






URL
https://arxiv.org/pdf/2307.09481
主页:https://github.com/ali-vilab/AnyDoor
TL;DR
23 年 7 月港大+阿里的文章。

提出一个可以指定物体和场景进行融合的模型,比如人物换装、角色场景变换等。只需要一次训练,就可以实现通用的物体融合、场景变换。个人分析:功能里面主要是物体在不同场景中的放置问题, ip 保持只是很小的一部分。因为大部分动作、表情都不会发生变化,只有场景交互发生变化了。(其实就是实际场景里面抠图之后的 inpainting 的操作?)
借助视频数据来做物体一致性的训练,文章表示视频数据包含了同一个物体的不同形式的信息,比如位置、姿态、背景等。
下面是作者给出的一个功能说明,分别是三行表示的简单放置、多物体放置、物体交换移动。比较感兴趣的是多物体放置,但是并没有特别强的交互性。
Model & Method
方法框架如下图,网络的输入有三部分,分别是 1> 左上角的场景,2> 放置位置,3> 左下角要放置的物体。
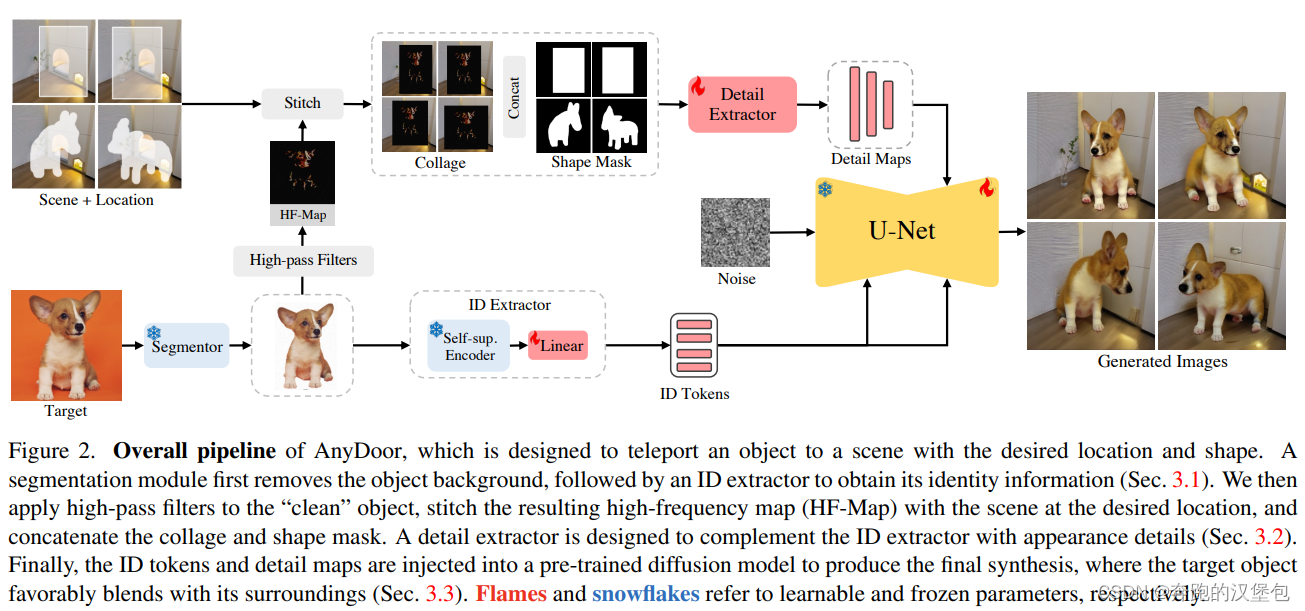
identity feature extraction:
-
首先把物体经过 segment 模型移除背景(和业务需求需要的输出一致),文章解释为 clip 作为 text encoder 粒度比较粗,如果引入背景则会更加弱化对原物体的特征
-
image encoder 选择的是自监督模型 DINO-v2 backbone,将其输出的 global token 和 patch token cat 到一起,训练一个 linear 层来完成物体的特征提取。
Detail feature extraction:因为上述提到的特征会更加关心粗粒度、全局的特征,因此文章补充了一个用于细节保持的特征。大概流程:
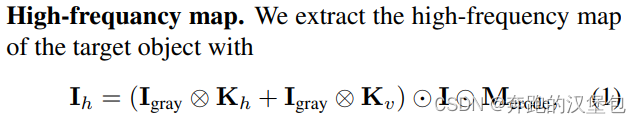
-
首先把移除背景的物体,经过 high frequency map 提取器得到图片中的高频纹理,公式如下(其实就是 sobel + erode)
-
然后把高频纹理和输入的场景拼接起来,送到另一个 unet encoder 中得到细节特征,然后和上面的 id 特征一起作为 condition 训练模型
-
至于为什么是高频纹理,而不是把原物体直接拼接到给出的场景和位置处,文章给出的解释是那样的话基本就只会生成原物体动作、表情的结果了。
Feature injection -
训练的时候,把 unet encoder 冻住,finetune unet decoder
-
其中 id token 是通过 cross attention 和文本特征一起注入 unet 中做训练
-
Detail 特征就沿用了 control net 的训练方式直接加在了 decoder 特征之后。
Dataset & Results
数据方面,由于训练数据是视频序列,所以文章提出的 ppl 所有数据都可以通过视频不同帧提取得到,示意图如下。
即随机选择两帧,其中一帧取 mask 后得到物体图片;另一帧取 mask 后作为场景+位置的输入,同时原图可以作为 gt

结果
首先文章和不需要 finetune 的方法做了比较,如下图。可以看出本文的方式最显著的优势是 ip 保持能力比较突出(不是很 fair)

和需要 finetune、reference 的方法比,结果如下图。文章主要 argue 的点在于本文的多物体保持和放置能力比较强。

消融实验
- ID extractor 的对比,主要是 clip 和本文的自监督模型。可以看出本文用的自监督模型明显优于 clip

- 拼接使用的格式,如下图。本文最终使用 high frequent 纹理,这里给出了其他格式的对比。

Thought
- 自监督的 image extractor 模型是不是真的好用?需要研究一下,这里要引入额外的训练成本,即一个 linear
- 感觉即使是高频信息,也还是只会生成原物体动作的结果,这一步给人感觉很生硬。想了想文章的训练数据是视频,可能数据量比较大不会明显过拟合,但预计不能生成动作幅度变化太大的结果
- 文章虽然一开始说了多物体的事情,其实多物体就是多次抠图 + 放置,没有一个一次性的方案。















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









