









 该代码示例展示了如何利用HuggingFace的模型(如Muge-Image-Caption和DiffusionPipeline)结合gradio创建交互式应用,分别实现为图片添加标题和根据文本提示生成图片的功能。用户可以输入图片或文本,自定义参数,以直观体验AI生成内容的过程。
该代码示例展示了如何利用HuggingFace的模型(如Muge-Image-Caption和DiffusionPipeline)结合gradio创建交互式应用,分别实现为图片添加标题和根据文本提示生成图片的功能。用户可以输入图片或文本,自定义参数,以直观体验AI生成内容的过程。
learn from https://learn.deeplearning.ai/huggingface-gradio
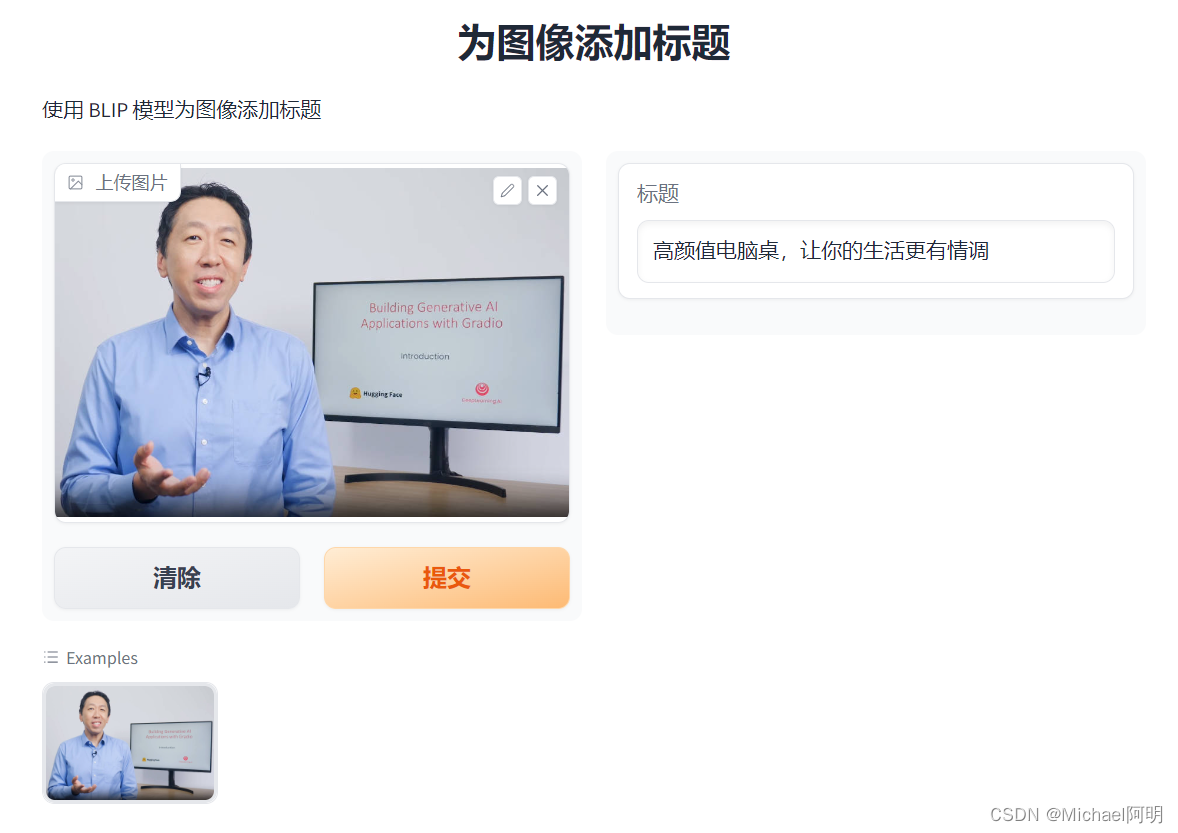
1. 给图片起标题
import pathlib
from PIL import Image
from transformers import pipeline
import gradio as gr
get_completion = pipe = pipeline("image-to-text", model="D:\huggingface\hub\Maciel\Muge-Image-Caption")
def summarize(input):
output = get_completion(input)
return output[0]['generated_text']
if __name__ == '__main__':
image = pathlib.Path(__file__).parent / 'Andrew.jpg'
img = Image.open(image)
# img.show()
print(get_completion(img))
# [{'generated_text': '高颜值电脑桌,让你的生活更有情调'}]
gr.close_all()
demo = gr.Interface(fn=summarize,
inputs=[gr.Image(label="上传图片", type="pil")],
outputs=[gr.Textbox(label="标题")],
title="为图像添加标题",
description="使用 BLIP 模型为图像添加标题",
allow_flagging="never",
examples=[image])
demo.launch(share=True)
