







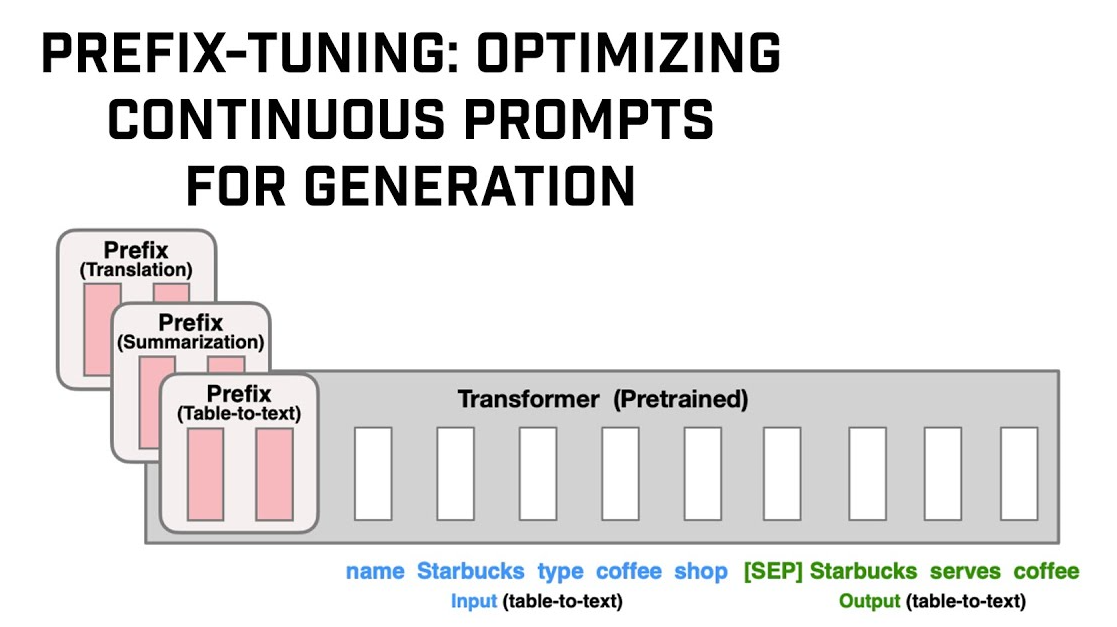
Prefix Tuning是LLM微调技术中另一个重要的技术分支,于2021年由Stanford提出。
本文通过解读论文**《Prefix-Tuning: Optimizing Continuous Prompts for Generation》**,与小伙伴们一起学习理解Prefix Tuning思想和方法。
1.Abstract(摘要)
首先我们看一下论文摘要,快速理解论文的核心内容:
-
问题:**FFT(全参数微调)**针对不同的下游任务都需要产生一个新的微调后大模型,存在成本效率等诸多工程问题。
-
解决方案:论文提出的
Prefix Tuning,是一种使用Soft Prompt(软提示)进行迁移学习的方法。针对不同下游任务创建不同的Prefix(前缀向量模块),这样不同下游任务只需要在一套预训练大模型上加载不同Prefix小模型即可。 -
实验效果:
- 在GPT-2的
Table-To-Text(表格生成文本)下游任务中,Prefix模型参数仅占GPT-2参数的0.1%,即可达到GPT-2同等水平。 - 在BART的
Sumarization(摘要)下游任务中,Prefix模型参数仅占BART参数的0.1%,即可达到BART同等水平。 - 在上述两种实验中,额外还观察到一定的泛化涌现能力,
Prefix Tuning可外推到训练期间未见过的任务主题。
- 在GPT-2的

2.Introduction(介绍)
-
背景技术1:Adapter Tuning是向预训练模型中增加新的小模型,仅微调小模型参数以达到高效微调的目的。实验效果证明仅需微调2%~4%的参数即可达到全参数微调的效果。
- Adapter Tuning的详细解读可参见本技术专栏这篇文章《【chatGPT】学习笔记43-LLM微调技术之Adapter Tuning》
-
