










 本文详细介绍了一种通用的不定长报文发送和接收方法,包括发送端如何构造报文和接收端如何解析报文的具体步骤。针对传输过程中的常见问题,如错码、少码、多码、粘包等,提供了详细的解决方案。
本文详细介绍了一种通用的不定长报文发送和接收方法,包括发送端如何构造报文和接收端如何解析报文的具体步骤。针对传输过程中的常见问题,如错码、少码、多码、粘包等,提供了详细的解决方案。
1、发送端
对于通用的不定长报文的发送和接收,其结构体,必须具备以下字段:
#pragma pack(1) //单字节对齐
typedef struct _Frame
{
uint8_t head;//head也可以为uint16、uint32。这里假设为0xA5(随便你怎么定)
uint8_t type;//数据类型标记(推荐定义为枚举类型)
uint8_t len;//下面的data内存区的长度
uint8_t data[1];
//data[len]为校验和
}Frame;//报文主体结构
#pragma pack() //对齐结束
结构中各个字段的意义如下:
pragma pack 编译器字节对齐指令,对于协议字节流传输,一般是单字节对齐。
head:报文头,用于接收方识别报文的起始字节。
type:标识data区域的数据类型,接收方要根据此字段来解析data域的内容。推荐将该字段用枚举来定义,以增强可读性。
len:data域的长度。注意,有些简单的项目中,根据type就能确定出data域的长度,此种场景可以不要len域。甚至更简单的项目中,只传输一种数据类型,那么type域和len域都可以不要。
data:真正的数据的指针。理论上,应当在结构体中把该数组定义为0元数组,也即:uint8_t data[0]; 但是有些编译器不支持,为了兼容性,退而求其次,定义成了一元数组。
sum:和校验sum check,也即:从报文头(含)到data域(含)的所有字节的和的低8位。由于data域的长度不确定,所以sum字段无法出现在这个结构体中,但是它的位置可以用data指针索引到,也即 data[len]的位置,就是校验位的位置。在可靠性要求更高的场合,可能不会使用u8和校验,而是u32和校验、或者CRC16、CRC32等校验方式。和校验的可靠性只有99%,而CRC的可靠性可以达到99.999%。
总报文的结构示意图如下: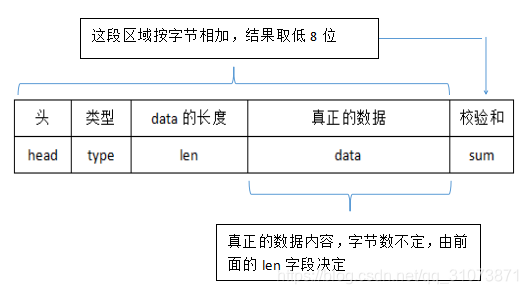
假设你要使用Frame结构传输数据,数据的内容可能是uint32、可能是double、还可能是任意结构体,如下面的Info结构。到底要传输什么,则依赖于Frame结构中的type字段来区分。
#pragma pack(1) //单字节对齐
typedef struct _Info
{
uint16_t voltage;//电压
float current;//电流
uint32_t time;//运行时间
}Info;
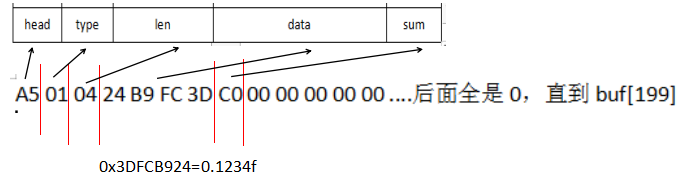
#pragma pack() //对齐结束 情形1:发送一个float数据。
//宏定义head + type + len的字节数
#define FRAME_HEAD_LEN sizeof(pFrame->head) + sizeof(pFrame->type) + sizeof(pFrame->len)
uint8_t buf[200];
memset(buf, 0, 200);//这一行可以不要
Frame *pFrame = (Frame*)buf;
pFrame->head = 0xA5;
pFrame->type = 1;// 1代表要发送float数据(由你的喜好或者需求来定义)
pFrame->len = sizeof(float);
float power = 0.1234f;
memcpy(pFrame->data, &power, sizeof(power));
pFrame->data[pFrame->len] = checksum(buf, FRAME_HEAD_LEN + pFrame->len);//从head到data做校验上述代码的作用是,组包一个合法报文,放到了buf数组中,代码结束后,buf中的内容为:
