







目录
参考文献:
@inproceedings{yang2022psnerf, title={PS-NeRF: Neural Inverse Rendering for Multi-view Photometric Stereo}, author={Yang, Wenqi and Chen, Guanying and Chen, Chaofeng and Chen, Zhenfang and Wong, Kwan-Yee K.}, booktitle={European Conference on Computer Vision (ECCV)}, year={2022} }
摘要
传统的多视角光度测量立体(MVPS)方法通常由多个不相连的阶段组成,会产生明显的累积误差。本文提出了一种基于隐式表示的MVPS神经逆渲染方法。给定由多个未知方向光照明的非朗伯物体的多视图图像,我们的方法联合估计几何、材料和光。我们的方法首先利用多光图像来估算视角表面法线图,然后利用这些法线图对神经辐射场得出的法线进行正则化。然后,基于阴影感知的可微渲染层联合优化表面法线、空间变化的brdf和灯光。优化后,重建的对象可以用于新视图渲染、重光照和材料编辑。在合成数据集和真实数据集上的实验表明,我们的方法比现有的MVPS和神经渲染方法实现了更精确的形状重建。
1. 文献主要内容
1.1 研究背景及重要解决的问题
多视图立体(MVS)是一种从不同视点捕获的一组图像中自动重建三维场景的技术。由于MVS方法依赖于不同图像之间的特征匹配,它们通常假设场景是由有纹理的朗伯表面组成的,而它们的重建往往缺乏细节。光度立体(PS)可以从不同光方向下捕获的单视图图像中恢复场景的每像素表面法线。通过利用阴影信息,PS方法可以恢复非朗伯对象和无纹理对象的精细表面细节。然而,单视图PS方法不能恢复一个完整的3D形状。多视图光度立体(MVPS)方法结合了上述两种方法的优点,来恢复非朗伯对象和无纹理对象的高质量的完整三维形状。但是传统的MVPS方法是通常由多个不相交的阶段组成,导致明显的累积误差。