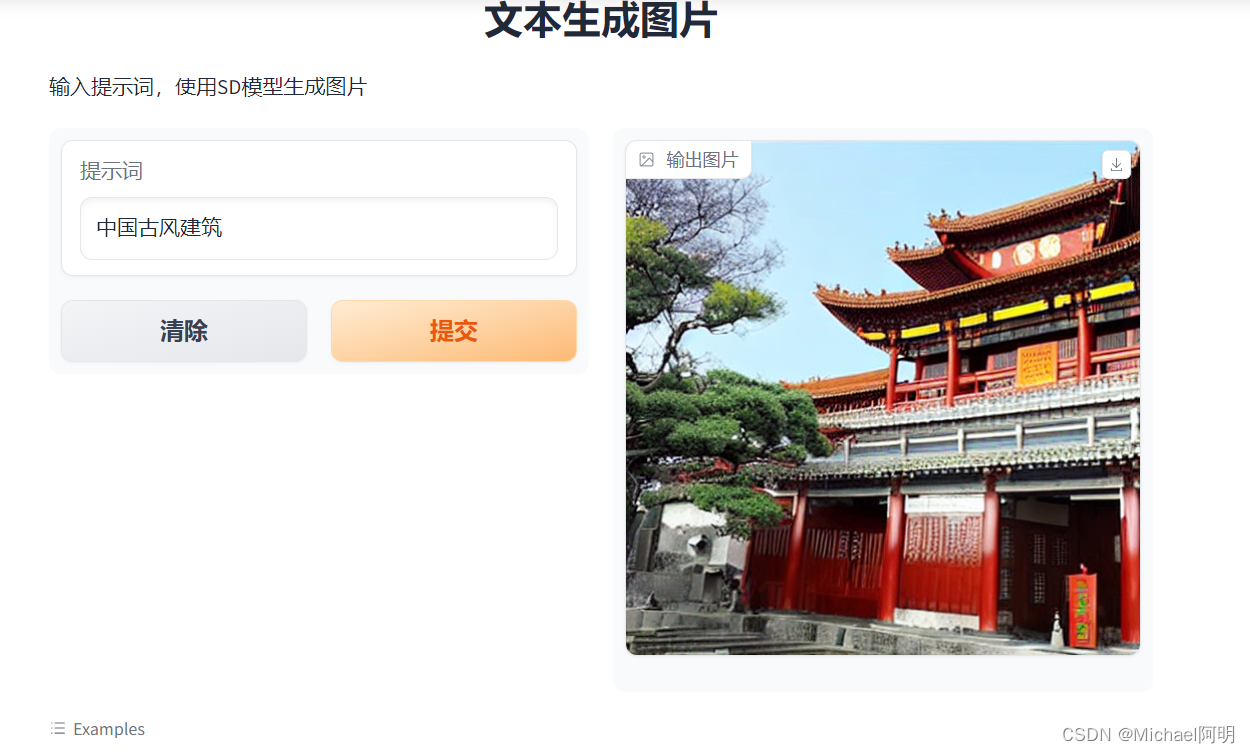
2. 文生图
以下,本地电脑资源不够,就直接在 官网上操作了
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
def get_completion(prompt):
return pipeline(prompt).images[0]
prompt = "a train in hill"
result = get_completion(prompt)
IPython.display.HTML(f'<img src="data:image/png;base64,{result}" />')

import gradio as gr
#A helper function to convert the PIL image to base64
#so you can send it to the API
def base64_to_pil(img_base64):
base64_decoded = base64.b64decode(img_base64)
byte_stream = io.BytesIO(base64_decoded)
pil_image = Image.open(byte_stream)
return pil_image
def generate(prompt):
output = get_completion(prompt)
result_image = base64_to_pil(output)
return result_image
gr.close_all()
demo = gr.Interface(fn=generate,
inputs=[gr.Textbox(label="提示词")],
outputs=[gr.Image(label="输出图片")],
title="文本生成图片",
description="输入提示词,使用SD模型生成图片",
allow_flagging="never",
examples=["中国古风建筑","a mecha robot in a favela"])
demo.launch(share=True, server_port=int(os.environ['PORT1']))
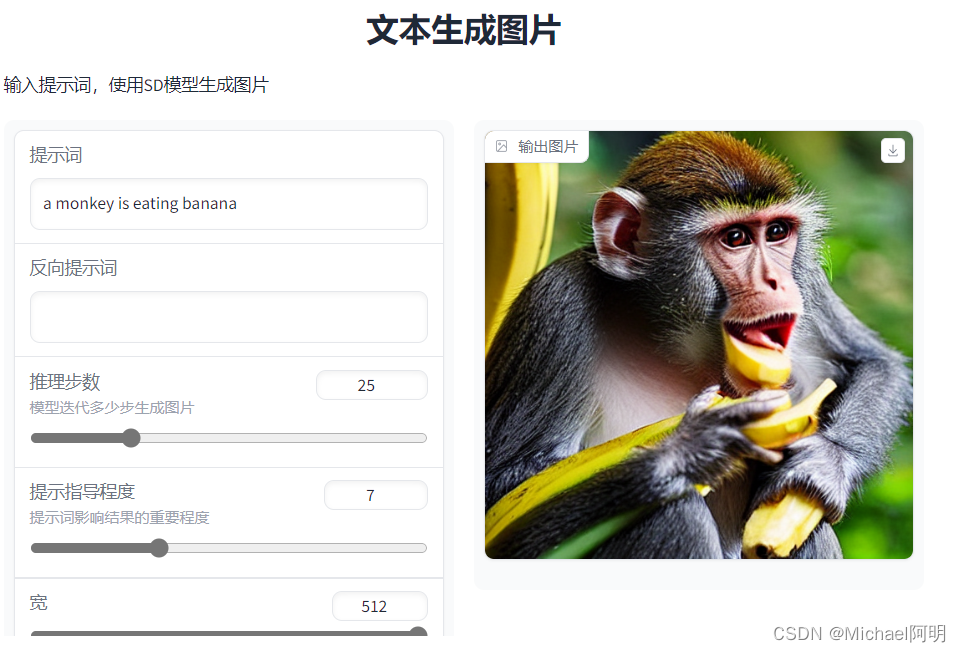
添加高级选项
import gradio as gr