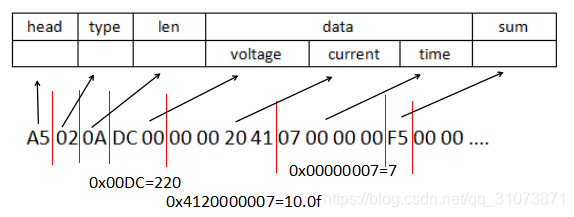
情形2:发送一个自定义结构
uint8_t buf[200];
memset(buf, 0, 50);
Frame *pFrame = (Frame*)buf;
pFrame->head = 0xA5;
pFrame->type = 2;
pFrame->len = sizeof(Info);
Info *pInfo = (Info*)pFrame->data;
pInfo->voltage = 220;
pInfo->current = 10.0f;
pInfo->time = 7;
pFrame->data[pFrame->len] = checksum(buf, FRAME_HEAD_LEN + pFrame->len);此代码会在buf内存区生成这样的报文:
如果你的需求比较简单,可以从结构体中删掉一些你不想用的字段,例如,你只想传输uint16数据,那么接收方无需判定type字段,也能知道data域是个u16,接收方无法判定len字段,也能知道data域的长度为2字节。
本文由【暴躁的野生猿】发表于CSDN,如有非法转载请帮忙举报谢谢。
2、接收方
接收方的接收到报文以后,进行解析,这才是收发报文的核心。如何判定收到了一帧完整的报文,如何判定这帧报文是否正确等等。
2.1 方法1.超时判定
一种简单的办法是,发送方每发一包数据,都延时一下再发下一包,这样接收方就可以通过定时器超时,来判别出一包数据接收完成。这种方法的所适用的应用场景非常受限:接收方的报文处理函数的调度速度 > 报文的时间间隔。注意:不是CPU的速度,而是处理函数的调度速度。
例如,发送方用115200串口发送,前后两帧报文的时间间隔为1ms。接收方如果是电脑,不论是win还是linux,不论CPU多强,都无法用利用超时的方法分离开这两帧报文,因为他们是软实时操作系统。但是cpu很弱的低价单片机,却能够利用中断给分离开。如果前后两帧报文的时间间隔为1秒,那么PC基本上就可以使用这种方法了。为啥是基本上?因为如果数据来源于无线链路,有时候数据可能会被延迟达数秒,此时该方法又失效了。无论怎么扩大这个时间间隔,总有失败的几率。
此方法不具备通用性。但好在简单,推荐用在本地传输,且硬实时平台上。
2.2 方法2.缓存分析
此方法不直接处理接收到的字节,而是先把接收到的所有字节,都放入缓存中,然后使用while(1),从缓存的头上一点点分析,并分离出一包一包的报文。已校验成功的报文,就从缓存中删掉;校验失败的报文,就从缓存中删掉一个字节,然后while(1)会从下一个字节继续分析(为何校验错误,不把这条报文整条从缓存中删掉?请看下文分析)。
使用此方法,接收方面临的问题【有且仅有】6个。接收方,必须处理这6种情形,缺一不可,多了没用。
问题:
1、错码。在传输报文过程中,某个字节因线路干扰,出现了错误。
2、少码。一帧报文中,任意位置丢了一个或多个字节。
3、多码。一帧报文中,任意位置多出了一个或多个字节。
4、粘包。连续N帧报文字节流中,没有时间间隔,一口气收到了N包数据,也有可能是N.x包数据(最后一包不完整)。
5、不完整包。因传输延迟,导致一帧报文收到了一半,另一半在N秒后才收到。
6、报文的数据域(或者其他域)含有报文头。上面的例子中,我定义了0xA5为头,可想而知,data域出现0xA5并不稀奇,甚至极其频繁。len也很有可能为0xA5。所以解析报文时,收到了0xA5并不一定真的是head,需要配合后续字节综合判断。
问题分析:
对于问题123,一定会导致该报文校验通不过。但是需要注意,这只是充分条件,而不是充要条件。反过来,报文校验不过,不一定是问题123,还有可能是问题6。
对于问题4/5,可能内部又会混合错码少码多码的情形。
对于问题6,不要期望用复杂报文头(例如增加报文头的字节数)来规避,无论你怎么定义报文头,data域总有几率出现与报文头一模一样的情况发生。解析程序必须具备处理这种场景的能力,如果不处理,一旦几率出现,轻则本条报文数据丢失,重则程序卡死在while(1)里,是灾难性的。