神经辐射场方法最近被引入来解决多视图重建和新视图合成的问题。这些方法适用于在固定光照下捕获的多视图图像,并显示令人惊艳的重建效果。Kaya等人首先将光度立体法融入到神经辐射场中,具体做法是将基于观测图的PS方法估计的表面法线来调节神经辐射场(NeRF)。虽然该方法取得了不错的渲染结果,但这种方法有4个基本的局限性:
- 它需要校准的灯光作为输入来估计每个视图的法线图。
- 它将表面法线作为NeRF的输入,使得新视图渲染很困难。
- 它不能恢复表面的brdf,使其不适合重光照。
- PS网络和NeRF是脱节的,来自PS网络的法线估计误差会传播到NeRF,无法消除。
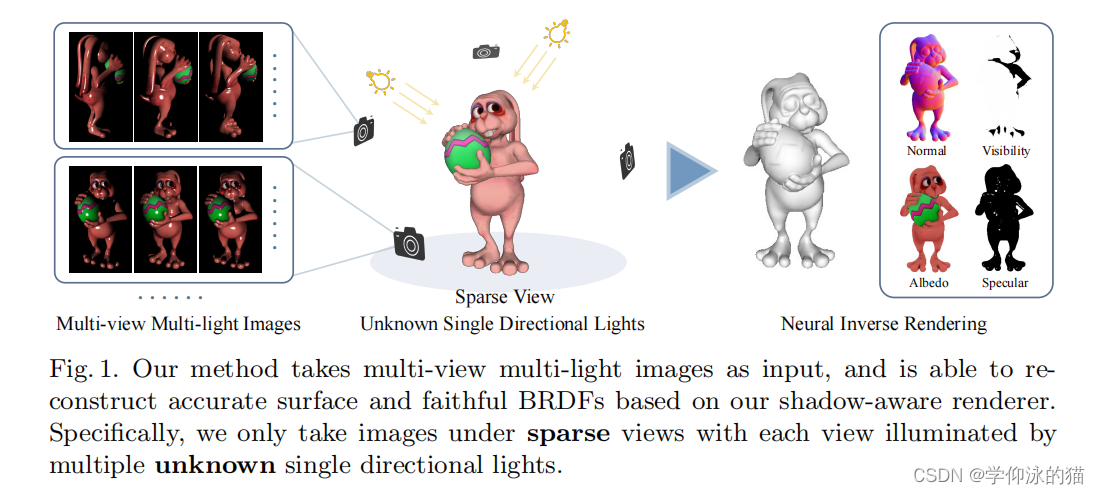
为解决上述问题,杨等人提出了一种多视图光度立体的神经逆渲染方法(见图1)。该方法不需要校准过的灯光。首先估计每个视图的法线图来约束NeRF中的密度梯度。曲面法线、基于阴影感知的可微渲染层的brdf和灯光进行联合优化。通过利用多视点和多光图像,获得了更精确的形状重建结果。此外,由于该显式地建模brdf和灯光,它允许新视图渲染、重光照和材料编辑。
PS-NeRF的主要贡献如下:
- 该方法基于阴影感知可微渲染层联合优化了形状、brdf和灯光。
- 用多光图像估计的法线对辐射场得到的表面法线进行正则化,这显著改善了表面重建,特别是对于稀疏输入视图(例如,5个视图)
- 在MVPS中取得了最先进的结果,并证明了适当地结合多光信息可以产生更精确的形状重建
1.2 原理(或者方法,或者模型)描述
1.2.1 总体概述
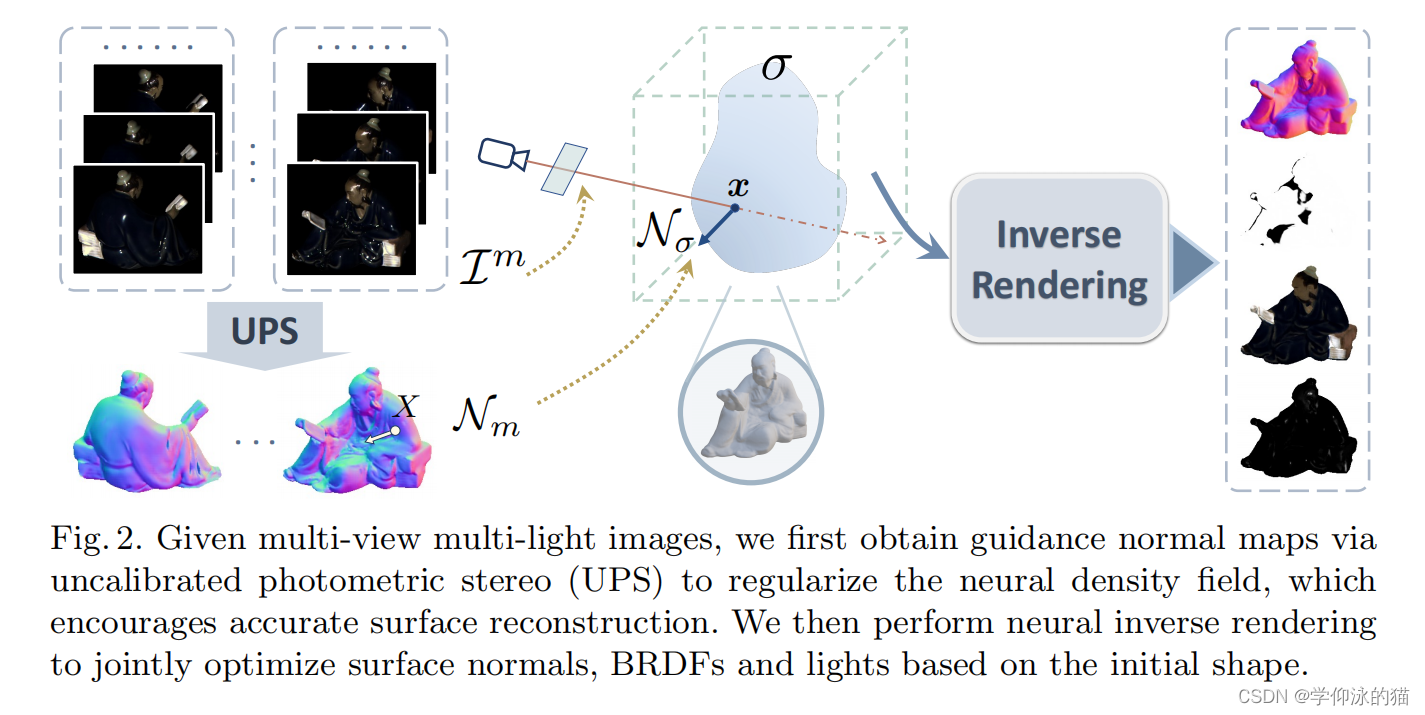
