







基于SCSA注释
SCSA是一种统计学模型注释,使用的数据是s4d8_quality_control.h5ad。(我也是抄别人的,尽量和教程保持一致,如果没一致,我就自己搞了)
数据—预处理—聚类
老规矩,该进行聚类还是得进行聚类。
adata = sc.read(
filename="s4d8_quality_control.h5ad",
backup_url="https://figshare.com/ndownloader/files/40014331",
)
# 因为它已经质控过了,所以直接预处理好了
ov.pp.preprocess(adata,mode='shiftlog|pearson',n_HVGs=2000,)
adata.raw = adata
adata = adata[:, adata.var.highly_variable_features]
ov.pp.scale(adata)
ov.pp.pca(adata, layer='scaled', n_pcs=50)
sc.pp.neighbors(adata, n_neighbors=15, n_pcs=30, use_rep='scaled|original|X_pca')
sc.tl.leiden(adata, key_added="leiden_res1", resolution=2.0)
adata.obsm["X_mde"] = ov.utils.mde(adata.obsm["scaled|original|X_pca"])
基于SCSA数据库注释
由于作者使用的pandas版本是1.6几的版本,太老了,在github 上有进行对应的更新(只要更新omicverse到1.6.10版本就行了),同样的也更新了pySCSA_2024_v1_plus.db这个文件,可以从谷歌云下载
scsa = ov.single.pySCSA(adata=adata,
foldchange=1.5,
pvalue=0.01,
celltype='normal', # 正常的单细胞转录的话,使用normal, 癌细胞的话使用cancer
target='cellmarker',
# 正常的单细胞转录的话,使用cellmarker或是panglaodb, 癌细胞的话使用cancersea, 小鼠无法使用panglaodb
tissue='All',
species='Human',
model_path=r'pySCSA_2024_v1_plus.db'
)
scsa.cell_anno(clustertype='leiden_res1',
cluster='all', rank_rep=True)
scsa.cell_auto_anno(adata, key='scsa_celltype_cellmarker', clustertype='leiden_res1')
ov.utils.embedding(adata,
basis='X_mde',
color=['leiden_res1', 'scsa_celltype_cellmarker'],
legend_loc='on data',
frameon='small',
legend_fontoutline=1,
palette=ov.utils.palette()[14:],
show=True, # show为False时,返回图片对象
)

如果需要获取指定细胞类型的marker基因,可以通过下面的代码进行获取。
marker_dict=ov.single.get_celltype_marker(adata,clustertype='scsa_celltype_cellmarker')
print(marker_dict)
# {'B cell': ['AFF3', 'BACH2', 'CD74', 'EBF1', 'BANK1', 'RALGPS2', 'IGHM', 'FCHSD2', 'LYN', 'ZCCHC7'], 'Hematopoietic stem cell': [], 'Monocyte': ['NAMPT'], 'Naive CD8+ T cell': [], 'Natural killer T (NKT) cell': [], 'Natural killer cell': ['B2M', 'GNLY'], 'Red blood cell (erythrocyte)': [], 'T cell': [], 'Unknown': []}
基于CellTypist的细胞类型注释
深度学习模型的自动注释方法CellTypist,可以直接注释出细胞的亚群,对于不认识的细胞类型,其会选择性注释,不会瞎注释,这与SCSA是相同的。
import omicverse as ov
import scanpy as sc
import celltypist
from celltypist import models
# 使用的数据还是s4d8_quality_control.h5ad
adata = sc.read(
filename="data/s4d8_quality_control.h5ad",)
由于Celltypist要求使用的归一化值为10,000,而omicverse自带预处理的归一化值为500,000。所以我们提取原始counts进行还原,然后重新归一化。
adata=adata.raw.to_adata()
ov.utils.retrieve_layers(adata,layers='counts')
adata=ov.pp.preprocess(adata,mode='shiftlog|pearson',n_HVGs=2000,target_sum=1e4)
CellTypist模型预加载
机器学习的通病,需要下载模型到本地!烦死了!