对于问题5,对于不完整包,就让他待在缓存里,等待下次报文到了,凑齐了再继续处理(也可能下次报文到了仍然凑不齐这帧报文)。那如何判定是不是不完整包? 直接判别是很复杂的,仅举一例:假设缓存中剩余的内容为 head type len xx, 根据len判断后续应该还是len+sizeof(sum)个字节,而此时len后面仅有一个xx,那就判定为不完整报文。此方法错误, 因为len存在误码的几率,如果len误码后的值为60000,你还要继续等待60000个字节才处理吗? 如果type误码了呢?如果head和type之间多了一个字节呢?等还是不等?
最简洁的不完整包判别方法是:要么报文确定合法(只有一种可能:校验通过),要么报文确定不合法(原因有3:校验失败、或type脱离了合法范围、或len脱离了type定义的合法范围),其余都认定为不完整报文。
判别出不完整包的意义在于:不把这些剩余字节从缓存中清除,而是继续等待后续报文,等待拼接。如果把它们从缓存中清掉了,即使待会儿后续报文到了,这些后续报文无头,也无法被解析了,造成丢包。
下面直接提供一个完善的解析框架,可以处理掉前述的6种异常情形, 因大家的编程平台不一样,这里仅提供C++风格的伪代码。对于单片机等纯C平台,自己实现一下FIFO缓存队列(或者直接抄袭Linux内核的kfifo),也能用以下框架。
下面这个while(1)每次最多只处理掉一条合法报文,如果缓存中有N.x条合法报文,那么这个while至少会循环N+1次才会退出,如果里面存在误码多码等异常情形,循环次数会 > N+ 1
/*
对于单片机平台,可以每收到一个字节,或者每一个传输中断,都调一下本函数
对于操作系统平台,可以在每次接收事件时,调一下本函数
*/
void receiveBytes(QByteArray bytes)
{
frameBuf.append(bytes);//把收到的字节都缓存起来
while(1)//该循环把缓存分析完之后,会退出。(分析完缓存,并不不是说缓存数据都删干净了,有可能该循环退出以后,缓存中尚存在一个不完整包,等下次进入本函数后会拼接起来)
{
int stc_offset = getHeadOffset((const char*)frameBuf.constData(), frameBuf.count());//在未处理掉的缓冲区中寻找head,返回报文头的位置。没有找到报文头则返回负数
if(stc_offset < 0)//整个缓冲区都找不到报文头
{
frameBuf.clear();//全是废报文,清空缓冲区
break;
}
else
{
frameBuf.remove(0, stc_offset);//删除head前面的废报文
}
//开始处理head打头的报文(有可能是假head,下面会处理掉这种情况)
int8_t retval = parseOneFrame((const Frame *)frameBuf.constData(), frameBuf.count());//解析did等
if(retval > 0)//报文合法
{
frameBuf.remove(0, retval);//把这条合法报文从缓存中删掉
}
else if(0 == retval)//不完整包,则退出while循环等待下次拼接
{
break;
}
else // <0, head打头但是报文有误(包括但不限于:校验失败、数据域长度与type不匹配、type不可识别等)
{
frameBuf.remove(0, 1);//删掉一个字节,然后立即进行下一轮循环,继续向下分析
}
}
}上面的代码用到了2个函数:getHeadOffset、 parseOneFrame。
getHeadOffset 比较简单,就是搜索head。
parseOneFrame 如下:
/*
功能:处理一条head打头的报文(有可能是假head)
参数:报文缓冲首地址pFrame,缓存中未处理的字节数leftLen
返回:报文合法则返回本条报文的长度;报文不合法返回-1(尾巴校验错误、数据域、type错误等等);无法确定合法不合法回0(例如报文不完整)
FRAME_HEAD_LEN 包括了head type len这3个字段的长度
*/
int16_t parse_data_from_one_frame(const GFrame *pFrame, int16_t leftLen)
{
if(!typeVaild(pFrame->type))//查询type的值是否在合法范围内
return -1;//如果是个假head,很容易就会走到这里
