







 文章详细比较了COCO评估工具和YOLOv5在计算平均精度(AP)时的不同方法。COCO使用np.searchsorted()进行近似插值,而YOLOv5则采用np.interp()进行精确插值并积分计算AP。此外,COCO直接取均值,YOLOv5则通过积分求解。这两种方法导致了计算结果的轻微差异。
文章详细比较了COCO评估工具和YOLOv5在计算平均精度(AP)时的不同方法。COCO使用np.searchsorted()进行近似插值,而YOLOv5则采用np.interp()进行精确插值并积分计算AP。此外,COCO直接取均值,YOLOv5则通过积分求解。这两种方法导致了计算结果的轻微差异。
在测试检测benchmark时发现使用coco和yolov5计算出的map结果不一致, yolov5的指标要略高一点, 好奇他们都是如何计算的, 通过阅读源码, 发现了一些端倪, 如有纰漏, 还望指出.
ap概念及计算方式
先说ap(average precision), 翻译过来为平均精度, 顾名思义, 就是精度的平均值. 通常来讲, 一个算法任务在数据集上的测试输出的结果是固定的(TP, FP是固定的), 也就是说, 精度值就一个, 那么何来平均精度一说呢?
事实上, 当正负样本差别较大时, 使用单一指标, 如精度(查准率), 还是召回率(查全率), 都无法评价模型的好坏(想象一下正样本99, 负样本1, 模型将所有目标都预测为正例, 此时tp=99, fp=1, p=0.99, r=1能说明模型很好吗? ), 于是需要一个综合指标来衡量模型好坏, ap就是这个综合指标, 计算方式也很简单, 就是计算平均精度, 问题是, 如何构造多个精度呢?
假设某单一目标检测任务(只有1类)在数据集(假设只有3张图片, 每个图片一个目标)有三个预测结果(每个图片一个, 事实上,计算map时跟几张图片没关系), 每一个预测结果 都有置信度, 将所有结果按照置信度从大到小排列:
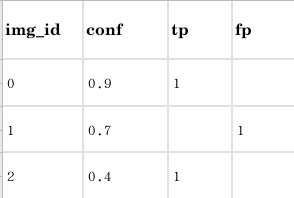
对于整个数据集:
置信度为0.9时, tp = 1, fp=0;
置信度为0.7时, tp = 1, fp=1;
置信度为0.4时, tp = 2, fp=1
由以上结果, 可以得到下表:
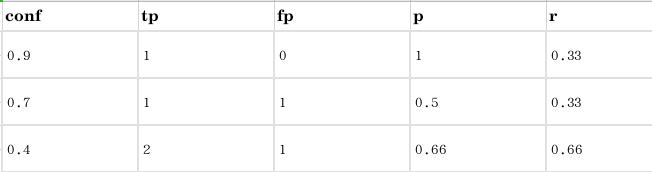
于是, 我们便得到了一系列的precision.
但是有几个细节需要我们注意:
- 问: 我们如何确定检测结果是tp还是fp?
答: 靠iou, 预测框和gt框iou>iou_th为tp, 否则为fp, ap50就是在iou_th=0.5的条件下计算得到的map. - 问: ap和map什么关系?
答: 通常来讲, ap是某一类的平均精度, map是所有类别的平均精度的平均, 但在coco中, 就没map这个说法, coco中的ap就是map
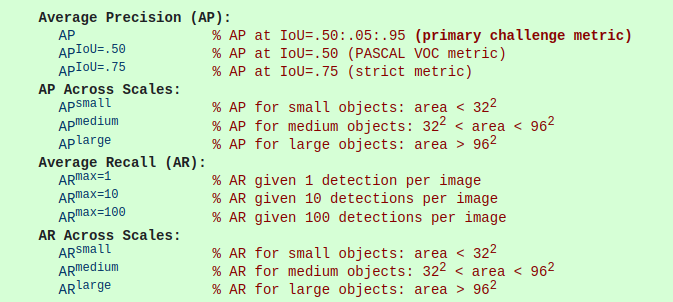
值得注意的是, 在coco意义下,
ap(map)是iou_th从0.5取到0.95共10个iou level计算得到的ap的平均值(由每一类ap得到最终ap, 一共需要取两次均值, 一次是所有的iou level, 一次是所有的class)
ap50是iou_th取0.5计算得到的map - 问: 得到了p和r, 接下来ap如何计算呢? 是不是将p取平均就行了?
答: 这个问题很关键, coco, yolov5的区别就在这
coco和yolov5的差别
在得到p, r列表后, 可以画出p, r图像(画图只是为了方便理解, 实际计算时, 只要得到p, r列表就行了)
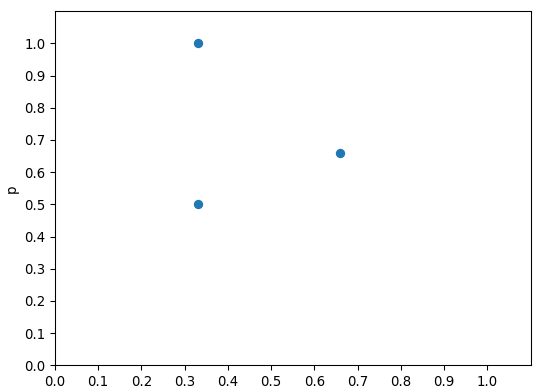
通常, 在得到以上图像后, 需要将x轴(即r)分为101份(0~1, 0.01)进行插值来计算最终的ap, coco和yolov5的差别体现在得到p, r 列表后, 如何插值以及如何计算ap上.
