







yolov5网络的输入通道数对结果的影响
想法的由来
目前对于普通三通道图片的目标识别网络,基本都是以三通道的形式送入网络。
在一次测试中,看到了将三个通道分别显示为单通道的灰度图像,其实长得非常像(看起来是这样),随后又将每个通道比如R通道的数据按照8bit进行拆分,得到8个通道的数据,每个通道中,都只有0 或者1 ,显示出来一组具有纹理信息的图片。
或者将三通道进行整合为一个通道,具体做法是
//三通道输入
RGB / 255.0 //三通道分别归一化
//一通道输入
(R + G<<8 + B<<16) / (256*256*256) //三通道带权相加后归一化
//24通道输入
[R,R>>1,R>>2,R>>3,R>>4,R>>5,R>>6,R>>7]&1 //按位取值
猜一下各种优势,24通道能将信息拆分的更加细,1通道可以减少计算量。到底哪个好呢,做实验测试一下
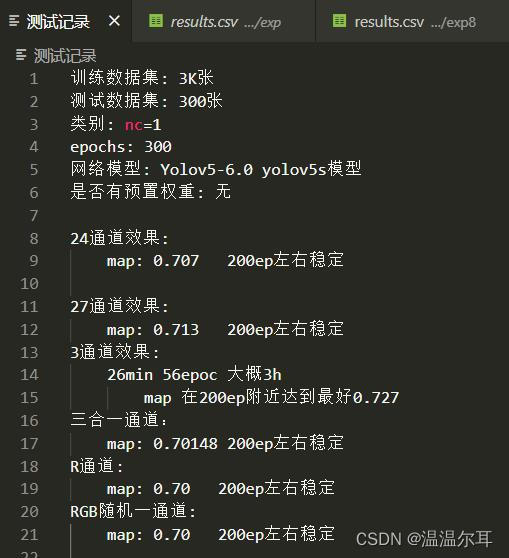
总之,RGB中任意一个通道的信息都足够让模型的map到达70
将三通道拆分为24个比特通道,效果并不好,可能是因为数据太散?
总之不明白数据是要散开还是聚合。。。怎么都没有3通道的好。
测试不同通道中信息量的大小
对与RGB三通道的图像,在送入网络训练之前将数据左移一位,也就是说去掉一个低维度信息,或者img&0x7F,也就是去掉一个高纬度信息。
结果来看,左移的效果和原图训练结果相似,略微降低(map下降0.005以内)。右移的效果差得多,map大概降低0.02左右















 7741
7741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









