







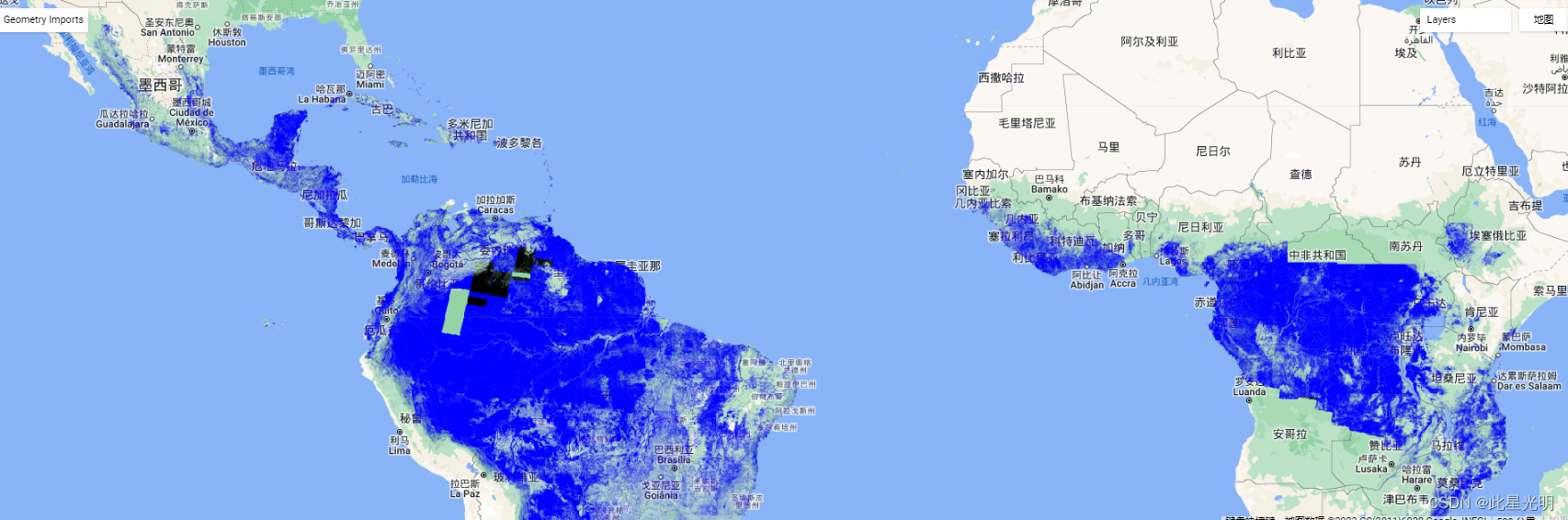
这里我们使用散点图,通过建立函数来构建一个散点图。
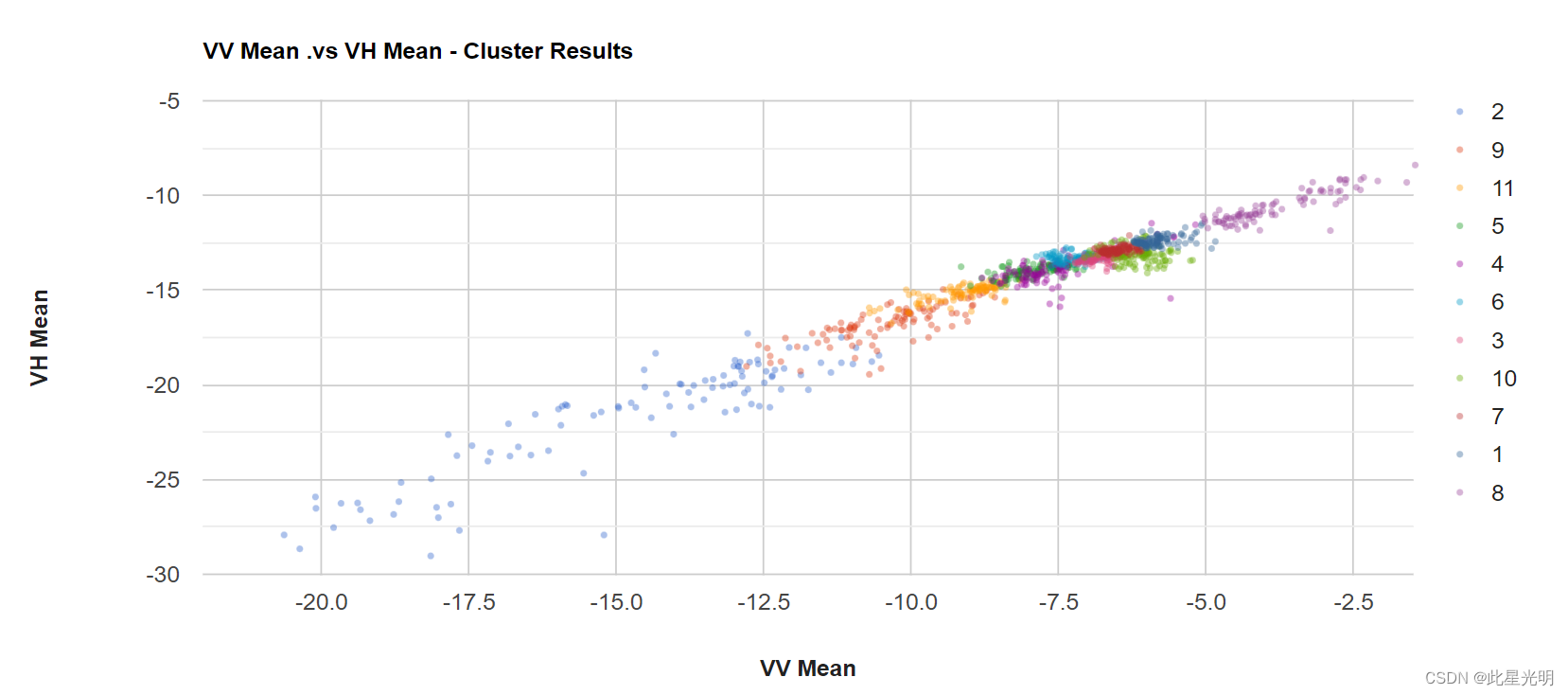
函数:
ui.Chart.feature.groups(features, xProperty, yProperty, seriesProperty)
Generates a Chart from a set of features. Plots the value of a given property across groups of features. Features with the same value of groupProperty will be grouped and plotted as a single series.
-
X-axis = xProperty values.
-
Y-axis = yProperty values.
-
Series = Feature groups, by seriesProperty.
Returns a chart.
Arguments:
features (Feature|FeatureCollection|List<Feature>):
The features to include in the chart.
xProperty (String):
Property to be used as the label for each feature on the x-axis.
yProperty (String):
Property to be plotted on the y-axis.
seriesProperty (String):
Property used to determine feature groups. Features with the same value of groupProperty will be plotted as a single series on the chart.
Returns: ui.Chart
cluster(clusterer, outputName)
Applies a clusterer to an image. Returns a new image with a single band containing values from 0 to N, indicating the cluster each pixel is assigned to.
Arguments:
this:image (Image):
The image to cluster. Must contain all the bands in the clusterer's schema.
clusterer (Clusterer):
The clusterer to use.
outputName (String, default: "cluster"):
The name of the output band.
Returns: Image
CLOSE
ee.Clusterer.wekaKMeans(nClusters, init, canopies, maxCandidates, periodicPruning, minDensity, t1, t2, distanceFunction, maxIterations, preserveOrder, fast, seed)
Cluster data using the k means algorithm. Can use either the Euclidean distance (default) or the Manhattan distance. If the Manhattan distance is used, then centroids are computed as the component-wise median rather than mean. For more information see:
D. Arthur, S. Vassilvitskii: k-means++: the advantages of careful seeding. In: Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, 1027-1035, 2007.
Arguments:
nClusters (Integer):
Number of clusters.
init (Integer, default: 0):
Initialization method to use.0 = random, 1 = k-means++, 2 = canopy, 3 = farthest first.
canopies (Boolean, default: false):
Use canopies to reduce the number of distance calculations.
maxCandidates (Integer, default: 100):
Maximum number of candidate canopies to retain in memory at any one time when using canopy clustering. T2 distance plus, data characteristics, will determine how many candidate canopies are formed before periodic and final pruning are performed, which might result in exceess memory consumption. This setting avoids large numbers of candidate canopies consuming memory.
periodicPruning (Integer, default: 10000):
How often to prune low density canopies when using canopy clustering.
minDensity (Integer, defaul
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