背景技术2:GPT-3的一个重要贡献就是Context Learning和Prompt Engineering,GPT-3是一套统一的大语言模型,用户不需要针对下游任务单独微调,直接通过提示词和上下文,影响GPT-3输出的答案。
-
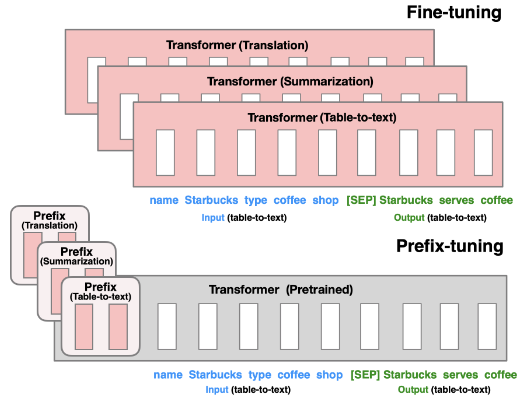
Prefix Tuning的核心思想:Prefix Tuning借鉴了Adapter Tuning和Prompt Engineering的思想:
- Prefix Tuning也额外增加了N个小模型,这些小模型外挂于同一套预训练模型上,不同小模型解决不同的下游任务。
- Prefix Tuning增加的这些小模型的作用类似Prompt(提示词),它们会在用户输入的文本前额外增加针对不同下游任务的提示词前缀Prefix。这些前缀不是自然语言,而是Transformer架构中向量形式的Token,这种Token叫做虚拟Token。
-
实验效果:在GPT-2的Table-To-Text和BART的Sumarization的测试效果:
- GPT-2的Table-To-Text:在完整数据集上训练时,Prefix Tuning和FFT在表格到文本的下游任务的性能相当。
- BART的Sumarization:在摘要方面,Prefix Tuning和FFT性能略有下降。
- Low Data Settting:在数据量少的数据集上,Prefix Tuning能够克服数据集样本不足、提炼数据特征困难的问题,表现出了泛化涌现能力。在上述两项任务中性能表现优于FFT。
3.Prefix Tuning
3.1.Problem Statement(问题陈述)
Prefix Tuning采用了严谨的数学描述来阐述待解决的问题,这也是算法工程中的算法建模环节,我们尽量通俗地理解这个问题模型,也感受一下算法工程师的思维模式。
-
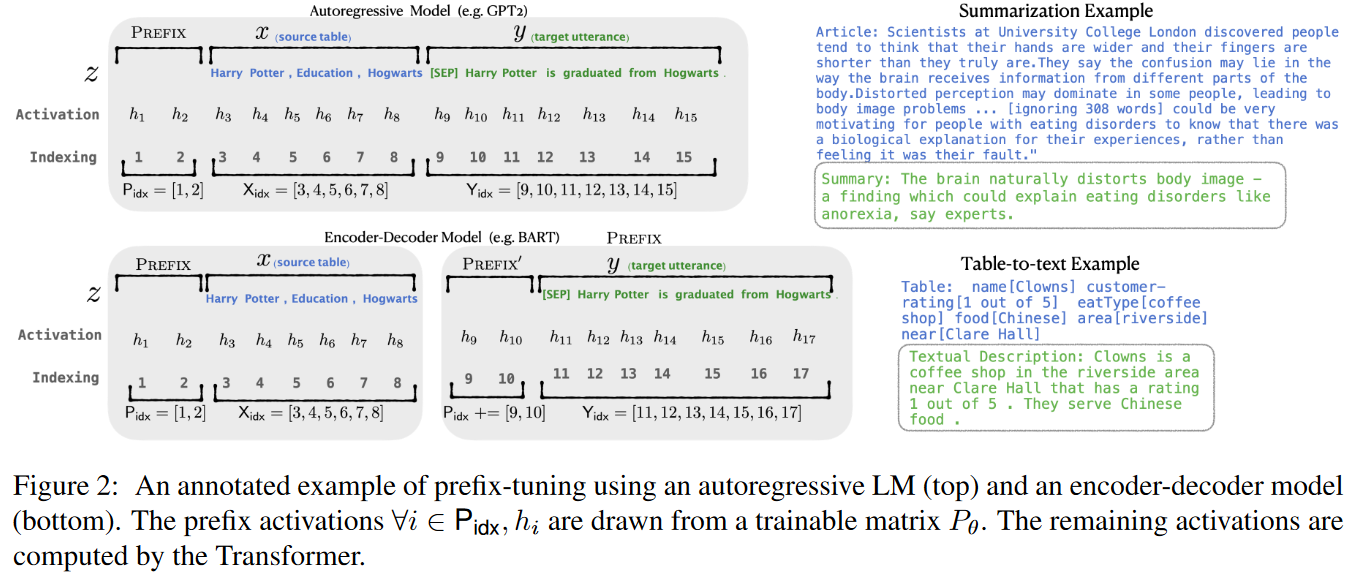
x和y:x是大语言模型的输入,y是大语言模型的输出。
- 如下图右侧上方所示,在摘要型下游任务中,人类输入的原始文本就是x,大语言模型输出的总结结果就是y。