models.download_models(force_update = True)
模型很小,才76MB,随便放!现在(2025.1.13)总共有54个模型。
💾 Downloading model [1/54]: Immune_All_Low.pkl
💾 Downloading model [2/54]: Immune_All_High.pkl
💾 Downloading model [3/54]: Adult_COVID19_PBMC.pkl
💾 Downloading model [4/54]: Adult_CynomolgusMacaque_Hippocampus.pkl
💾 Downloading model [5/54]: Adult_Human_MTG.pkl
💾 Downloading model [6/54]: Adult_Human_PancreaticIslet.pkl
💾 Downloading model [7/54]: Adult_Human_PrefrontalCortex.pkl
💾 Downloading model [8/54]: Adult_Human_Skin.pkl
💾 Downloading model [9/54]: Adult_Human_Vascular.pkl
💾 Downloading model [10/54]: Adult_Mouse_Gut.pkl
💾 Downloading model [11/54]: Adult_Mouse_OlfactoryBulb.pkl
💾 Downloading model [12/54]: Adult_Pig_Hippocampus.pkl
💾 Downloading model [13/54]: Adult_RhesusMacaque_Hippocampus.pkl
💾 Downloading model [14/54]: Autopsy_COVID19_Lung.pkl
💾 Downloading model [15/54]: COVID19_HumanChallenge_Blood.pkl
💾 Downloading model [16/54]: COVID19_Immune_Landscape.pkl
💾 Downloading model [17/54]: Cells_Adult_Breast.pkl
💾 Downloading model [18/54]: Cells_Fetal_Lung.pkl
💾 Downloading model [19/54]: Cells_Human_Tonsil.pkl
💾 Downloading model [20/54]: Cells_Intestinal_Tract.pkl
💾 Downloading model [21/54]: Cells_Lung_Airway.pkl
💾 Downloading model [22/54]: Developing_Human_Brain.pkl
💾 Downloading model [23/54]: Developing_Human_Gonads.pkl
💾 Downloading model [24/54]: Developing_Human_Hippocampus.pkl
💾 Downloading model [25/54]: Developing_Human_Organs.pkl
💾 Downloading model [26/54]: Developing_Human_Thymus.pkl
💾 Downloading model [27/54]: Developing_Mouse_Brain.pkl
💾 Downloading model [28/54]: Developing_Mouse_Hippocampus.pkl
💾 Downloading model [29/54]: Fetal_Human_AdrenalGlands.pkl
💾 Downloading model [30/54]: Fetal_Human_Pancreas.pkl
💾 Downloading model [31/54]: Fetal_Human_Pituitary.pkl
💾 Downloading model [32/54]: Fetal_Human_Retina.pkl
💾 Downloading model [33/54]: Fetal_Human_Skin.pkl
💾 Downloading model [34/54]: Healthy_Adult_Heart.pkl
💾 Downloading model [35/54]: Healthy_COVID19_PBMC.pkl
💾 Downloading model [36/54]: Healthy_Human_Liver.pkl
💾 Downloading model [37/54]: Healthy_Mouse_Liver.pkl
💾 Downloading model [38/54]: Human_AdultAged_Hippocampus.pkl
💾 Downloading model [39/54]: Human_Colorectal_Cancer.pkl
💾 Downloading model [40/54]: Human_Developmental_Retina.pkl
💾 Downloading model [41/54]: Human_Embryonic_YolkSac.pkl
💾 Downloading model [42/54]: Human_Endometrium_Atlas.pkl
💾 Downloading model [43/54]: Human_IPF_Lung.pkl
💾 Downloading model [44/54]: Human_Longitudinal_Hippocampus.pkl
💾 Downloading model [45/54]: Human_Lung_Atlas.pkl
💾 Downloading model [46/54]: Human_PF_Lung.pkl
💾 Downloading model [47/54]: Human_Placenta_Decidua.pkl
💾 Downloading model [48/54]: Lethal_COVID19_Lung.pkl
💾 Downloading model [49/54]: Mouse_Dentate_Gyrus.pkl
💾 Downloading model [50/54]: Mouse_Isocortex_Hippocampus.pkl
💾 Downloading model [51/54]: Mouse_Postnatal_DentateGyrus.pkl
💾 Downloading model [52/54]: Mouse_Whole_Brain.pkl
💾 Downloading model [53/54]: Nuclei_Lung_Airway.pkl
💾 Downloading model [54/54]: Pan_Fetal_Human.pkl
感兴趣的可以从models.json中了解更详细的内容。(太多了,根本整不过来!)
