







本研究全面回顾了低光行人检测方法的最新发展。系统地分类和分析了从基于区域的到非区域的以及基于图的机器学习方法论,突出他们的方法论、实现问题和挑战。全面了解暗光条件下的目标检测算法
行人检测已成为许多高级任务的基础,包括自动驾驶、智能交通和交通监控。针对可见图像的行人检测研究主要集中在白天。然而,当环境条件变为恶劣的照明或夜间时,这个任务变得非常有趣。
最近,由于使用替代来源的想法被激发,例如使用远红外(FIR)温度传感器输入用于在低光条件下检测行人。本研究全面回顾了低光行人检测方法的最新发展。它系统地分类和分析了从基于区域的到非区域的以及基于图的机器学习方法论,通过突出他们的方法论、实现问题和挑战。
它还概述了可以用于研究和发展高级行人检测算法的关键基准数据集,特别是在低光情况下。
1 Introduction
行人检测已成为现代智能交通系统(ITS)、安全和监控等视觉应用的基础。它是从数据采集设备(如视觉摄像头和热电堆传感器)的输入数据中识别人类运动的过程,用于对场景进行语义理解。与其他形式的物体检测相比,行人检测更重要,因为它直接关系到人们的生命安全。因此,它有严格的操作标准,如更高的检测准确率和实时性能,这对上述智能系统至关重要。为了解决这个问题,计算机视觉和机器学习研究人员通过利用技术进步,提出了几种方法,如图1所示。
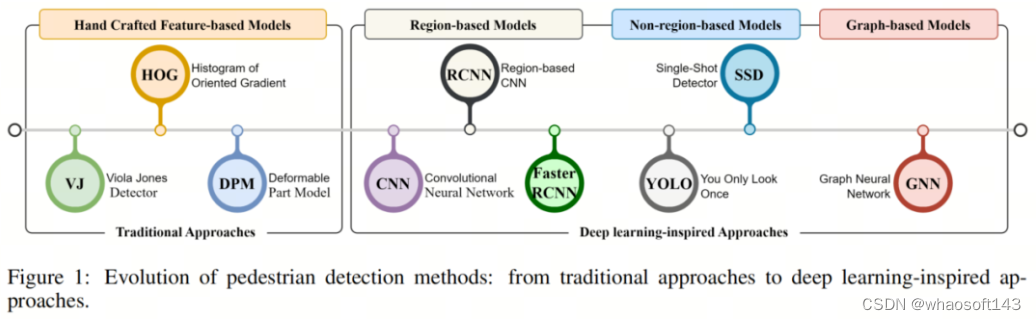
Evaluation of Pedestrian Detection
行人检测任务主要经历了人工智能(AI)的两个重要时期 - 传统的机器学习(ML)基础的目标检测时期和现代深度学习(DL)基础的目标检测时期。传统方法可能起源于Viola和Jones提出的第一张人脸检测器,使用Haar级联特征。后来,它被用于其他目标检测任务,包括行人检测。
在这个领域,Dalal和Triggs提出了HOG描述子,特别是用于精确行人检测。这个描述子通过计算输入图像中特定局部区域的梯度幅度和边缘方向来关注目标的结构性信息。由于它使用梯度幅度和角度创建直方图特征,因此优于其他当代描述子。
随后,Felzenszwalb等人引入了DPM用于目标检测,该模型可以使用滑动窗口将行人分类到多种不同的部分。这种算法在多个应用中一直产生最佳检测结果;然而,滑动窗口方法在遍历所有可能的位移和窗口大小时比计算资源更加沉重,因为它需要遍历每个可能的位置和窗口大小比例。
在深度学习时代的出现中,RCNN被引入用于使用结构化的多层神经网络中的卷积操作进行层次特征提取。这种方法主导了目标识别/检测任务的发展,并完全将其转移到深度学习范式中。在RCNNs中ROI是通过在选择性搜索操作上进行训练的目标分类器和边界框回归器来提出的。这种策略通常被认为是一种两阶段的检测框架,其中第一阶段是特征提取器,第二阶段是目标检测器。
为了克服RCNN的缺点,如严格的训练过程和延长的检测时间,开发了Fast-RCNN 和 Faster-RCNN 模型作为基线RCNN模型的改进版本。然而,基于区域的途径仍然面临检测速度慢的局限性,这对于实时应用来说是不希望的。
例如,当涉及到检测行人,特别是自动驾驶应用以防止事故时,检测速度至关重要。为了应对基于区域的物体检测器的局限性,也称为非区域技术的一阶段检测器,包括YOLO,SSD和 RetinaNet 等技术被引入。这些模型的检测速度显著提高,因为每个区域的物体边界框和类别概率是同时预测的。通过在特征图上放置一系列Anchor点,与两阶段检测框架相比,一阶段检测模型可以立即预测物体中心和物体边界框。
