






深度学习自然语言处理 分享
整理:pp
 摘要:量化是为服务大语言模型(LLMs)不可或缺的技术,最近已经应用到LoRA微调中。在这项工作中,我们关注的是在一个预训练模型上同时应用量化和LoRA微调的情景。在这种情况下,通常会观察到在下游任务性能上的一致差距,即在完全微调和量化加LoRA微调方法之间。为了应对这一问题,我们提出了LoftQ(LoRA微调感知量化),这是一个新颖的量化框架,可以同时对LLM进行量化并找到LoRA微调的适当低秩初始化。这种初始化缓解了量化和全精度模型之间的差异,并显著提高了在下游任务中的泛化性能。我们在自然语言理解、问答、摘要和自然语言生成任务上评估了我们的方法。实验证明我们的方法非常有效,并在具有挑战性的2比特和2/4比特混合精度区域中优于现有的量化方法。
摘要:量化是为服务大语言模型(LLMs)不可或缺的技术,最近已经应用到LoRA微调中。在这项工作中,我们关注的是在一个预训练模型上同时应用量化和LoRA微调的情景。在这种情况下,通常会观察到在下游任务性能上的一致差距,即在完全微调和量化加LoRA微调方法之间。为了应对这一问题,我们提出了LoftQ(LoRA微调感知量化),这是一个新颖的量化框架,可以同时对LLM进行量化并找到LoRA微调的适当低秩初始化。这种初始化缓解了量化和全精度模型之间的差异,并显著提高了在下游任务中的泛化性能。我们在自然语言理解、问答、摘要和自然语言生成任务上评估了我们的方法。实验证明我们的方法非常有效,并在具有挑战性的2比特和2/4比特混合精度区域中优于现有的量化方法。
https://arxiv.org/abs/2310.08659
Q1: 这篇论文试图解决什么问题?
A:这篇论文试图解决的问题是在大语言模型(LLMs)的部署和微调过程中,量化和LoRA(Low-Rank Adaptation)微调相结合时性能下降的问题。具体来说,当在预训练模型上同时应用量化和LoRA微调时,通常会观察到与全精度微调相比,在下游任务上存在性能差距。这种性能差距在低比特(如2位)量化情况下尤为明显。
为了解决这个问题,作者提出了LoftQ(LoRA-Fine-Tuning-aware Quantization)框架。LoftQ的目标是通过一种新颖的量化方法,同时对LLM进行量化,并为LoRA微调找到一个合适的低秩初始化,以减少量化模型与全精度模型之间的差异,并提高模型在下游任务上的泛化能力。这种方法旨在在保持模型大小和计算效率的同时,提高量化模型的性能,特别是在资源受限的实际部署环境中。
Q2: 有哪些相关研究?
A:在这篇论文中,作者提到了与LoftQ相关的几个研究领域和具体工作,这些研究为LoftQ提供了背景和对比。以下是一些相关的研究:
Quantization-Aware Training (QAT): 这是一种常用于在下游任务中适应量化模型的方法。QAT涉及量化和全模型微调的结合。然而,QAT需要大量的训练成本,并且计算量化权重的梯度很困难。
Post-Training Quantization (PTQ): PTQ是一种流行的量化框架,也可以用于任务适应。它通过训练数据集的一个小子集来校准高精度模型,从而使后续的量化受到训练数据集的指导。PTQ不涉及梯度反向传播,因此成本效益高,但通常比QAT的准确性低。
LoRA (Low-Rank Adaptation): LoRA是一种轻量级的微调方法,它在保持预训练权重矩阵不变的情况下,仅优化附加的低秩适配器。这种方法允许有效的任务适应。
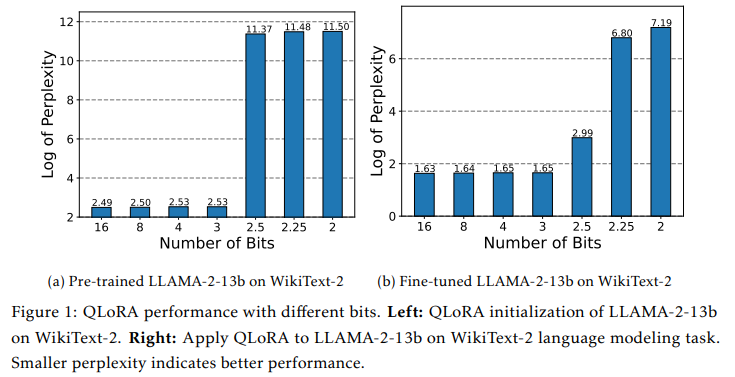
QLoRA: QLoRA是LoRA的一个变体,它在量化的背景下进行微调。然而,QLoRA在低比特量化(如2位)时可能会失败,因为它没有考虑到量化过程中引入的误差。
BinaryBERT: 这是BERT模型的一种二值化版本,它推动了BERT量化的极限。
Lmflow: 这是一个用于大型基础模型微调和推理的可扩展工具包。
LLM-QAT: 这是一种针对大型语言模型的数据无关量化感知训练方法。
这些研究为LoftQ提供了量化和微调技术的背景,并展示了在大型语言模型的压缩和效率提升方面的最新进展。LoftQ通过结合量化和LoRA微调,旨在克服现有方法的局限性,特别是在低比特量化的情况下。
Q3: 论文如何解决这个问题?

