






平台简介
Free Qwen3 是一个革命性的分布式 AI 算力平台,基于来自全国各地的 50 台家用电脑的 3090、4080、4090 显卡分布式算力,为开发者提供完全免费、无限制的 Qwen3-30B-A3B 大语言模型 API 服务。
使用方式
- 访问 Free Qwen3 官网:Free Qwen3 - 免费分布式 AI 算力平台
- 点击"免费 API"按钮
- 获取 API Key 并开始使用
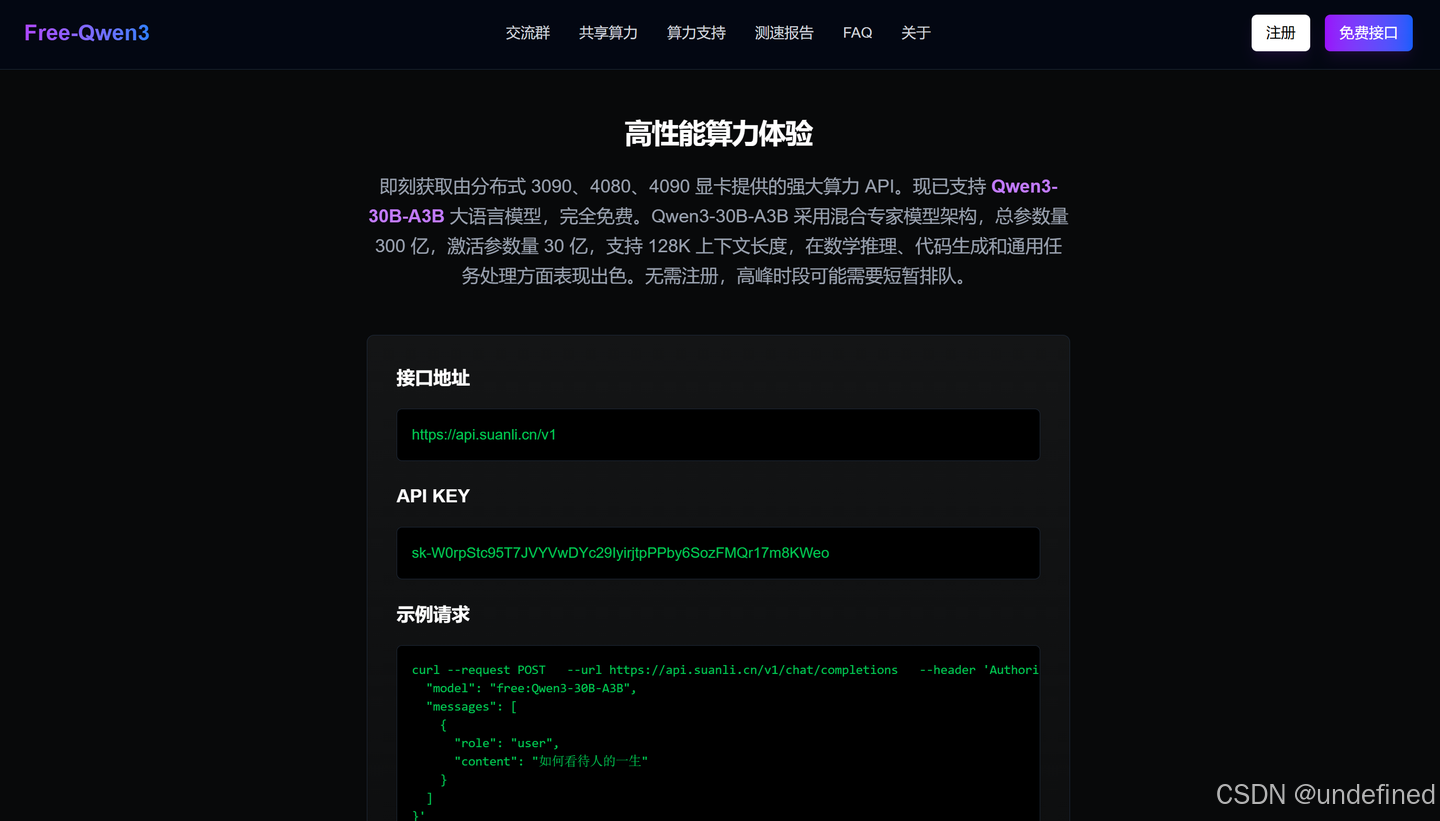
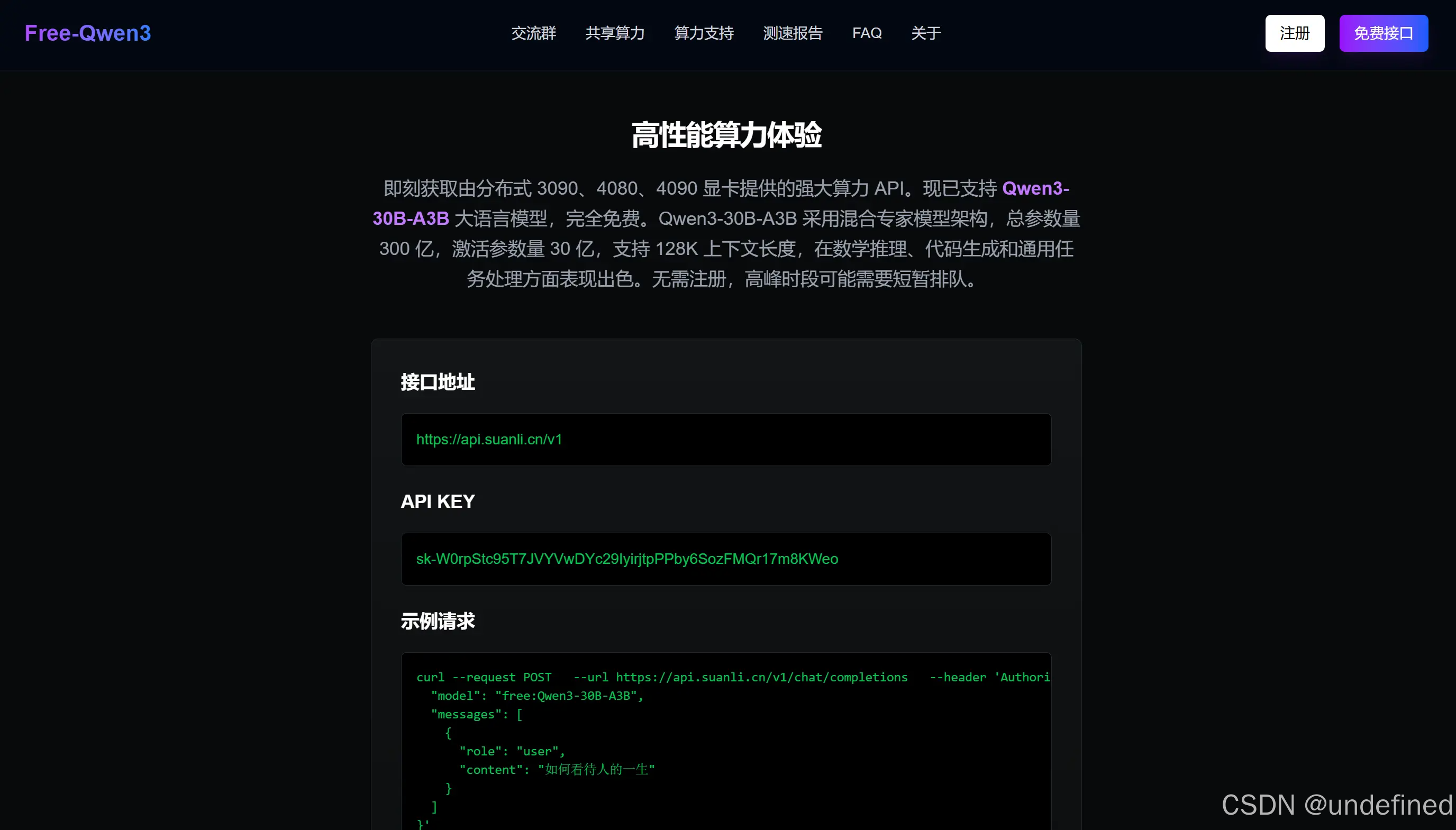
核心优势
1. 完全免费
- 无需注册
- 无需充值
- 无使用限制
- 立即获取 API Key 开始使用
2. 强大算力支持
- 基于分布式 3090、4080、4090 显卡
- 支持 Qwen3-30B-A3B 大语言模型
- 混合专家模型架构
- 总参数量 300 亿,激活参数量 30 亿
- 支持 128K 上下文长度
3. 卓越性能
- 在数学推理、代码生成和通用任务处理方面表现出色
- 性能媲美 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等明星模型
技术特点
Qwen3-30B-A3B 模型
- 采用混合专家模型架构
- 支持 119 种语言和方言
- 支持思考模式和非思考模式
- 可根据任务需求灵活切换
本地部署
算了么一键本地运行 Qwen3
- 无需网络连接,完全离线运行
- 零延迟响应,即时交互体验
- 数据安全,完全本地化处理
共享算力优势
- 闲置算力利用,让硬件创造价值
- 贡献社区,帮助更多人使用 AI
- 获得奖励,享受优先级和其他特权
关于我们
Free Qwen3 由共绩算力提供强大的分布式计算支持,核心团队来自清华大学、北京大学以及 Intel、字节跳动等知名企业。团队在分布式计算领域深耕多年,曾获 2024 年中国国际大学生创新大赛亚军,并获得奇绩创坛、水木创投等机构投资。
未来展望
随着模型技术进步,大模型正朝着"小型化"方向发展,在更小算力下释放更强能力。Free Qwen3 将持续跟进最新的开源模型,为用户提供更多选择,同时探索让用户能够更便捷地部署和共享自己的模型。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