if(leftLen <= FRAME_HEAD_LEN)//字节数太少,无法做进一步判定
return 0;//只能当做不完整包
//查询type对应的data域的长度的合法范围
DidLenLimit lenScope = getValidLenScope(pFrame->type);
//尚未收到校验位,无法判定是否合法
if(leftLen < FRAME_HEAD_LEN + lenScope.minLen + FRAME_CHECK_LEN)
{
return 0;//当做不完整包
}
//len域脱离了合法范围
if((pFrame->len > lenScope.maxLen) || (pFrame->len < lenScope.minLen))
{
return -1;//len有误,要么是假head,要么报文出错
}
//len范围合法,但尚未收到校验位,无法判定整个报文是否合法
if(leftLen < FRAME_HEAD_LEN + pFrame->len + FRAME_CHECK_LEN)
{
return 0;//当做不完整包
}
//计算校验位
uint16_t calValue = checkSum((uint8_t*)pFrame, FRAME_HEAD_LEN + pFrame->len);
//与收到的校验位比对
if(pFrame->data[pFrame->len] != calValue)//
{
return -1;//校验失败
}
//至此校验成功,根据type解析出data域数据
parseDataField(pFrame->type, pFrame->data, pFrame->dataLen);//见附录示例函数
//至此,报文合法,并且data已提取完成,返回该条报文的总长度
return FRAME_HEAD_LEN + pFrame->len + FRAME_CHECK_LEN;//合法报文的实际长度;
}本文由【暴躁的野生猿】发表于CSDN,如有非法转载请帮忙举报谢谢。
附录:示例函数:
/***************************************************************
函数名:checksum
描 述:u8和校验
输入值:*data 数据指针 len 数据长度
输出值:无
返回值:uint8 cs
***************************************************************/
uint8_t checksum(uint8_t *data,uint8_t len)
{
uint8_t cs = 0;
while(len-- > 0)
cs += *(data++);
return cs;
}/*
功能:根据type解析data域的数据
参数:数据类型type, data数据域指针, len数据域长度
*/
void parseDataField(uint8_t type, uint8_t data[], uint8_t len)
{
if(1 == type)//data域是个float
{
float power = *((float*)data);//读出收到的float数据
}
if(2 == type)//data域是个struct Info
{
Info *pInfo = (Info *)data;
uint16_t vol = pInfo->voltage;//从收到的报文中取出:电压
float cur = pInfo->current;//电流
uint32_t t = pInfo->time;//运行时间
}
}
如果想把这段代码写的更规范,可以用switch-case
switch(type)
{
case 1: parseFloat(data);break;
case 2: parseInfo(data);break;
default:;
}
更专业的写法可以把type和处理函数做成数组(或者Map映射结构),解析时由type索引到处理函数的指针。代码会更简洁,只需一行代码就能处理所有的type
map[type](data);

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