- 如下图右侧下方所示,在表格转文本的下游任务中,人类输入的结构化的表格字符串是x,大语言模型输出的表格描述就是y。
-
自回归语言模型的问题子域(如下图左上所示):
- pφ(y | x):根据Transformer这种自回归模型的网络结构,其本质可抽象为pφ(y | x),φ为大语言模型的参数,p就是在**“人类输入字符串x的条件下,大语言模型输出y的概率分布”**。
- z = [x; y]:z被定义为x和y的序列,其中Xidx表示了x的索引,Yidx表示y的索引。
- hi:hi表示时间步i的激活(activation),hi又是由第i个时间步中的n层激活组成的序列(即hi= [hi(1);···;hi(n)]),其中hi(n)表示在Transformer架构中的第i个时间步的第n层的激活。
- hi=LMφ(zi, h<i):此数学公式表示——根据zi,以及h1~hi-1,计算当前的hi。展开解释一下就是,Transformer模型会根据第i个时间步的x、y,以及第1个时间步~第i-1个时间步计算的各时间步计算的各层激活向量,计算当前时间步下Transformer各层的激活。
- pφ(zi+1 | h≤i) = softmax(Wφhi(n)):最后一层的hi是Transformer训练后获得的概率分布,用来根据当前Token预测下一个Token。其中,Wφ是一个用于将hi(n)映射到词汇表上logits的预训练矩阵。
- 上述数学描述中,包含很多AI相关术语(如:自回归模型、时间步i的激活(activation)、各层激活向量、词汇表上logits等),可参见本技术专栏**《NLP底层原理》篇**的系列文章。
-
Encoder-Decoder模型的问题子域(如下图左下所示):
- 与自回归语言模型的问题子域大部分数学描述相同。
- 不同点在于基于Encoder-Decoder架构的结构特点,x和y被拆分开了。
-
Prefix Tuning的微调求解目标:
- maxφ log pφ(y | x) = Σi∈Yidx log pφ(zi | h<i):这个看着复杂的公式,就是在表达微调的最终目标就是在各个时间步的各时间步激活的条件下x和y序列的概率分布求和。说人话就是,微调后的模型能够根据x预测最大概率应该输出y。
3.2.Intuition(直觉)
论文在正式阐述Prefix Tuning的原理之前,描述了研究员的灵感来源:
- Based on intuition from prompting:提示词被证明是可以影响大语言模型输出,提示词的思想本质是——大语言模型像一个什么都知道的老人,人类的输入需要使用一定的提示技巧唤醒老人的记忆,从而帮助他输出正确的答案。
- z = [x; y]和hi=LMφ(zi, h<i):再看3.1问题陈述章节的这两个数学公式,提示词有两个作用:
- 作用1:提示词作为人类输入x的一部分,它起到了影响大语言模型关注x的哪些Token的作用。
- 作用2:在作用1的驱动下,影响了大语言模型各层的激活计算结果hi,进而影响了在x条件下应该接什么y的概率。
- but fail for most pretrained LMs:虽然提示词从理论上可以影响大语言模型的输出,但论文进一步阐述了提示词的局限性——做过提示词工程的小伙伴应该知道,仅仅通过自然语言形式的提示词,对大语言模型输出的效果提升很有限。
- continuous word embeddings:论文根据上述头脑实验,准备新增1个Prefix模型,在人类输入x词嵌入为向量后,在这个词嵌入向量前增加1个Prefix Token(前缀向量)(这种向量不同于离散向量,不会引发计算的困难)。为了保证Prefix Token有足够的提示性,论文在Transformer的所有层都增加了这种前缀向量。
3.3.Method/Parametrization of Pθ(原理)
论文至此,正式阐述了Prefix Tuning的实现方法:
- z=[x;y]到z=[prefix;x;y]:给自回归模型和Encoder-Decoder模型的z向量增加了前缀PREFIX向量。其中Pidx表示了前缀的索引。(如:)