模型预测
predictions = celltypist.annotate(adata, model='Immune_All_Low.pkl', majority_voting=True, mode='prob match',
p_thres=0.5)
adata_new = predictions.to_adata()
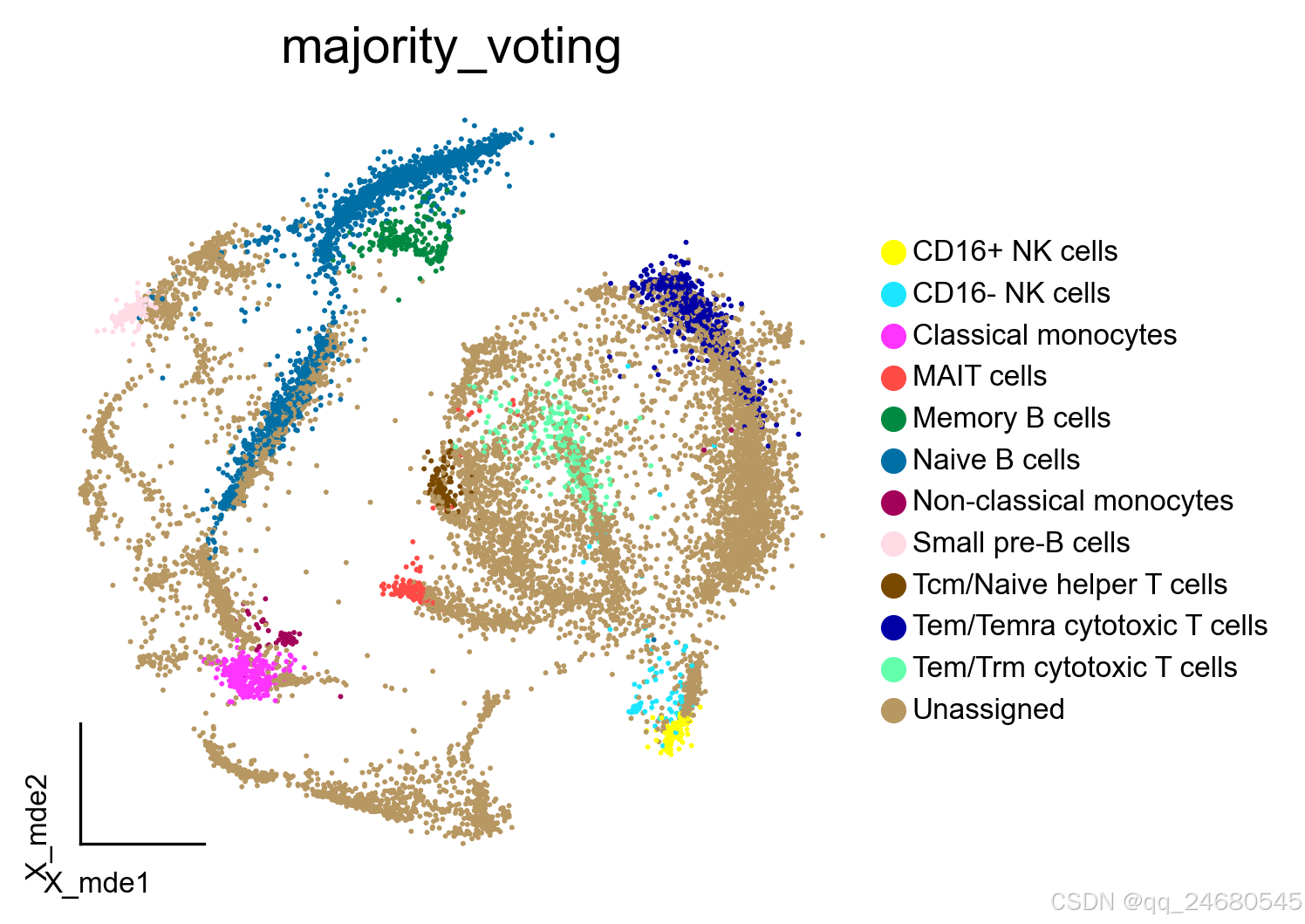
majority_fig = ov.utils.embedding(adata_new,
basis='X_mde',
color=["majority_voting"],
# title=['Cell type'],
palette=sc.pl.palettes.default_102,
show=False,
frameon='small',
wspace=0.45,
legend_fontsize = 8,
legend_fontoutline=1)
大部分细胞类型被标注为Unassigned,这是由于我们设定了预测概率0.5作为阈值,低于该阈值的细胞不被注释,表明Celltypist在注释复杂的未知的数据上的效果,并不如手动注释或者是SCSA!
使用人工智能注释
人工智能仅能注释细胞大类,不能注释细胞亚型,还是有缺陷的。先是使用get_celltype_marker获取这这写簇的特征基因是什么。
all_markers = ov.single.get_celltype_marker(adata, clustertype='leiden', rank=True,
key='rank_genes_groups',
foldchange=2, topgenenumber=5)
# 假设有这些
{'0': ['LDHB', 'CD3D', 'NOSIP', 'CD3E', 'CD7'],
'1': ['LTB', 'LDHB', 'IL32', 'IL7R', 'CD3D'],
'10': ['PPBP', 'PF4', 'GNG11', 'SPARC', 'SDPR'],
'2': ['LYZ', 'S100A9', 'S100A8', 'FCN1', 'TYROBP'],
'3': ['CD74', 'CD79A', 'HLA-DRA', 'CD79B', 'HLA-DPB1'],
'4': ['CCL5', 'NKG7', 'CST7', 'GZMA', 'IL32'],
