






 腾讯AI-lab发布了一篇文章,提出一种利用额外的crossattn模块将参考图片信息注入到文本生成模型中,实现风格控制的同时保持主体内容不变。这种方法简洁且允许文本与图像信息解耦,后续研究如PuLID延续了这一方向。
腾讯AI-lab发布了一篇文章,提出一种利用额外的crossattn模块将参考图片信息注入到文本生成模型中,实现风格控制的同时保持主体内容不变。这种方法简洁且允许文本与图像信息解耦,后续研究如PuLID延续了这一方向。
URL
https://arxiv.org/pdf/2308.06721
TL;DR
23 年 8 月腾讯 AI-lab 的文章,目前 90+ 引用。通过一张参考图片来实现风格/ip 注入,来完成风格控制或者主体保持的任务。具体的实现方法是引入一个额外的 cross attn 模块来实现 img 的注入,和原本注入 text 信息的 cross attn 是并行关系。
以下是一些结果展示
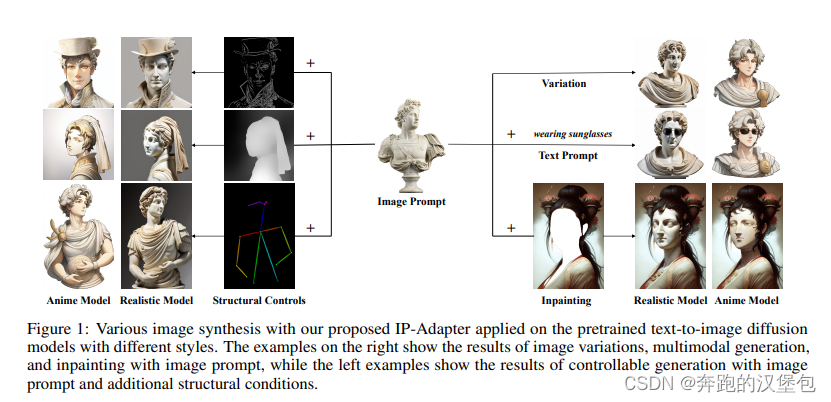
Model & Method
