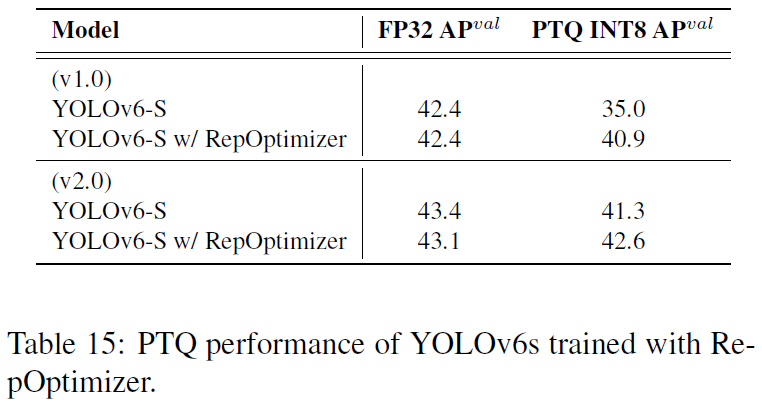
QAT量化策略上,使用RepOptimizer也有巨大的提升。
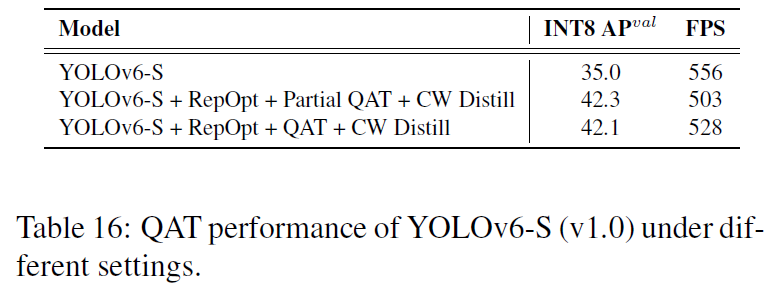
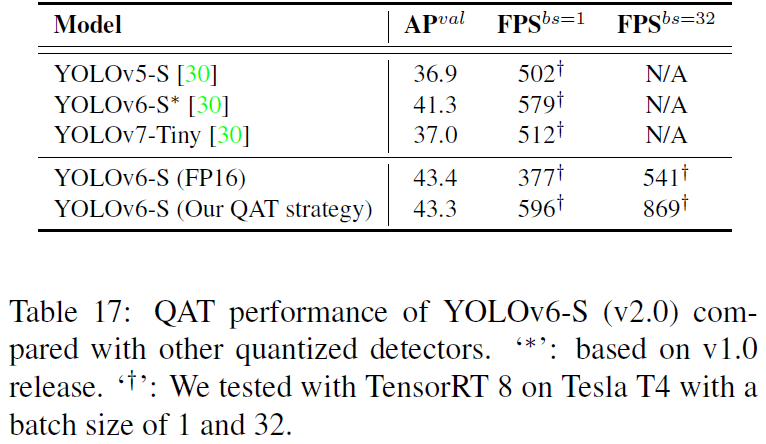
QAT量化策略,在v2.0的代码上,移除了量化敏感层的操作,直接所有Layers都进行量化。

















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