作者的目标是从给定的稀疏多视图多光照图像中同时重建物体的形状、材料和光线。每个视图对应的灯的数量可能会有所不同。方法包含两个阶段
- 第一阶段:为每个视图估计一个引导法线图,用于监督从密度场推导出的法线。这种直接的法线监督有望在密度场上提供一个强的正则化,从而产生一个精确的表面。
- 第二阶段:基于学习到的密度场作为形状先验,使用阴影感知渲染层共同优化表面法线、材质和灯光
1.2.2 第一阶段:初始形状建模
在第一阶段,通过表面法线正则化来优化神经辐射场,以表示物体的形状。
神经辐射场:没有直接使用原始的NeRF,因为原始NeRF的密度场通常是非常嘈杂的。采用了单神经元网络来代替原始NeRF, 单神经元通过逐渐缩小绘制射线的采样范围来提高NeRF的表面质量,从而使表面更平滑。通常,通过最小化渲染图像和输入图像之间的重建误差来拟合一个场景

表面法线估计:采用了未校准光度立体方法(SDPS-Net),从单视图多光图像估计一个良好的正法线图。利用这个估计的法线图通过构建损失函数来约束密度场。
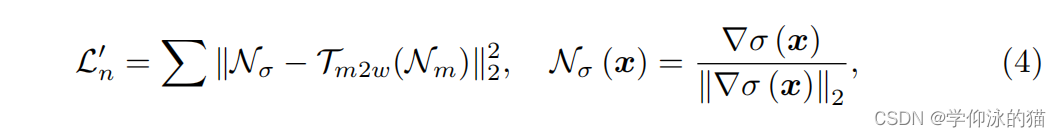
其中,是由基于预期深度位置的密度场
的梯度推导出的表面法线,
是将以视图中心法线从相机坐标系转换为世界坐标系的变换。我们还包括了具有
法线光滑正则化
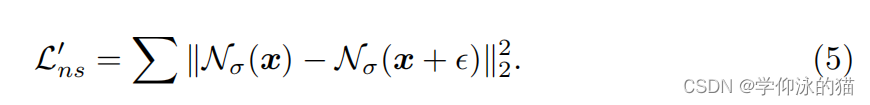
第一阶段的总体损失函数如下:

1.2.3 第二阶段:使用反向渲染的联合优化
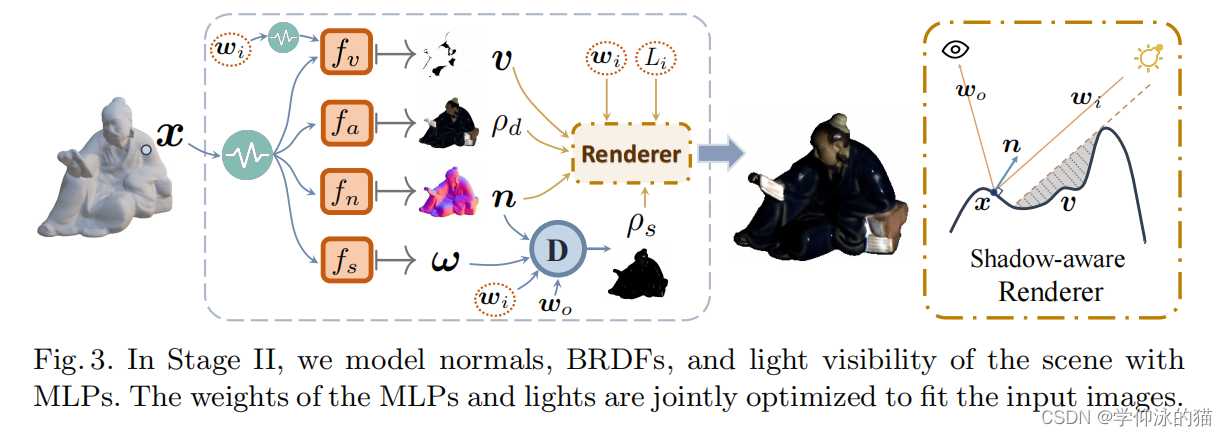
通过第一阶段得到的初始形状,我们能够联合优化表面法线、空间变化的BRDFs和基于阴影感知渲染层的灯光(见图3)具体来说,首先通过类似于[40]的求根法[39,35]从密度场中提取表面。然后,用mlp对场景的表面法线、brdf和光可见性进行建模。然后联合优化mlp和灯光的权重,以适应输入的多视图和多光图像。在下面的小节中,我们将详细描述渲染层和每个组件的公式。
