







时间:2016/11/15
作者相关:Vikash Kumar: Senior Research Scientist in Robotics and Embodied AI (vikashplus.github.io)
摘要
- 基于学习的方法,用于对灵巧五指手进行非抓握操作的反馈控制
- 学习得到能够从预定义的初始状态开始执行任务的本地控制器
- 控制器是利用直接从传感器数据中学习到的局部线性时变模型locally-linear time-varying models 的轨迹优化 trajectory optimization 来构建的
- 对于有一些初始条件的初始状态,可以在模拟和物理平台上稳健地执行任务
- 还用两种插值 interpolation 方法来对更多的初始条件进行泛化:深度学习和最近邻 nearest neighbors
- 发现最近邻可以获得更高的性能,最近邻方法基于通过运动捕捉感知的与初始对象状态的接近度,在时变的局部控制器之间切换
- 神经网络可以只使用触觉和本体感觉反馈,而不使用关于对象的视觉反馈,并学习时不变策略
- 我们的工作表明:
- 基于局部轨迹的控制器可以从少量的训练数据中构建复杂的非抓握操作任务
- 这些控制器的集合可以内插以形成更多的全局控制器
关键词
Reinforcement Learning, Dexterous Manipulation, Trajectory Optimization
Introduction
- 不依赖于手动设计的控制器,通过优化高级成本函数,以及通过构建人类提供的专家演示来自动合成控制器
- 学习每个控制器所需的少量数据(在物理硬件上大约60次试验)
- 使用ADROIT平台,带有高性能气动执行器的shadowwhand骨架
- 具有100维连续状态空间;40维连续控制空间
- 我们的方法可以分类为基于模型的强化学习(RL)或自适应最优控制
- 无模型和有模型的强化学习
- 自适应控制主要侧重于学习具有预定义结构的模型的参数,本质上是将系统识别与控制交织在一起
- 我们的方法介于两者之间,依赖于一个模型,但该模型没有任何信息预定义的结构,是从数据中学习的时变线性模型,使用通用先验进行正则化
- 将先前研究的14维状态空间拓展到这里的100维状态空间
- 学习的操作技巧最初表示为时变线性高斯控制器
- 通过遥操作演示来初始化控制器来学习更复杂的操作技能
- 通过两种方式进行泛化来适应任务的不同初始条件
Related Work
- 机器人强化学习与灵巧手控制
- 实验表明,我们的方法可以学习复杂精确抓取任务的策略,并可以推广到目标物体初始位置的变化
- 通过数据手套远程操作,将从经验中学习与从人类演示中模仿学习相结合,克服了这一挑战
- 通过演示初始化控制器是机器人强化学习中广泛使用的技术,简单的成本可能导致较差的局部最优,我们根据示例演示来定义成本
System
Hardware Platform
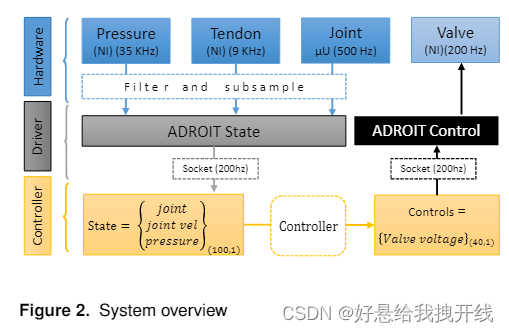
ADROIT平台,24自由度的手安装在固定的底座上,使系统仅适用于基于手指和基于手腕的操纵策略
抓握对象:装满咖啡豆的长管,每一端都装有PhaseSpace有源红外标记用于估计对象位置和速度(线速度和角速度),它们也作为状态变量提供
所有的传感器都具有相对较低的噪声,因此在将传感器数据发送到控制器之前,我们用最少的滤波
Simulation Platform
使用我们开发的MuJoCo模拟器
Reinforcement Learning with Local Linear Models
用于控制气动五指手的强化学习算法推导遵循先前的工作(Levine and Abbeel 2014)
- 目的是学习形式为
的时变线性高斯控制器
- 其中xt和ut是时间步长t的状态和动作
- 动作对应于气动阀的输入电压
- 算法目的:最小化在轨迹
上的期望
- 其中
是总成本
- the expectation is under
- 其中
是 the dynamics distribution
- 其中
- 其中
Optimizing Linear-Gaussian Controllers
- 时变线性-高斯控制器结构简单,即使在未知动力学的情况下也能很好地进行优化
 ,
,- 在机器人上运行当前控制器p(ut|xt)以收集N个样本,用这些样本拟合形式为
的时变线性高斯动力学
- 计算了成本函数在每个样本周围的二阶展开式并平均在一起,以获得局部近似成本函数
- 形如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2943
2943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









