






如今的大模型啥都能干,但它们的“大脑”实在太占地方——动辄几百亿参数,推理速度慢、内存消耗大。 于是学者们搬出了量化技术,试图把模型的“高精度思维”压缩成“精简版”,比如从32位浮点数降到8位甚至4位整数。
论文:Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
链接:https://arxiv.org/pdf/2504.04823
但问题来了:压缩后的模型会不会变“笨”?
比如让一个压缩后的模型做数学题,它会不会因为“算力不足”而乱写步骤?这正是本文要解答的核心问题。
核心发现
发现一:8位量化是“安全线”,4位以下风险高
论文通过大量实验证明:8位权重+8位激活值(W8A8)的量化几乎无损,而4位量化就可能让模型在复杂任务上“翻车”。
例如在高中数学竞赛题(AIME-120)中,4位量化模型的准确率可能暴跌16%。
发现二:任务越难,量化越容易崩
模型做小学数学题(GSM8K)时,4位量化还能勉强hold住;但面对大学级别的科学证明题(GPQA),性能直接“跳水”。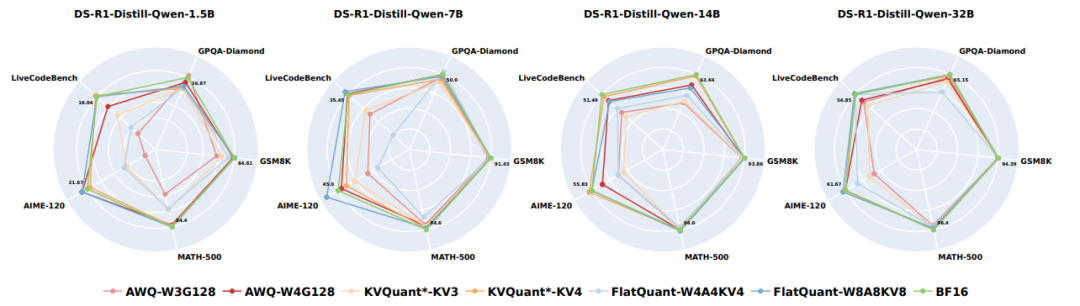 中的曲线清晰显示:任务难度与量化误差成正比,越烧脑的问题,模型越需要“高精度思考”。
中的曲线清晰显示:任务难度与量化误差成正比,越烧脑的问题,模型越需要“高精度思考”。
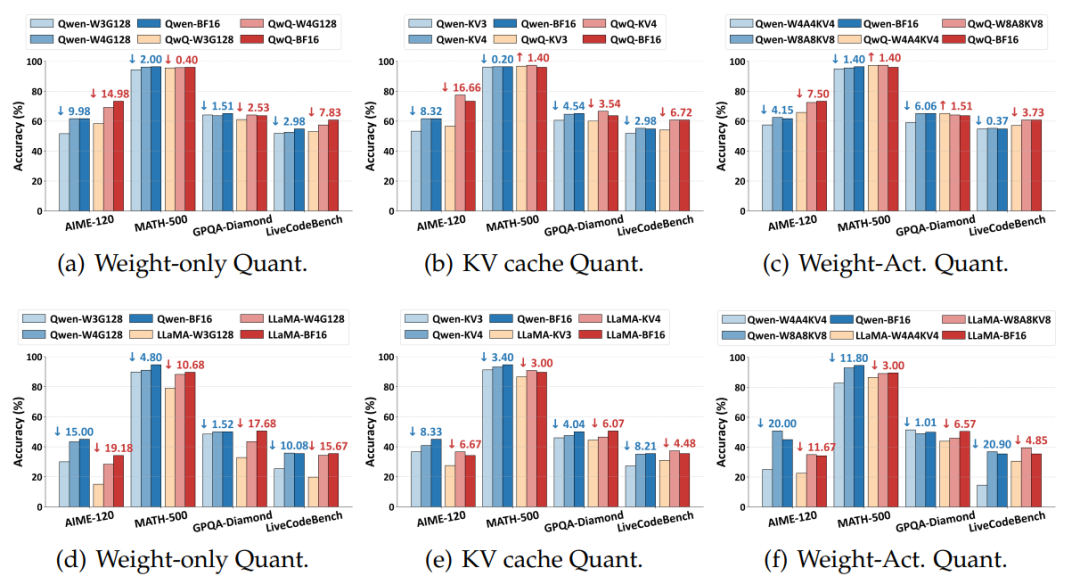
发现三:模型的血统决定“抗压能力”
蒸馏模型(模仿学霸的“学习笔记”训练的模型)比强化学习模型(自己刷题练出来的模型)更扛得住量化。
不同家族模型(如Qwen和LLaMA)对量化的耐受度也不同,就像有人喝凉水都胖,有人怎么吃都不胖。
实验
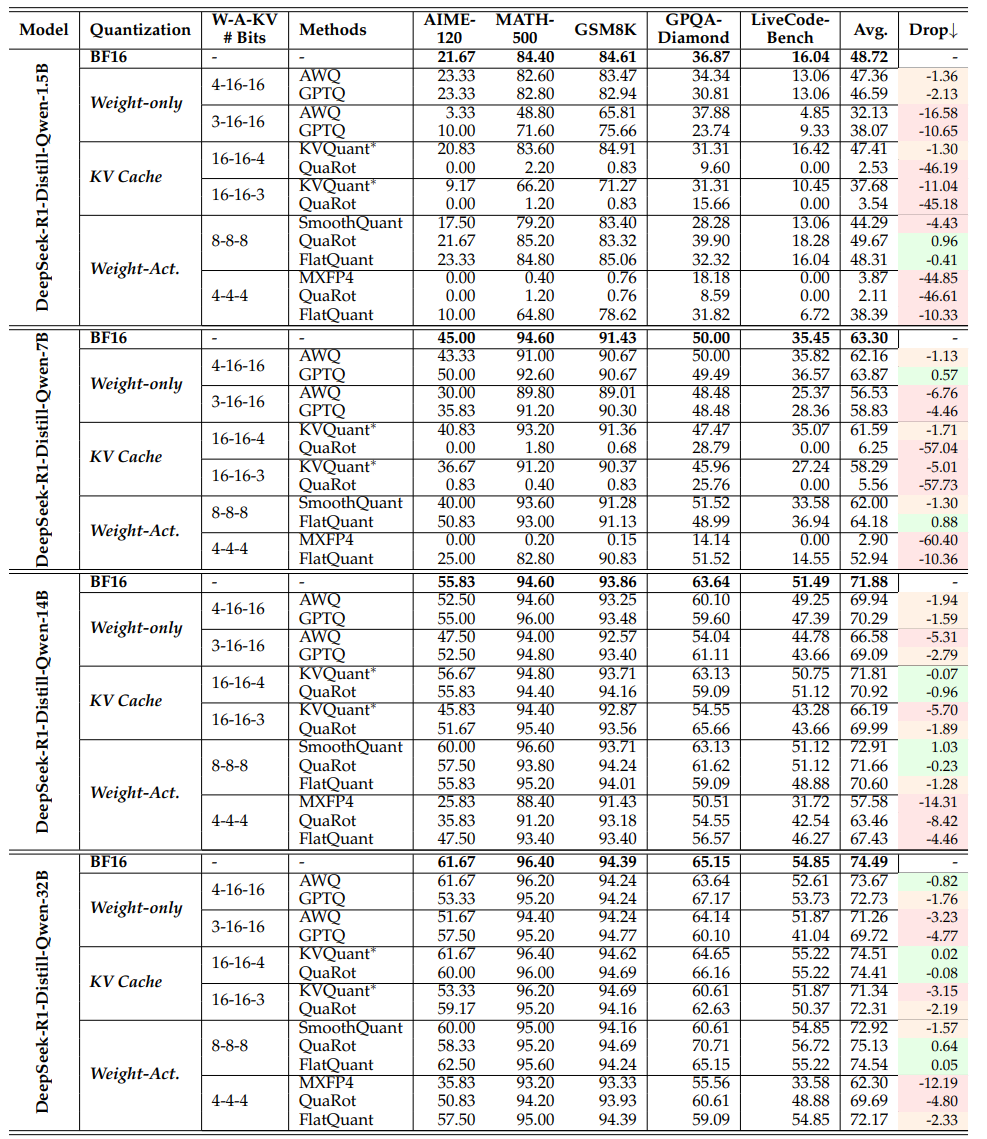
模型:从1.5B到70B参数的多个开源模型,包括DeepSeek、LLaMA等。
数据集:涵盖数学竞赛题、科学证明题、编程题,甚至故意设置超长推理步骤(比如生成3万个token的解题过程)。
量化:测试了权重量化、KV缓存量化、激活值量化等多种方案,最终筛选出AWQ(权重量化)、QuaRot(KV缓存量化)、FlatQuant(全量化)三大最优算法。