渲染方程。非朗伯曲面点x的渲染方程可以写成[20]:
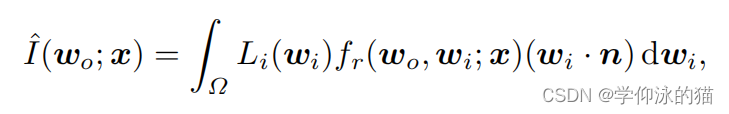
其中,和
分别为入射光方向和观测方向,表示位置
处的一般BRDF。
是沿
的光强度和是
在上半球
上的整体辐射。
通过假设一个定向光并考虑光的可见性,渲染方程可以改写为:
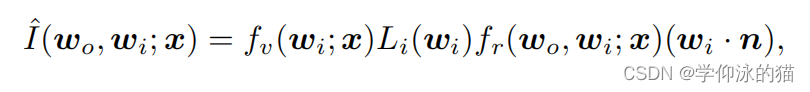
其中表示沿
在
处的光的可见性,并在渲染图像中建模投射阴影。
形状建模。在第一阶段,优化了一个具有表面法线正则化的辐射场,以产生一个初始密度场。注意,用于正则化的法线是由PS方法估计的,该方法不可避免地包含估计误差。因此,推导出的法线在某些区域可能不准确。为了细化法线,我们使用一个MLP
来模拟曲面法线的分布。该MLP将通过图像拟合损失进行优化。为了鼓励改进的法线不要太偏离导出的法线,我们使用导出的法线通过最小化来正则化
的输出:
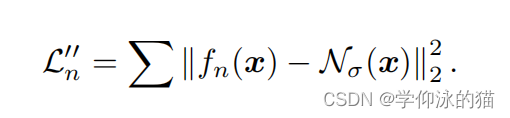
可见性建模。给定密度场σ、表面点x和光方向wi,可以通过应用体积渲染来计算沿着从x到光源的光线的累积密度来计算光可见性。
由于采用ray-marching来计算每个点和每个查询光方向的可见性,因此计算环境地图照明的光可见性将是非常耗时的。此外,计算出的可见性也可能会有噪声。因此,我们使用另一个MLP 来模拟光可见性的分布,该模型通过最小化计算出的可见性进行正则化
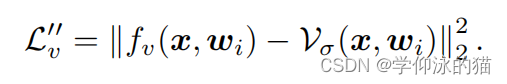
材料建模。假设BRDF模型可以分解为漫反射和镜面反射,即: 。对于漫射颜色,我们使用MLP
来建模曲面点
的漫反射。