#A helper function to convert the PIL image to base64
# so you can send it to the API
def base64_to_pil(img_base64):
base64_decoded = base64.b64decode(img_base64)
byte_stream = io.BytesIO(base64_decoded)
pil_image = Image.open(byte_stream)
return pil_image
def generate(prompt, negative_prompt, steps, guidance, width, height):
params = {
"negative_prompt": negative_prompt,
"num_inference_steps": steps,
"guidance_scale": guidance,
"width": width,
"height": height
}
output = get_completion(prompt, params)
pil_image = base64_to_pil(output)
return pil_image
gr.close_all()
demo = gr.Interface(fn=generate,
inputs=[
gr.Textbox(label="提示词"),
gr.Textbox(label="反向提示词"),
gr.Slider(label="推理步数", minimum=1, maximum=100, value=25,
info="模型迭代多少步生成图片"),
gr.Slider(label="提示指导程度", minimum=1, maximum=20, value=7,
info="提示词影响结果的重要程度"),
gr.Slider(label="宽", minimum=64, maximum=512, step=64, value=512),
gr.Slider(label="高", minimum=64, maximum=512, step=64, value=512),
],
outputs=[gr.Image(label="输出图片")],
title="文本生成图片",
description="输入提示词,使用SD模型生成图片",
allow_flagging="never"
)
demo.launch(share=True, server_port=int(os.environ['PORT2']))