A:论文通过提出一个名为LoftQ(LoRA-Fine-Tuning-aware Quantization)的新型量化框架来解决大型语言模型在量化和LoRA微调后性能下降的问题。LoftQ的核心思想是在量化过程中考虑LoRA微调的需求,通过以下步骤实现:
交替优化:LoftQ采用交替优化的方法,首先对原始的高精度预训练权重进行量化,然后进行奇异值分解(SVD)以获得低秩近似。这个过程交替进行,直到达到预定的迭代次数或满足收敛条件。
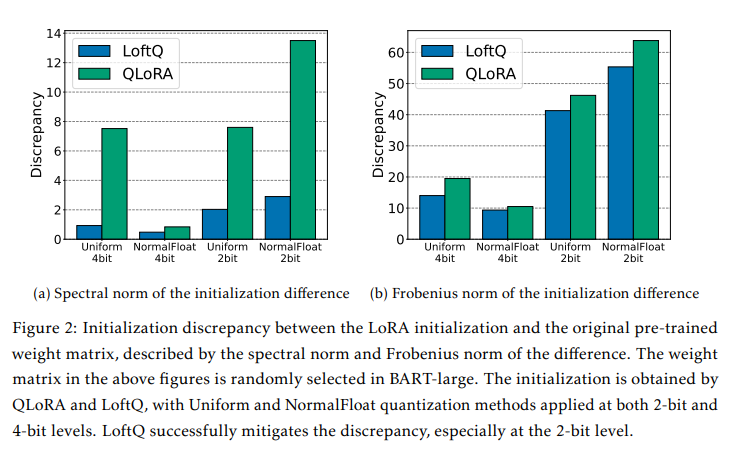
低秩近似:在每次迭代中,LoftQ都会计算量化权重和低秩适配器的组合,以最小化与原始预训练权重的差异。这通过优化Frobenius范数来实现,从而在量化和LoRA微调之间找到一个平衡。
初始化LoRA适配器:在LoRA微调之前,LoftQ通过上述优化过程得到的量化权重和低秩适配器作为网络的初始化。这为LoRA微调提供了一个更接近原始预训练权重的起点,有助于提高微调性能。
兼容性:LoftQ框架与不同的量化方法兼容,如均匀量化和NormalFloat量化。这使得它可以应用于不同的模型和场景。
实验验证:作者在自然语言理解(NLU)、问答、摘要和自然语言生成(NLG)等任务上对LoftQ进行了广泛的实验。实验结果表明,LoftQ在所有精度级别上都优于现有的量化方法,尤其是在具有挑战性的2位和2/4位混合精度情况下。
通过这些方法,LoftQ能够有效地减少量化过程中引入的误差,提高量化模型在下游任务上的性能,特别是在资源受限的环境中。这种方法不仅提高了模型的泛化能力,还保持了模型的压缩效率。
Q4: 论文做了哪些实验?