对于镜面分量,可以采用反射率模型(如微切面)来模拟镜面反射率并估计其参数(如粗糙度)。然而,我们发现很难通过直接估计粗糙度参数来模拟真实世界物体的镜面效应。相反,我们建议拟合镜面反射率与一个加权组合的镜面基如下
我们假设各向同性材料,并根据[43]将输入简化为半向量h和法线n,并定义一组球体高斯(SG)基为
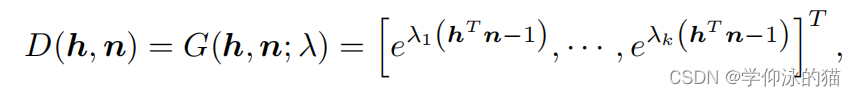
其中, 表示镜面锐度。我们引入了一个MLP
来模拟空间变化的SG权值,然后镜面反射率可以恢复为:
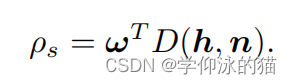
为了鼓励一个平滑的反照率和镜面反射率分布,我们分别对 和
施加平滑损失
和
。
光照建模。每幅图像都由一个方向的光照明,它由一个3矢量的光方向和一个标量的光强度参数化。我们将光的方向和强度设置为可学习的参数,并通过UPS方法估计的光进行初始化。经过联合优化后,将对光参数进行细化。
联合优化。基于我们的场景表示,我们可以使用可微渲染方程重新渲染输入的图像。给定多视点和多光图像,我们对法线、可见性和BRDF MLPs以及光参数进行优化,以最小化图像重建损失
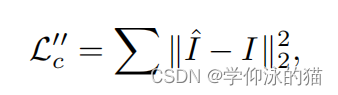
用于我们的神经逆渲染阶段的整体损失函数是
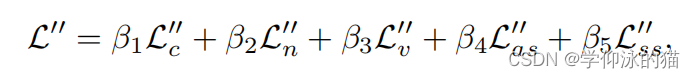
1.3 文献实验结果分析
1.3.1 评价指标
- 表面法线:平均角度误差(MAE)
- 三维面片: 倒角距离
- 重建图像:峰值信噪比(PSNR)、结构相似性指数(SSIM )和感知图像补丁相似性指标(LPIPS)
1.3.2 数据集
真实数据。DiLiGenT-MV基准数据集。它由5个形状和材料的物体组成。每个对象都包含从20个视图中捕获的图像。对于每个视图,96张图像在不同的光方向和强度下被捕获。提供了真实的面片。在实验中,作者以等量的间隔采样5个测试视图,并取剩下的15个视图进行训练。请注意,作者的方法在评估中假设了未知的光方向和光强度。