- 基于前缀向量,hi的数学公式表示为各层的激活包含前缀向量的计算和大语言模型预测的概率分布。
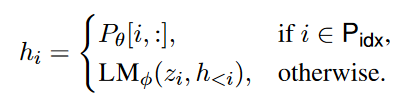
-
|Pidx| × dim(hi):Pθ是Prefix Tuning新增的小模型的参数,参数的维数必然是有限的,因为它的维数等于前缀向量个数乘以hi的维度。这也解释了为什么Prefix Tuning新增的小模型参数规模仅占预训练模型的0.1%。
-
Pθ[i, :] = MLPθ(P ′θ[i, :]):论文还发现直接微调Pθ会导致训练效果不好,于是采用了重参数化方法,引入了前馈神经网络MLPθ。
4.Experiments(实验结果)
4.1.实验结果
论文的实验结论:Prefix Tuning在Table-To-Text下游任务表现良好、在外推涌现方面表现良好,具体如下:
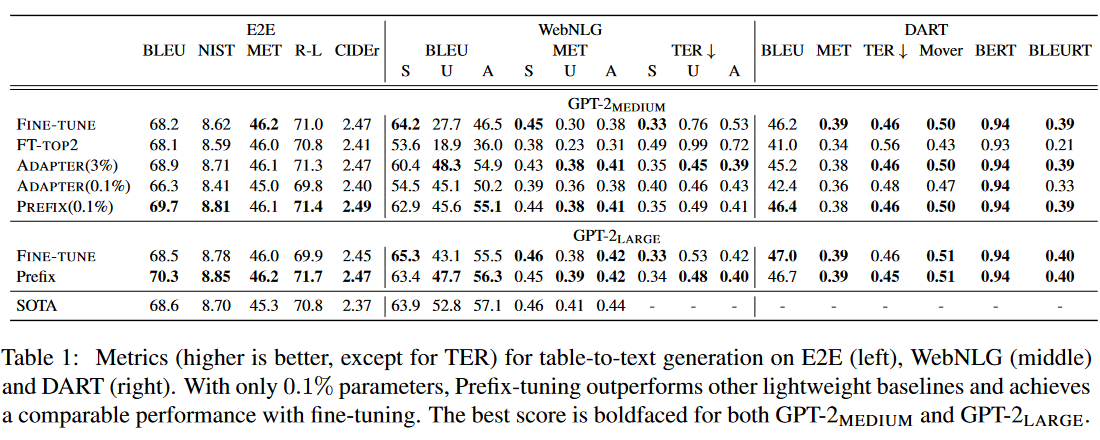
- Table-To-Text实验:用GPT2-Medium和GPT2-Large对比FFT和Prefix Tuning,Prefix Tuning都达到了SOTA水平。
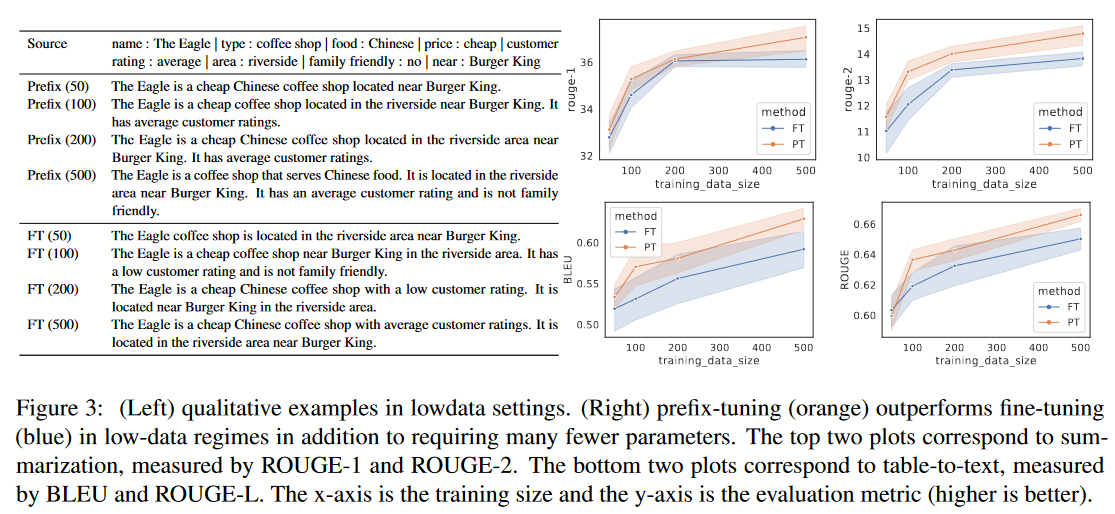
- Low-Data-Setting实验:在少数据测试中,Prefix Tuning的性能表现和训练稳定度优于FFT。
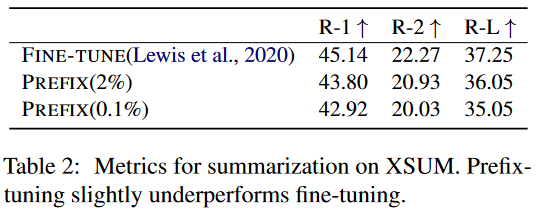
- Summarization实验:使用XSUM数据集,Prefix Tuning性能略低于FFT。
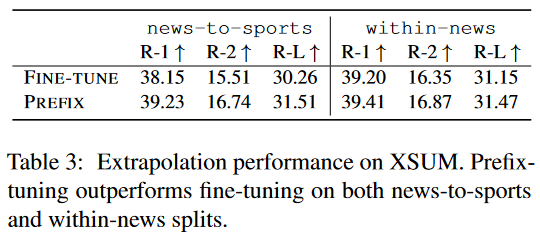
- Extrapolation实验:外推涌现实验中,使用XSUM数据集,Prefix Tuning效果优于FFT。
4.2.Intrinsic Evaluation(重要发现)
论文在前述实验结果下,有如下重要发现:
