







 本文介绍了基于深度学习的缺陷检测方法,适用于特征不明显、形状多样的场景。通过介绍数据制作、网络结构设计、全连接层重建,以及识别定位结果的处理,展示了深度学习在工业缺陷检测中的潜力。
本文介绍了基于深度学习的缺陷检测方法,适用于特征不明显、形状多样的场景。通过介绍数据制作、网络结构设计、全连接层重建,以及识别定位结果的处理,展示了深度学习在工业缺陷检测中的潜力。
一、介绍
缺陷检测被广泛使用于布匹瑕疵检测、工件表面质量检测、航空航天领域等。传统的算法对规则缺陷以及场景比较简单的场合,能够很好工作,但是对特征不明显的、形状多样、场景比较混乱的场合,则不再适用。近年来,基于深度学习的识别算法越来越成熟,许多公司开始尝试把深度学习算法应用到工业场合中。
二、缺陷数据
如下图所示,这里以布匹数据作为案例,常见的有以下三种缺陷,磨损、白点、多线。


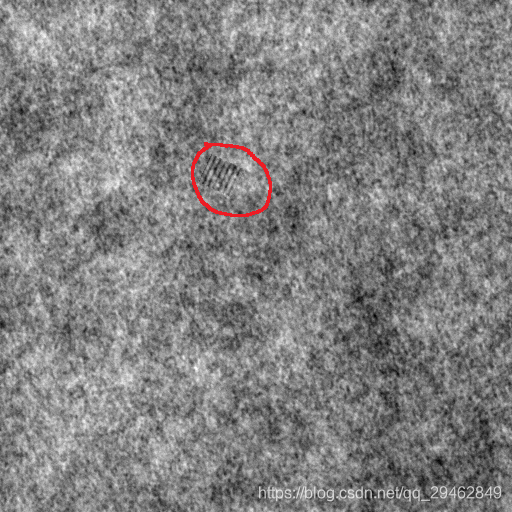
如何制作训练数据呢?这里是在原图像上进行截取,截取到小图像,比如上述图像是512x512,这里我裁剪成64x64的小图像。这里以第一类缺陷为例,下面是制作数据的方法。


注意:在制作缺陷数据的时候,缺陷面积至少占截取图像的2/3,否则舍弃掉,不做为缺陷图像。
一般来说,缺陷数据都要比背景数据少很多,没办法,这里请参考我的另外一篇博文,图像的数据增强https://blog.csdn.net/qq_29462849/article/details/83241797
最后通过增强后的数据,缺陷:背景=1:1,每类在1000幅左右~~~
三、网络结构
具体使用的网络结构如下所示,输入大小就是64x64x3,采用的是截取的小图像的大小。每个Conv卷积层后都接BN层,具体层参数如下所示。
Conv1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