合成数据集。作者使用Mitsuba渲染了一个包含两个对象(即兔子,阿马迪洛)的合成数据集。在两组灯光下渲染对象,一组是定向灯光,表示为SynthPS数据集,另一组是环境光,表示为SynthEnv数据集。在上半球随机抽取20个摄像机视图,其中15个视图用于训练,5个视图用于测试。对每个视图使用与DiLiGenT-MV基准分布的定向光。对于合成数据集,为每个光源设置相同的光强。
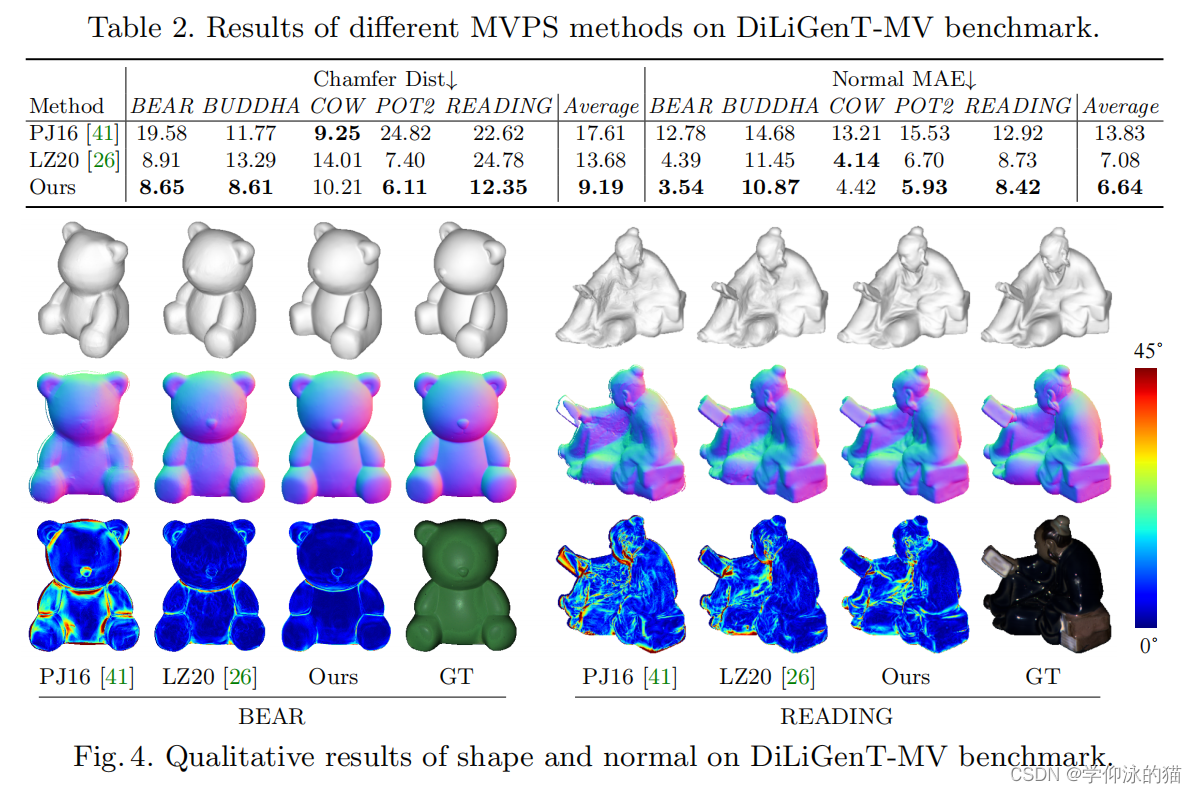
1.3.3 与MVPS方法的比较
在DiLiGenTMV基准数据集上进行了比较,其中所有20个视图都用于优化。需要注意的是,作者的方法没有使用校准的灯光。
结果表明:
- 该方法在形状重建方面比现有的方法要好得多。
- 该方法在重建光滑和粗糙表面方面具有优越性。
1.3.4 与基于神经渲染的方法的比较
作者将其方法与现有的神经渲染方法进行了比较,包括NeRF [36]、KB22 [23]、UNISURF[40]、PhySG [61]、NeRFactor [61]和NeRD [5]。其中,前三种方法只能支持新视图渲染,不能进行场景分解。对于KB22 [23],将PS法估计的法线作为NeRF的输入来重新实现它。对于其他方法,使用它们发布的代码进行实验。
从表3和表4可以看出,作者的方法获得了最好的渲染和法线估计结果,并且在形状重建方面明显优于现有的最佳方法UNISURF[40]。作者将视图渲染的成功归因于形状、材料和光组件的分解,以及阴影感知设计。多光图像提供了丰富的与形状和材料相关的高频信息,确保了在不同光照下的高渲染质量。