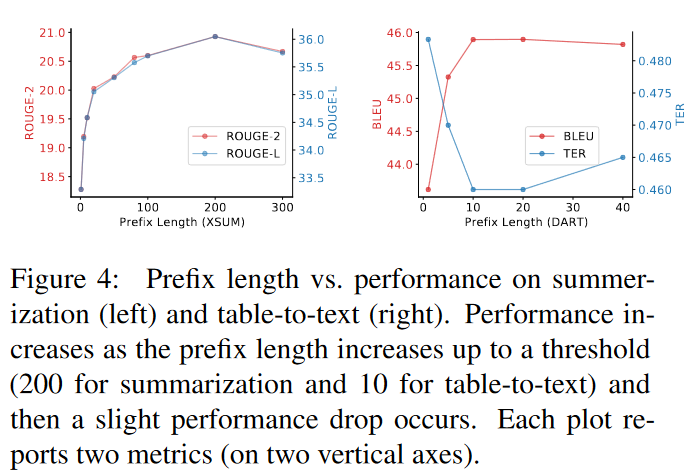
- Prefix长度的影响:
- 不同下游任务需要增加不同长度的前缀向量。
- Prefix长度越长,提示效果越好,但过犹不及——超过了一定的阈值,就会出现推理性能下降。
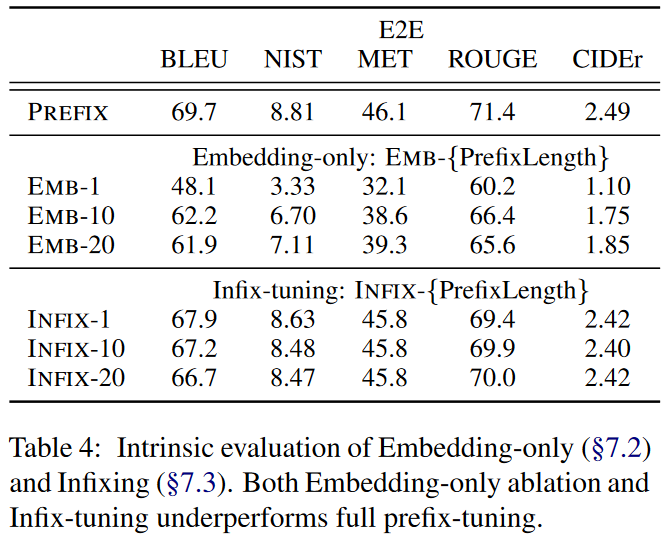
- 在哪些层做Prefix的影响:仅在词嵌入层做Prefix的效果远差于在Transformer各层做Prefx的效果。
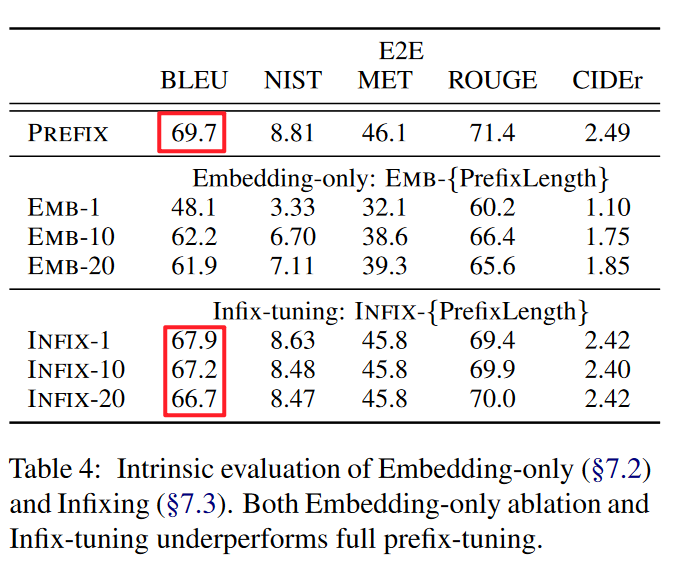
- Prefix和Infix的影响:用前缀法的性能效果优于中缀法。
- 研究员猜测,前缀法可能影响x和y,中缀法可能只影响y。
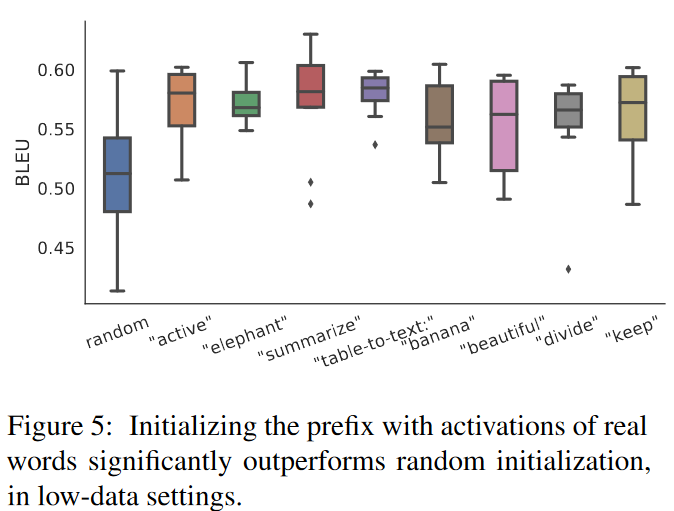
- Prefix的初始值选择的影响:随机初始化Prefix向量的效果远差于与下游任务相关联的Prefix向量初始化的效果。
- 这种现象可能由于用与下游任务不相关的提示词向量,会导致更长时间的前缀神经网络的收敛(甚至不收敛)。
5.总结
从上述论文解读中,我们收获了如下技术观点:
- Prefix Tuning的价值:追求一套预训练模型,搞定多个下游任务。
- Prefix Tuning的核心思想:增加一个新的具备提示能力的前缀向量小模型,微调小模型的少量参数,冻结预训练模型的海量参数。
- Prefix Tuning的工程实践经验:
- Prefix长度不宜过长或过短,需根据下游任务实验获得。
- 对Transformer做全层的Prefix效果更好。
- Prefix会影响x和y,效果优于Infix。
- Prefix的初始值需选择与下游任务相关的提示向量。
论文链接:https://arxiv.org/pdf/2101.00190.pdf

















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