- 先看下coco(
pycocotools.cocoeval.COCOeval):
coco的插值方法:
# cocoeval.py, line 402
inds = np.searchsorted(rc, p.recThrs, side='left')
其中, recThrs就是recall的101个点, 熟悉np.searchsorted()的小伙伴应该发现了, 其实coco在计算时并没有真的进行插值, 只是按照101个recall的位置, 从p列表中取对应位置的p而已, 对应图像是这样:
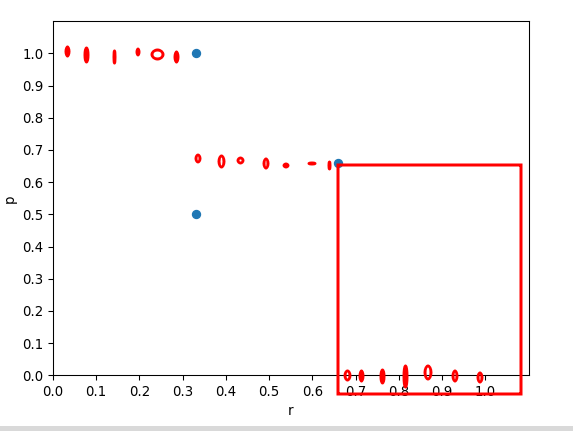
细心的小伙伴会发现np.searchsorted()得到的索引可能超过p的长度, 那超过r最大值的点(右侧红框部分)怎么取呢?答案是直接置为0, 也就是说"插值坐标点"取到r能取到的最大索引后就结束了, 代码对应于这部分:
# cocoeval.py, line 402~408
try:
for ri, pi in enumerate(inds):
q[ri] = pr[pi]
ss[ri] = dtScoresSorted[pi]
except:
pass
q初始化的时候都是0, 当pi超过pr的索引时会发生错误, 于是超过索引的p都是0.
再来看最终如何计算ap值, coco直接简单粗暴, 取均值:
# cocoeval.py, line 455
mean_s = np.mean(s[s>-1])
- 再看yolov5
首先, yolov5是老老实实对p列表进行了101个点的插值, 插值完大概是这样:
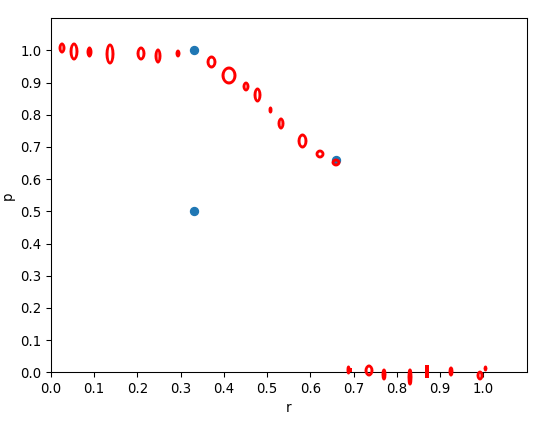
对应代码:
# Append sentinel values to beginning and end
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([1.0], precision, [0.0]))
# Compute the precision envelope
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# Integrate area under curve
method = 'interp' # methods: 'continuous', 'interp'
if method == 'interp':
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
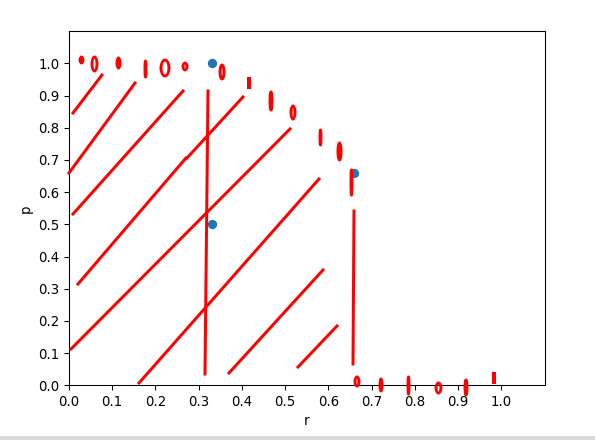
从代码可以看出, 首先在p, r列表左右两侧各查了0,1两个值, 方便后面查值, 之后通过np.interp()插101个点, 最后通过
np.trapz 积分得到最终的ap, 大概就是这样:
结论
coco和yolov5在计算map(coco叫ap)的不同之处有两点:
- coco插值用的是np.searchsorted(), yolov5用的是np.interp();
- coco用平均得到ap, yolov5积分得到ap;

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