'5': ['LST1', 'FCER1G', 'COTL1', 'AIF1', 'IFITM3'],
'6': ['NKG7', 'GZMB', 'GNLY', 'PRF1', 'CTSW'],
'7': ['CCL5', 'CD3D', 'IL32', 'GZMK'],
'8': ['FTL', 'S100A8', 'FTH1', 'TYROBP', 'S100A9'],
'9': ['HLA-DPA1', 'HLA-DRB1', 'HLA-DPB1', 'HLA-DRB5', 'HLA-DRA']}
然后获取api-key,omicverse支持openai, 通义千问,Kimi等人工智能大厂的api调用。
import os
os.environ['AGI_API_KEY'] = 'sk-****'
# api-key需要自己生成,半个小时不到就可以搞定了
# 然后将上面的all_markers发给人工智能
result = ov.single.gptcelltype(all_markers, tissuename='PBMC', speciename='human',
model='qwen-plus', provider='qwen',
topgenenumber=5)
假设返回的是下面的内容
{ '0': 'T cells ',
'1': 'T cells ',
'10': 'Megakaryocytes/Platelets ',
'2': 'Monocytes/Macrophages ',
'3': 'B cells ',
'4': 'Natural Killer Cells ',
'5': 'Dendritic Cells/Monocytes ',
'6': 'Natural Killer Cells ',
'7': 'T cells/Natural Killer Cells ',
'8': 'Monocytes/Macrophages ',
'9': 'B cells'}
只要把这些内容注释到里面数据里面就可以了
adata.obs['gpt_celltype'] = adata.obs['leiden'].map(result).astype('category')
adata.write_h5ad(output_path)

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