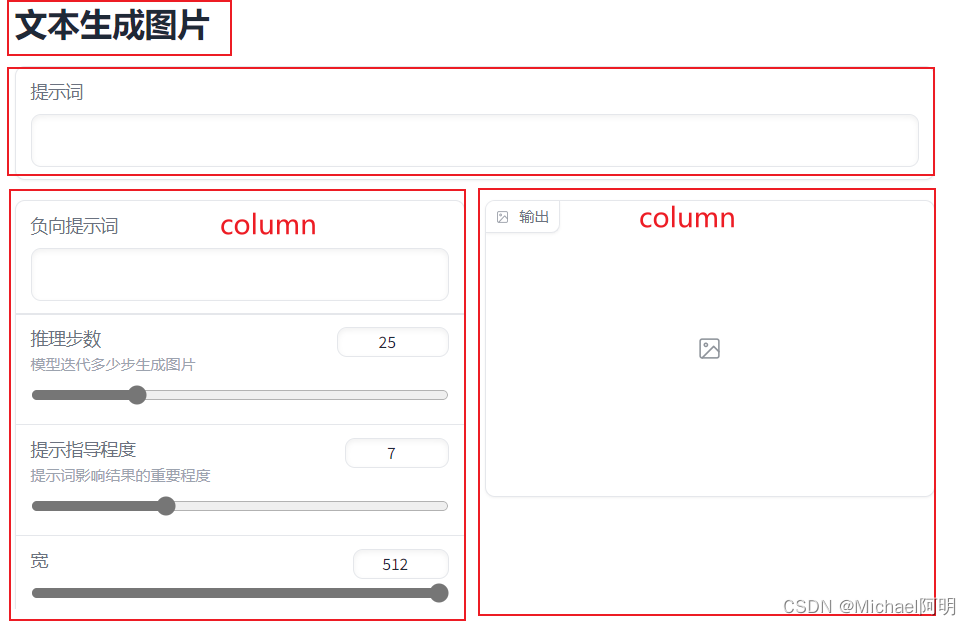
gr.Blocks
使用这个模块写起来更优雅,可以自由的排版
with gr.Blocks() as demo:
gr.Markdown("# 文本生成图片")
prompt = gr.Textbox(label="提示词")
with gr.Row():
with gr.Column():
negative_prompt = gr.Textbox(label="负向提示词")
steps = gr.Slider(label="推理步数", minimum=1, maximum=100, value=25,
info="模型迭代多少步生成图片")
guidance = gr.Slider(label="提示指导程度", minimum=1, maximum=20, value=7,
info="提示词影响结果的重要程度")
width = gr.Slider(label="宽", minimum=64, maximum=512, step=64, value=512)
height = gr.Slider(label="高", minimum=64, maximum=512, step=64, value=512)
btn = gr.Button("提交")
with gr.Column():
output = gr.Image(label="输出")
btn.click(fn=generate, inputs=[prompt,negative_prompt,steps,guidance,width,height], outputs=[output])
gr.close_all()
demo.launch(share=True, server_port=36790)
- 调整布局
with gr.Blocks() as demo:
gr.Markdown("# 文本生成图片")
with gr.Row():
with gr.Column(scale=4):
prompt = gr.Textbox(label="提示词") #Give prompt some real estate
with gr.Column(scale=1, min_width=50):
btn = gr.Button("提交") #Submit button side by side!
with gr.Accordion("高级选项", open=False): #Let's hide the advanced options!