表4中的结果报告了在PS和环境照明中所有基线方法的相似几何重建性能。其他方法未能在两种光照条件下重建精确的表面。这可能是由于稀疏的输入视图,以及形状和材料联合估计的模糊性,特别是对于存在于PS和Env照明的非纹理区域。相反,作者的方法成功地估计了更精确的几何形状。还在图5中显示了定性的比较。作者的方法在重渲染质量和重建表面法线上都取得了最好的性能,特别是在眼睛区域等细节方面


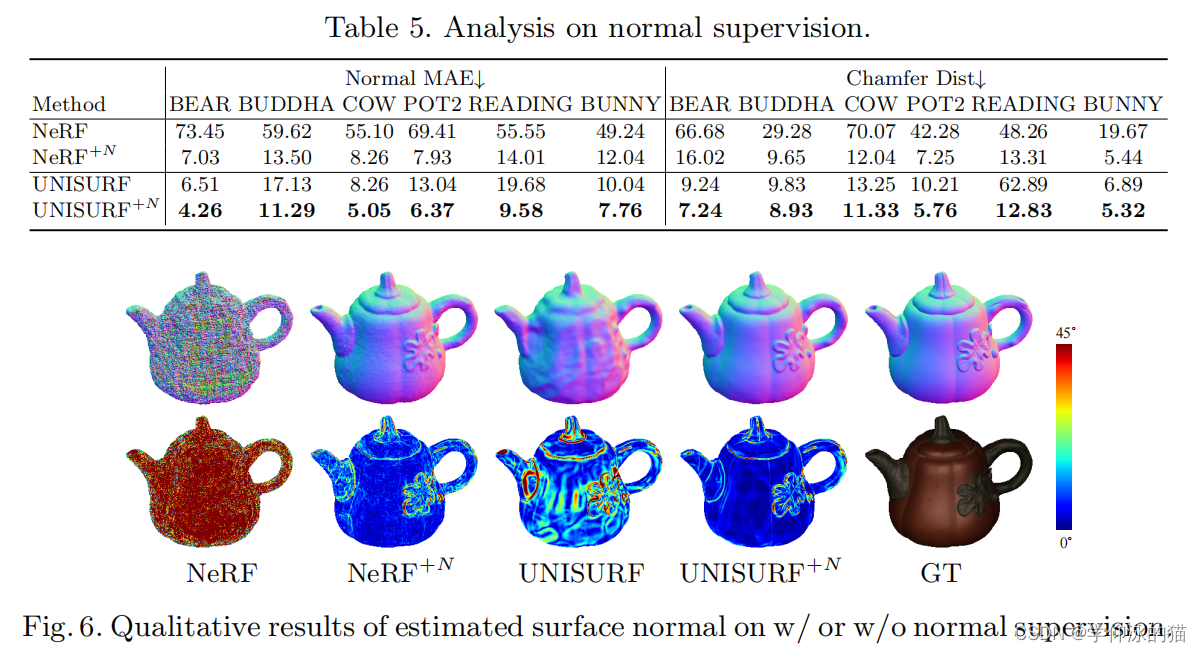
1.3.5 方法分析
法线正则化的有效性。作者利用多光图像来推断表面法线,以约束辐射场中的表面几何形状。它消除了密度估计中的模糊性,特别是对凹形对象。作者展示了其方法在DiLiGenT-MV基准和合成数据集的所有对象上添加法线约束(即UNISURF作为第一阶段的主干)和NeRF 的之前和之后的重建结果。
如表 5 和图 6 所示,引入的法线正则化大大提高了所有对象的形状精度和表面细节恢复率。
例如,在 READING 物体上,NeRF 将法线 MAE 从 55.55 降至 14.01,UNISURF 从 19.68 降至 9.58,验证了法线正则化的有效性。
联合优化的有效性。利用多光照图像中丰富的阴影信息和阴影感知渲染器,我们可以通过联合优化法线、BRDF 和光照来重建表面。表 6 显示,联合优化能持续提高表面法线精度。此外,如表 7 所示,光照方向也通过联合优化得到了改善。
作者还通除去光方向优化和可见度建模研究了第二阶段的设计。为了对自己的方法进行消融研究,作者计算了每个光源的重新渲染图像质量指标,而不是光平均图像。表 8 显示,固定初始化光向或取消可见性建模都会降低渲染质量和形状重建精度。


训练视图数量的影响。由于作者的方法可以充分利用多光图像来解决普通 RGB 图像中的深度模糊问题,因此它能够仅从稀疏视图中重建高质量的形状。为了证明这一点,作者将其方法与 UNISURF 和 PhySG 进行了比较,使用 5、15 和 30 个训练视图进行曲面重建。请注意,基线方法是在 SynthEnv 数据集上训练的,因为它们假设环境光照是固定的。表 9 和图 8 显示了使用不同视图数的重建结果。即使只给出 5 个视图,作者的方法也能获得令人满意的重建结果,而其他方法在视图数量不足时都会失败。