文章的 ppl 如下图所示,对每一层都加入了一个新的 cross attn 层,用来注入参考图的 img 信息,与原来用于注入 text condition 的 cross attn 是并行关系,两者的 feature 直接相加。这样就实现了 img 信息的注入,同时还可以保留 txt condition。
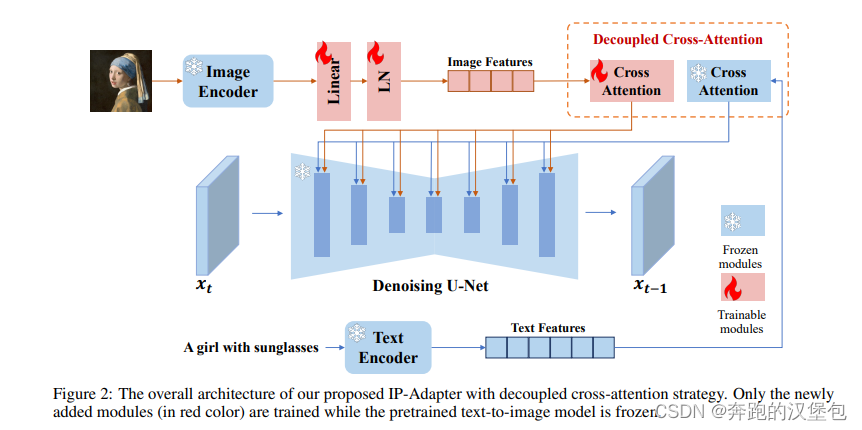
image encoder 使用的是 clip,在训练的时候 clip 是冻住的,只引入了一个额外可训的 linear+LN 层用于适配输入的 channel 数
由于整体的思路比较简洁清晰,所以不做过多赘述。
Dataset & Result
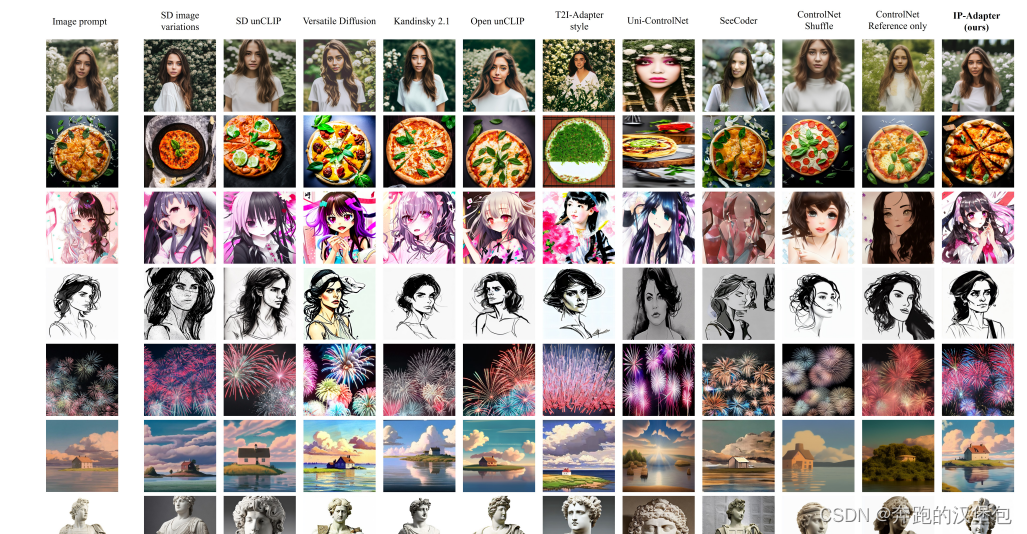
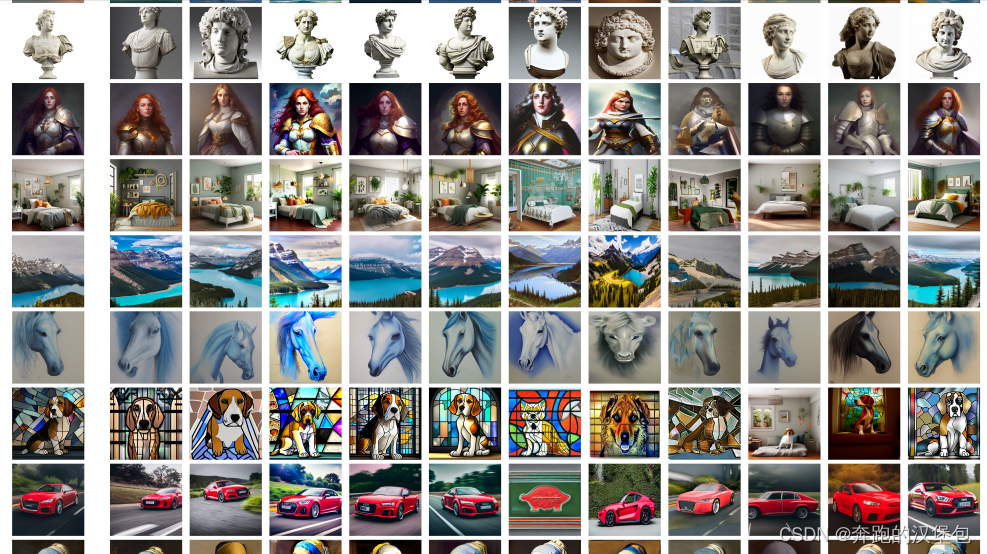
结果展示如下图

Thoughts
- 额外的 cross-attn 注入 img 信息,在与 text 信息交互的时候直接相加,这样是会与 text 信息相互影响的。比较明显的好处是做到了 txt 与 img 信息解耦。下一篇文章 PuLID 是很好的延续性工作















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