negative_prompt = gr.Textbox(label="负向提示词")
with gr.Row():
with gr.Column():
steps = gr.Slider(label="推理步数", minimum=1, maximum=100, value=25,
info="模型迭代多少步生成图片")
guidance = gr.Slider(label="提示指导程度", minimum=1, maximum=20, value=7,
info="提示词影响结果的重要程度")
with gr.Column():
width = gr.Slider(label="宽", minimum=64, maximum=512, step=64, value=512)
height = gr.Slider(label="高", minimum=64, maximum=512, step=64, value=512)
output = gr.Image(label="输出") #Move the output up too
btn.click(fn=generate, inputs=[prompt,negative_prompt,steps,guidance,width,height], outputs=[output])
gr.close_all()
demo.launch(share=True, server_port=41010)
提交按钮放在上面,减少鼠标移动距离
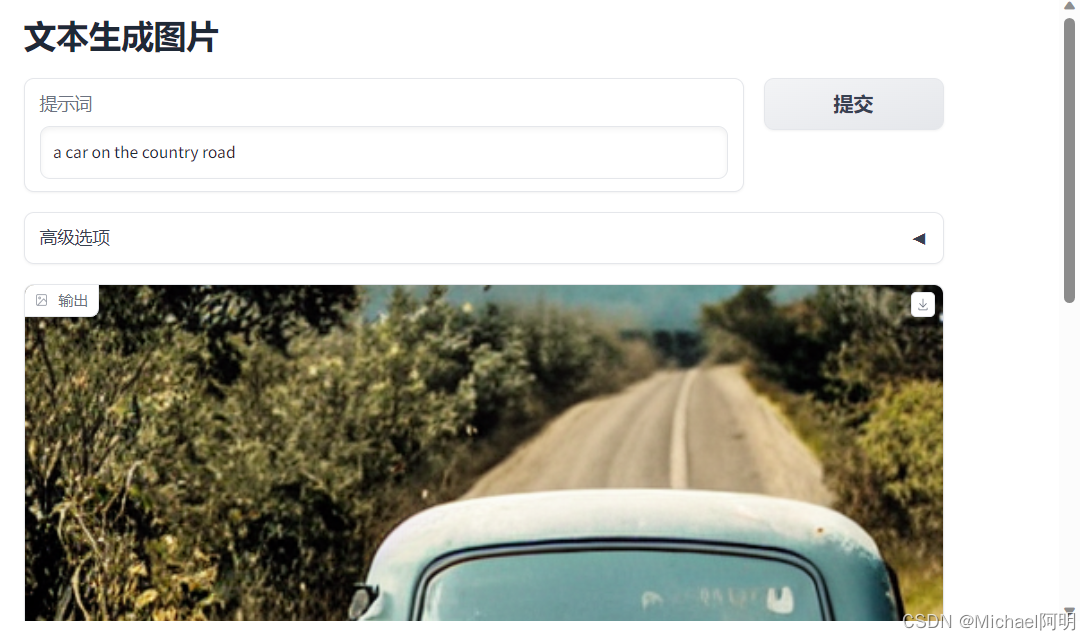
高级选项默认折叠,看起来简洁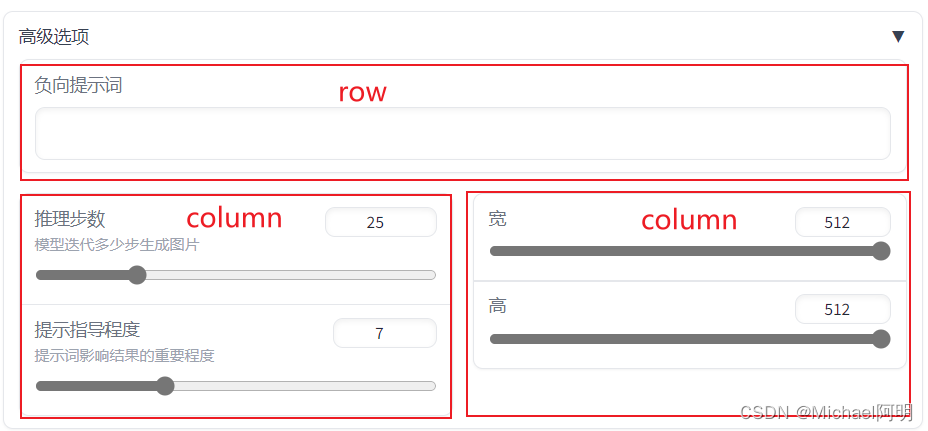


















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











