







谷歌刚刚发布了Gemma 3,这是他们最新一代的开源语言模型,并在AI社区引起了轰动。正如官方公告所述:
“Gemma 3引入了多模态功能,支持视觉-语言输入和文本输出。它能够处理长达128k token的上下文窗口,理解超过140种语言,并提供了改进的数学、推理和聊天能力,包括结构化输出和函数调用。”
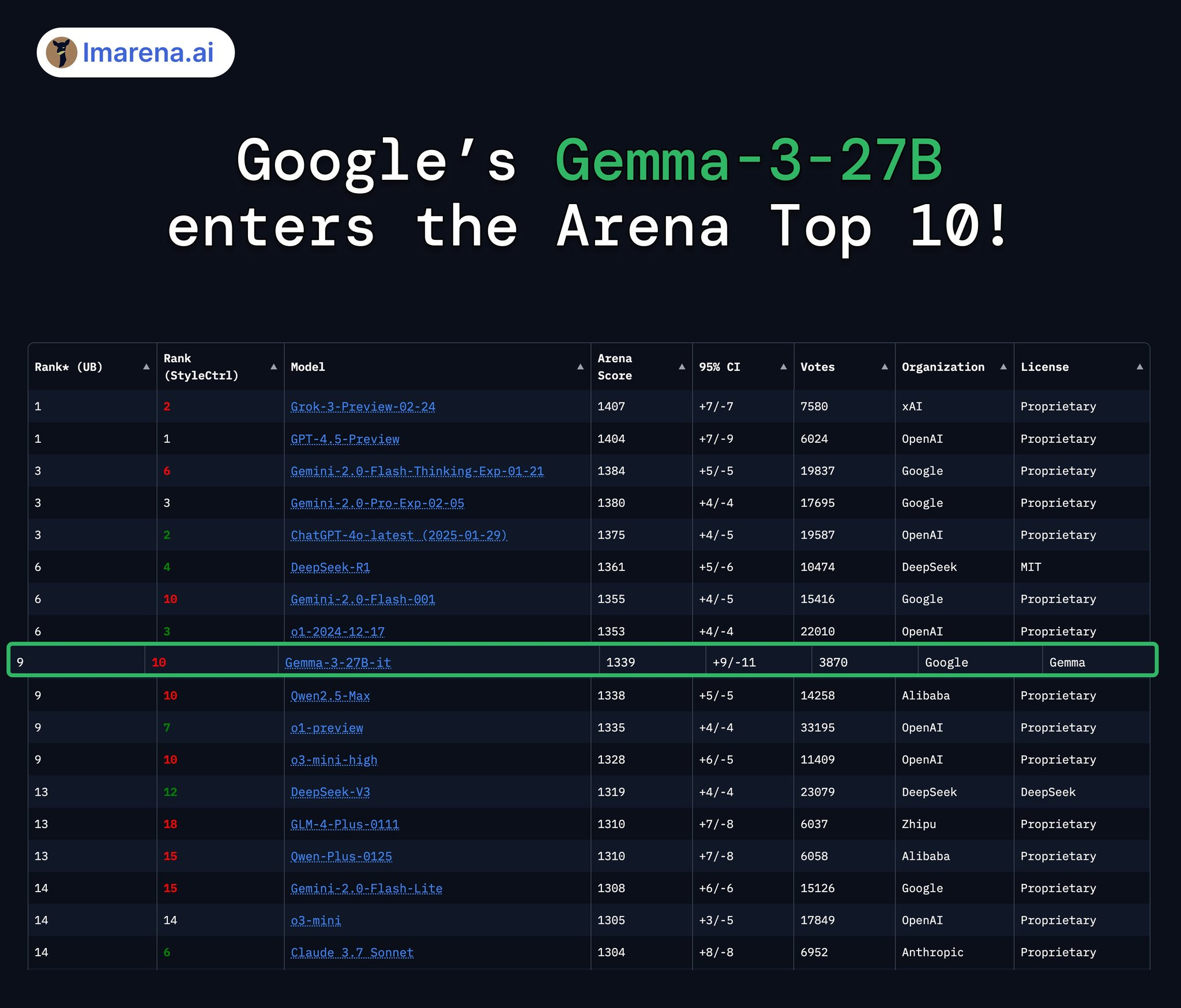
这是对之前版本的重大飞跃,谷歌声称,由于使用了蒸馏、强化学习和模型合并的优化训练过程,Gemma 3现在“在LMArena中排名第一,得分为1338”,成为“顶级开源紧凑模型”。
在本文中,我们将深入探讨如何使用Ollama在Google Cloud Run上部署Gemma 3(4B参数)模型,创建一个可用于生产的API,并将其集成到您自己的应用程序中。虽然谷歌提供了多种部署选项,包括官方的Cloud Run教程,但我们将探索一种更简化的方法,并提供一些实用的优化。
本文概述的部署方法使用了一个整合脚本,该脚本处理从设置Google Cloud环境到在Cloud Run上部署带有GPU加速的Gemma 3模型的整个过程。
先决条件
在开始之前,请确保您具备以下条件:
-
已启用计费的Google Cloud Platform账户
-
已安装并配置gcloud CLI
-
已启用Cloud Run API和Artifact Registry API的Google Cloud项目
-
对Docker和API的基本了解
-
对使用尖端AI技术的热情(这一点很重要!)
谷歌已通过多个平台(包括Hugging Face、Kaggle和Ollama)提供了Gemma 3,我们将在本教程中使用Ollama。
架构理解
我们的部署由一个服务组成:
Gemma Ollama服务:该服务使用Ollama(一个开源模型服务框架)托管Gemma 3(4B)模型。
该服务部署在Google Cloud Run上,这是一个为容器化应用程序提供的无服务器计算平台,具有自动扩展和按使用付费的定价模式。
部署脚本
为了简化部署过程,我们创建了一个名为belha-deploy.sh的整合脚本,该脚本处理整个工作流程。以下是脚本的功能概述:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 73
73

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











