







目录
GHSL: Global population surfaces 1975-2030 (P2023A)
GHSL: Global population surfaces 1975-2030 (P2023A)
简介
该栅格数据集描述了居住人口的空间分布,以单元居民的绝对数量表示。 1975 年至 2020 年的居住人口估计值以 5 年为间隔,2025 年和 2030 年的人口预测值则来自 CIESIN GPWv4.11,这些人口预测值从普查或行政单位分解到网格单元,并参考了 GHSL 全球建成区地表图层中每一纪元建成区的分布、体积和分类。
有关全球人类居住图层主要产品的更多信息,请参见[全球人类居住图层数据包 2023 报告](https://ghsl.jrc.ec.europa.eu/documents/GHSL_Data_Package_2023.pdf?t=1683540422)。 全球人类居住图层(GHSL)项目得到了欧盟委员会、联合研究中心以及区域和城市政策总局的支持。
摘要
Dataset Availability
1975-01-01T00:00:00 - 2030-12-31T00:00:00
Dataset Provider
Collection Snippet
Copied
ee.ImageCollection("JRC/GHSL/P2023A/GHS_POP")
Resolution
100 meters
Bands Table
| Name | Description |
|---|---|
| population_count | Population count by epoch |
代码
var baseChange =
[{featureType: 'all', stylers: [{saturation: -100}, {lightness: 45}]}];
Map.setOptions('baseChange', {'baseChange': baseChange});
var image1975 = ee.Image('JRC/GHSL/P2023A/GHS_POP/1975');
var image1990 = ee.Image('JRC/GHSL/P2023A/GHS_POP/1990');
var image2020 = ee.Image('JRC/GHSL/P2023A/GHS_POP/2020');
var populationCountVis = {
min: 0.0,
max: 100.0,
palette:
['000004', '320A5A', '781B6C', 'BB3654', 'EC6824', 'FBB41A', 'FCFFA4']
};
Map.setCenter(8, 48, 7);
image1975 = image1975.updateMask(image1975.gt(0));
image1990 = image1990.updateMask(image1990.gt(0));
image2020 = image2020.updateMask(image2020.gt(0));
Map.addLayer(image1975, populationCountVis, 'Population count, 1975');
Map.addLayer(image1990, populationCountVis, 'Population count, 1990');
Map.addLayer(image2020, populationCountVis, 'Population count, 2020');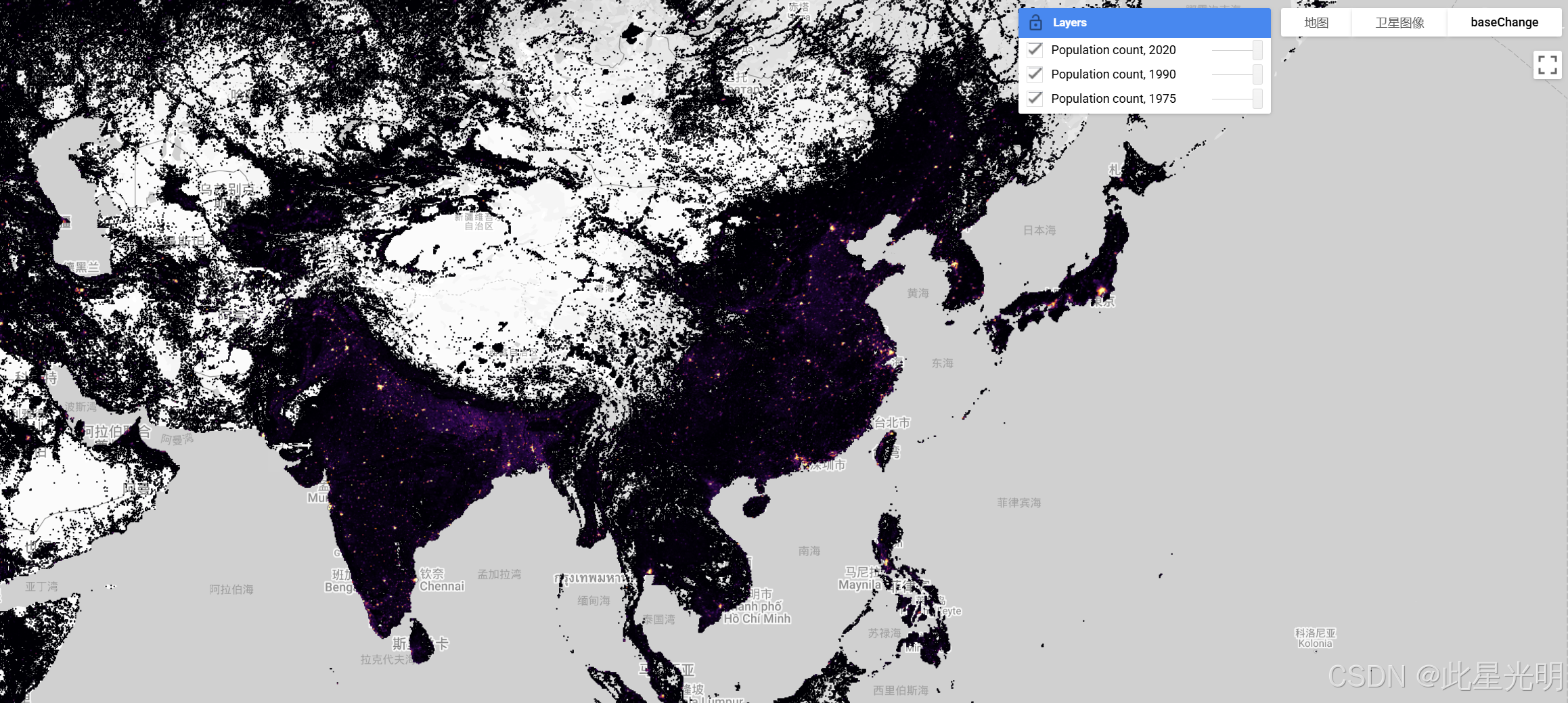
引用
Dataset : Pesaresi, Martino; Politis, Panagiotis (2023): GHS-BUILT-S R2023A - GHS built-up surface grid, derived from Sentinel2 composite and Landsat, multitemporal (1975-2030). European Commission, Joint Research Centre (JRC). PID: http://data.europa.eu/89h/9f06f36f-4b11-47ec-abb0-4f8b7b1d72ea doi:10.2905/9F06F36F-4B11-47EC-ABB0-4F8B7B1D72EA
Methodology : Pesaresi, Martino, Marcello Schiavina, Panagiotis Politis, Sergio Freire, Katarzyna Krasnodebska, Johannes H. Uhl, Alessandra Carioli, et al. (2024). Advances on the Global Human Settlement Layer by Joint Assessment of Earth Observation and Population Survey Data. International Journal of Digital Earth 17(1). doi:10.1080/17538947.2024.2390454.
网址推荐
知识星球
机器学习
干旱监测平台
慧天干旱监测与预警-首页https://www.htdrought.com/![]() https://www.htdrought.com/
https://www.htdrought.com/



















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