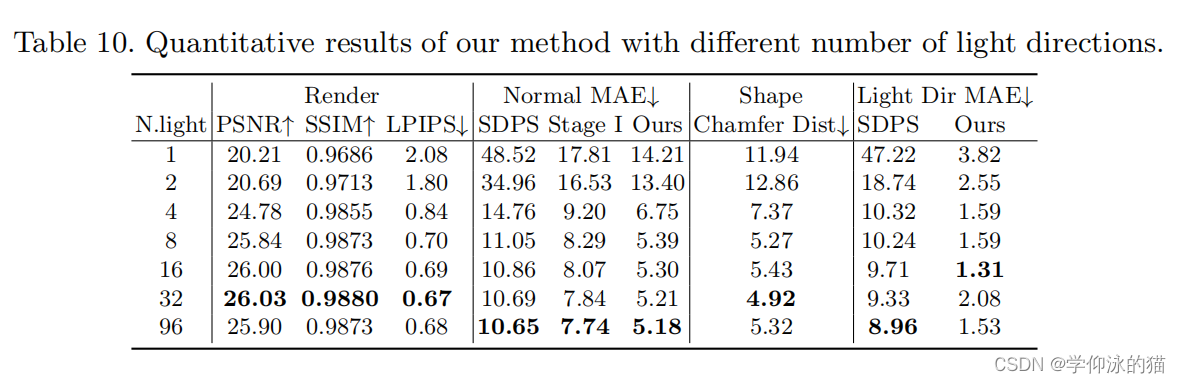
光方向数量的影响。之前的 PS 方法大多需要校准过的灯光,而作者的方法则假定灯光未经校准,并且可以处理任意数量的灯光。还通过实验来探索在使用 15 个视图的情况下,需要多少灯光数才能重建高质量的形状。与消融研究类似,作者估算了重新渲染图像的每个光点误差。对于光线方向误差,取其所用光线的平均值。表 10 显示,增加灯光数量通常会提高重建精度。在不同的灯光数量下,作者的完整方法始终优于 SDPS-Net 和 Stage I。在每个视图只有 4 幅定向光照射的图像的情况下,作者的方法取得了与使用 96 幅图像相当的结果(例如,MAE 为 6.75,而 SDPS-Net 为 5.18),这表明作者的方法对光照方向的数量具有很强的鲁棒性。
2. 实验结果及代码
2.1 预处理阶段
首先,通过使用SDPS-Net网络的预训练参数来估计20个视图的法线、光照方向以及光照强度。以“熊”为例进行展示。




然后,将每个视图的96个不同灯光图像取平均值,作为下一阶段的输入。




2.1 第一阶段
2.2 第二阶段
3. 方法评述
虽然作者的方法已成功应用于恢复复杂真实世界物体的高质量形状重建,但仍有以下局限性。
- 首先,在渲染方程中忽略了表面的相互反射。
- 其次,假定物体是实体来定位其表面位置,因此无法处理非实体物体(如雾)。
- 最后,与大多数神经渲染方法类似,假设摄像机的姿势是给定的。

















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