Motivation
在自动驾驶环境中,在瞬间检测到行人的鲁棒机制是一项艰巨的任务,特别是在低光环境中。为了解决这个问题,最近的研究工作集中在特征增强和行人准确检测的融合技术上。这激发了本研究对基于融合的低光图像增强技术进行全面回顾,以及使用可见和红外图像在低光环境中进行行人检测。
虽然最近有许多行人检测算法方面的调查文章发布,但关注低光或夜间行人检测的研究非常少。为此,本文实际调查了低光环境下的行人检测关键方法论,以及它们的基本实现问题和挑战。
Overview of the Existing Relevant Surveys and the Contributions of this Study
总的来说,现有的调查主要覆盖了目标检测方法的一些方面,并没有分析最先进的基于图的学习策略,特别是对于在低光条件下的行人检测。例如,Ahmed等人和Sobbahi和Tekli研究了在低光环境中的物体检测改进。
另一方面,Ahmed等人,Cao等人,Xiao等人没有研究低光环境下的行人检测算法的挑战。在现有的调查中,Anirudh等人提供了一种低光物体检测技术的概述。那份调查评估了几种低光图像增强方法,包括灰度变换、直方图均衡化、Retinex-based技术、频域分析、图像融合和去雾。
与传统方法相比,作者认为基于深度学习的模型将低光图像增强视为残差学习问题,并且在提高低光图像质量方面表现出鲁棒性。
另一方面,Ahmed等人关注了各种基于深度学习的物体检测算法,如Faster R-CNN、Mask R-CNN、SSD、YOLO、Retina-Net和Cascade Mask R-CNN,通过实证分析来评估它们的计算效率。Sobbahi和Tekli提供了一项关于低光图像(LLI)增强的基于深度学习方法的比较研究。
他们的研究处理了低光图像增强两种策略:(a)一个离线的独立图像增强任务,(b)将图像预处理阶段集成到端到端训练模型中以实现高级计算机视觉任务的一个在线预处理阶段。然而,[12]并未扩展到低光行人检测的讨论。
Dhillon和Verma回顾了各种CNN架构,突出了它们的特征,重点关注三个应用-野生动物检测、轻武器检测和人类检测。与此同时,另一个调查的作者回顾了行人识别和意图评估的进步。这份调查在算法方面类似于,具体来说是深度学习模型,而在本研究中覆盖了这些模型。然而,它们之间的主要区别如下。
虽然关注于通用物体检测,但从自动驾驶的角度关注行人和自行车检测。Xiao等人也回顾了处理被遮挡和多尺度行人检测问题的基于深度学习的行人检测算法。Cao等人提供了关于行人检测特征选择策略的广泛回顾。他们的研究包括使用人工构建的特征、深度特征(即基于CNN的特征)以及手工制作和深度特征的模型。
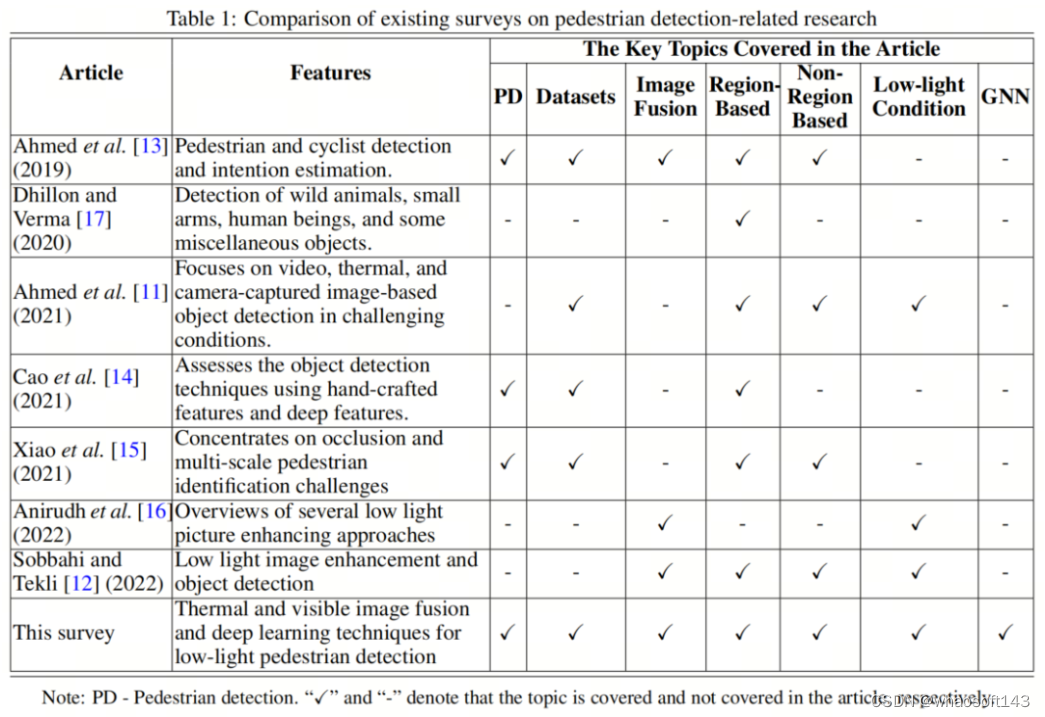
表1总结了领域内现有调查论文与本篇文章的区别。总的来说,本文的主要贡献如下。
-
对可见和红外(IR)融合技术以及深度学习方法进行行人检测在低光环境下的分类审查。
-
低光行人检测基准数据集的全面概述。
-
深入讨论主要的研究空白和建议新兴研究路径。
Organization
如图2所示,第一部分奠定了行人检测的基础和概念,并阐述了本研究的意义。第二部分详细分析了先进的行人检测算法及其挑战。它分为两个子部分--使用融合策略的输入增强和行人检测模型。输入增强子部分检查了几个RGB和IR数据融
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