A:论文中进行了一系列实验来评估LoftQ框架的有效性。以下是主要的实验内容:
自然语言理解(NLU)任务:
使用DeBERTaV3-base模型在GLUE基准测试集上进行微调,该测试集包含多个自然语言理解任务,如情感分析、自然语言推理等。
在SQuADv1.1和ANLI数据集上进行问答任务的微调。
摘要任务:
使用BART-large模型在XSum和CNN/DailyMail数据集上进行文本摘要任务的微调。
自然语言生成(NLG)任务:
使用LLAMA-2系列模型在GSM8K和WikiText-2数据集上进行自然语言生成任务的微调。
量化方法的比较:
对比了LoftQ与现有的量化方法,如QLoRA,以及全精度LoRA微调方法。
在不同的量化位宽(如2位、4位和混合精度)下进行了实验。
性能和压缩比的评估:
评估了LoftQ在不同任务上的性能,包括准确率、ROUGE分数和困惑度(Perplexity)等指标。
计算了LoftQ在压缩模型大小方面的效果,包括压缩比和内存占用。
低秩适配器的排名选择:
研究了不同排名的低秩适配器对微调性能的影响。
交替优化步骤的敏感性分析:
分析了在LoftQ框架中交替优化步骤(T)的数量对性能的影响。
与剪枝方法的比较:
将LoftQ与剪枝方法进行了比较,以展示LoftQ在性能和内存效率方面的优势。
扩展到卷积层:
探讨了将LoftQ应用于卷积层的可能性,这在传统的LoRA方法中不常见。
这些实验结果表明,LoftQ在各种任务和量化精度下都能显著提高模型性能,尤其是在低比特量化的情况下。此外,LoftQ还展示了在保持模型大小和计算效率的同时,提高量化模型性能的能力。
Q5: 有什么可以进一步探索的点?
A:LoftQ框架虽然在多个方面取得了显著的成果,但仍有一些潜在的研究方向可以进一步探索:
更广泛的模型和任务:在更多的大型语言模型和多样化的自然语言处理任务上测试LoftQ的效果,以验证其泛化能力。
不同的量化策略:探索其他量化策略,如非均匀量化、动态量化或混合精度量化,以及它们与LoftQ的兼容性和性能。
优化算法的改进:研究不同的优化算法对LoftQ性能的影响,以及如何调整优化过程以进一步提高量化模型的性能。
低秩适配器的优化:深入研究低秩适配器的设计,包括它们的尺寸、初始化方法和更新策略,以提高微调效率和性能。
硬件加速:研究如何在特定硬件上实现LoftQ,以利用硬件加速的优势,提高推理速度和能效。
模型鲁棒性:研究量化过程中引入的噪声对模型鲁棒性的影响,以及如何设计更鲁棒的量化策略。
理论分析:从理论上分析LoftQ的性能,包括量化误差对模型性能的影响,以及低秩近似对模型泛化能力的作用。
实际部署:在实际应用场景中部署LoftQ,评估其在现实世界问题中的表现,以及与现有部署技术的比较。
跨领域适应性:研究LoftQ在跨领域任务中的适应性,例如从一种语言模型迁移到另一种语言或领域。
开源社区的贡献:将LoftQ框架开源,鼓励社区贡献和协作,以促进该领域的进一步发展。
这些研究方向可以帮助研究者更深入地理解量化对大型语言模型性能的影响,并推动量化技术在自然语言处理领域的应用。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容包括以下几个方面:
问题定义:论文针对大型语言模型(LLMs)在量化和LoRA(Low-Rank Adaptation)微调结合使用时性能下降的问题进行研究。
LoftQ框架:提出了LoftQ(LoRA-Fine-Tuning-aware Quantization)框架,这是一个新颖的量化方法,旨在通过量化和低秩近似的交替优化来减少量化模型与全精度模型之间的性能差距。
方法细节:
使用N位量化和低秩矩阵近似来初始化LoRA微调。
通过交替优化量化和奇异值分解(SVD)来逼近原始的高精度预训练权重。
提供了一个初始化点,用于LoRA微调,以改善下游任务的性能。
实验评估:在自然语言理解(NLU)、问答、摘要和自然语言生成(NLG)等任务上对LoftQ进行了广泛的实验评估。
实验结果表明,LoftQ在2位和2/4位混合精度情况下,特别是在低比特量化场景下,性能优于现有的量化方法。
LoftQ在多个数据集和模型上实现了与全精度微调相近或更好的性能。
代码开源:提供了LoftQ的代码实现,以便研究社区可以访问和使用。
讨论和分析:对LoftQ的性能进行了深入的讨论,包括与其他量化方法的比较、不同量化位宽的影响、以及在不同任务上的表现。
结论:LoftQ为LLMs提供了一个有效的量化框架,能够在保持模型大小和计算效率的同时,显著提高量化模型在下游任务上的性能。
总的来说,这篇论文提出了一个创新的量化方法,通过结合量化和LoRA微调,有效地提高了大型语言模型在量化后的性能,特别是在资源受限的环境中。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









