







3D Packing for Self-Supervised Monocular Depth Estimation
PackNet-SfM: 3D Packing for Self-Supervised Monocular Depth Estimation
摘要
尽管相机无处不在,机器人平台通常依赖于像激光雷达这样的主动传感器进行直接的三维感知。在这项工作中,我们提出了一种新的自监督单目深度估计方法,结合几何和一种新的深度网络PackNet,只学习未标记的单目视频。我们的架构利用新颖的对称打包和解包块,共同学习使用三维卷积压缩和解压保细节表示。尽管我们的方法是自监督的,但是在KITTI基准上我们的方法优于其他自监督、半监督和完全监督的方法。PackNet中的3D归纳偏差使其能够在不过度拟合的情况下随输入分辨率和参数数量进行缩放,从而更好地推广了非领域数据,如NuScenes数据集。此外,它不需要在ImageNet上进行大规模的有监督的预训练,并且可以实时运行。最后,我们发布了DDAD(自动驾驶的密集深度),这是一个新的城市驾驶数据集,具有更具挑战性和更精确的深度评估,这得益于安装在全球自动驾驶汽车车队上的高密度激光雷达所产生的更大范围和更密集的地面真实深度。
贡献
贡献1:是一种新的卷积网络结构,称为PackNet,用于高分辨率的自监督单目深度估计。我们提出了新的包装和解包块,共同利用3D卷积学习表示最大限度地传播密集的外观和几何信息,同时仍然能够实时运行。
贡献2:是一个新的损失,可以选择性地利用相机的速度(如汽车、机器人、手机)来解决单目视觉中固有的尺度模糊问题。
贡献3:是一个新的数据集:自动驾驶密集深度(DDAD)。它利用了各种各样的原木,这些原木来自一个配备摄像头和高精度远程激光雷达的校准良好的自动驾驶汽车车队。与现有的基准测试方法相比,在深度范围内进行深度估计是提高分辨率的关键。
方法
SFM运动估计下的深度估计原理


深度估计Loss
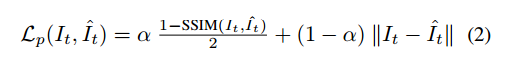
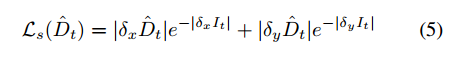
加入速度来产生尺度值
场景深度和相机自我运动只能估计到一个未知和模糊的比例因子。这也反映在总体学习目标中,其中光度损失与场景的度量深度无关。此外,以前所有在自我监督的单眼模式下操作的方法都受到了这种限制,并且在测试时使用激光雷达测量人工地加入了这个比例因子。
Velocity Supervision Loss(全文核心重点)
由于瞬时速度测量在当今大多数移动系统中普遍存在,我们证明,它们可以直接纳入我们的自监督目标中,以学习一种测量准确且具有尺度感知能力的单目深度估计器。在训练过程中,我们在姿势网络预测的姿势平移分量的大小与测量的瞬时速度标量v乘以目标帧和源帧之间的时间差△t→s之间施加额外的损失Lv,如下所示
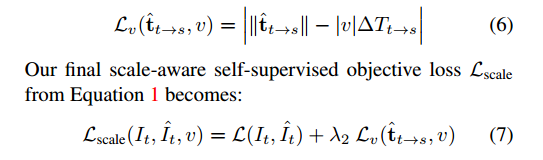
网络设计使用Packnet
Packing 过程 Space2Depth ,unpacking过程Depth2Space

本文网络借助了Space2depth的网络
Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network.
chainer.functions.space2depth

packnet 在数据集DDAD上深度估计上的表现

ResNet和PackNet不同参数对比

在kitti数据集上的表现(震惊!!!!)


Pose 估计


DDAD本文提出来的TOYOT 数据集
在本节中,我们将简要介绍我们新引入的DDAD(Dense Depth for Automated Driving)数据集以及使其成为Dense Depth estimation基准的相关特性。它包括高分辨率、长距离LAMAR-H21作为用于产生点云的激光雷达传感器,最大范围为250m和亚1cm范围精度。此外,它还包含六个校准摄像机,时间同步为10赫兹,共同产生360度的车辆周围的覆盖范围。请注意,在我们的工作中,我们只使用来自前置摄像头的信息进行培训和评估。在图10、11和12中,针对不同的城市设置,分别显示了投射到这六个摄像机上的Luminar-H2点云的示例。通过将这些亮度点云投影到相机帧上生成的深度图,我们可以以更具挑战性的方式评估深度估计方法,包括密集度和更长的范围。在主文本的表2和图6中,我们展示了在这些条件下,我们提出的PackNet架构如何优于其他相关方法。事实上,当在更长的范围内,无论是在整个间隔上还是在离散化的箱子上,考虑更密集的地面真值信息时,性能上的差距都会增大。DDAD是一个跨大陆的数据集,场景来自美国(旧金山湾区、底特律和安娜堡)和日本(东京和大田)的城市环境。每个场景的长度为5或10秒,由50或100个具有相应Luminar-H2点云和6个图像帧的样本组成,包括内部和外部校准。训练集包含194个场景,共17050个个体样本,验证集包含60个场景,共4150个样本。
















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