实用建议
普通用户:直接上8位量化(W8A8),性能无损且省资源。
极客玩家:4位量化+大模型(如70B参数)的“组合拳”,既能压缩体积,又能靠“体型优势”保住准确率。
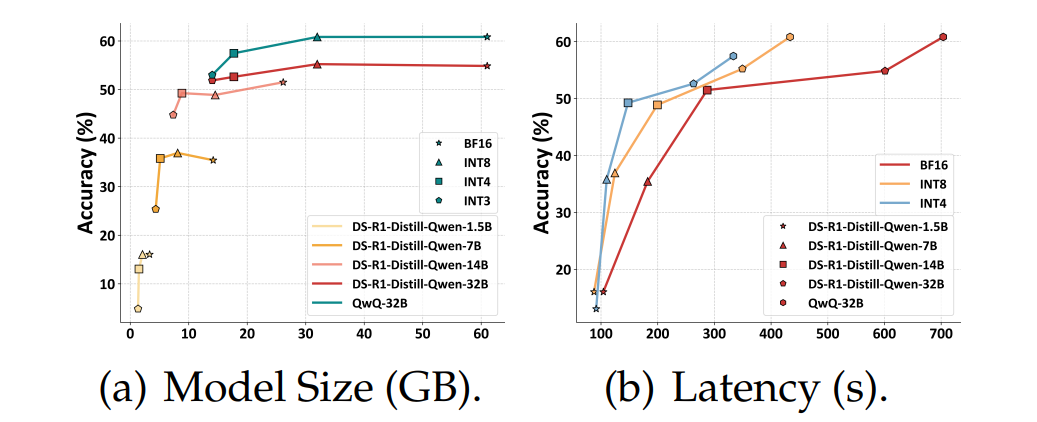
避坑指南:千万别给小型模型(如1.5B)强行上4位量化,否则它会像被压缩过度的图片一样“满屏马赛克”。
展望下未来
当前4位量化仍不稳定,但论文指出两个突破口:
针对性训练:让模型从小适应低精度计算,像运动员戴沙袋训练一样。
动态量化:根据任务难度自动切换精度,简单题用4位,难题切回8位。
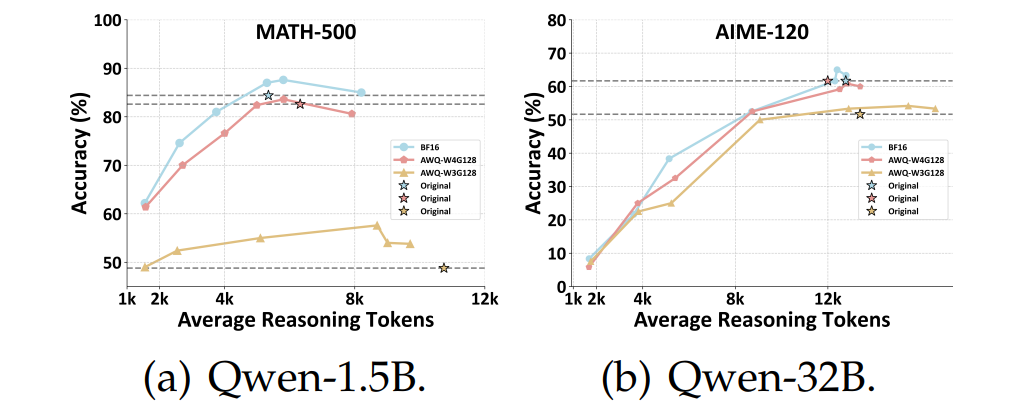 显示,适当增加推理步骤能部分弥补量化损失,但“过度思考”反而有害——这或许会催生新一代“智能压缩芯片”。
显示,适当增加推理步骤能部分弥补量化损失,但“过度思考”反而有害——这或许会催生新一代“智能压缩芯片”。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









