







VisionLLM v2: An End-to-End Generalist Multimodal Large Language Model for Hundreds of Vision-Language Tasks
Paper: https://arxiv.org/abs/2406.08394
Code: https://github.com/OpenGVLab/VisionLLM
目录
一句话总结
VisionLLM v2提出了一种新的信息传输机制,称为“super link”,能够作为媒介将 MLLM 与特定下游任务decoder连接起来,使VisionLLM v2获得了端到端的多个不同下游任务的处理能力。
Super Link不仅能够对MLLM和多个下游任务解码器之间的任务信息和梯度反馈进行灵活的传输,而且有效地解决了同一个模型的多任务场景下的训练冲突。
Motivation
当前的 MLLM 输出多以文本形式,这极大地限制了它们表示结构化或视觉信息的能力,并且不是端到端的方式,来自其他任务工具的梯度不能反传给MLLM,无法进行联合训练。
三种不同的MLLM与下游任务的信息传输方式:
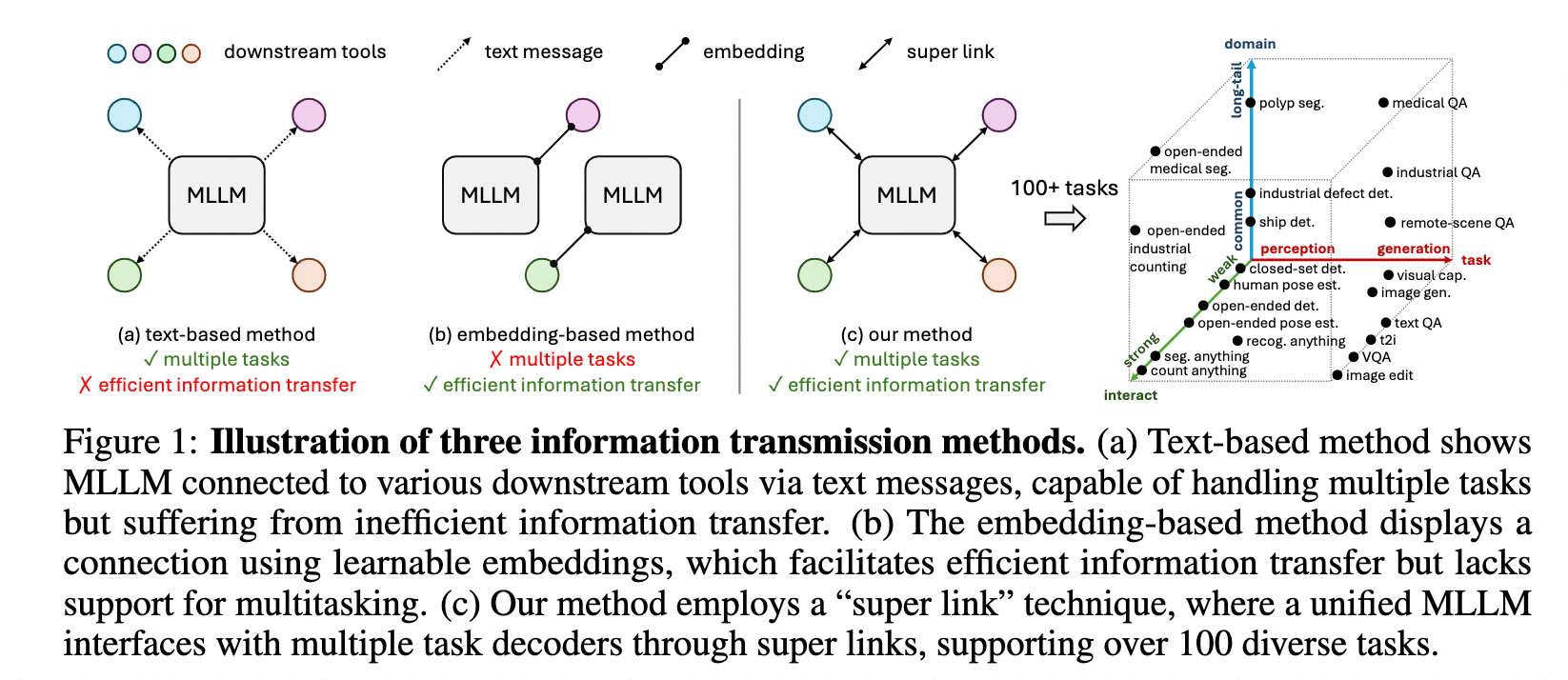
VisionLLM v2
Three distinct characteristics
- 普遍性。在一套参数下,该模型能够通过不同的文本和视觉prompt推广到不同的任务。这是第一个端到端支持上百个视觉-文本任务的模型,并且与专业领域模型获得可比较性能。
- 开放性。通过开集的decoders,该模型允许我们通过多模态prompt自由的定义任务,打破了仅限于预定义任务或类别的封闭集模型的约束。并且可以通过多轮对话灵活的将不同的任务组合成更复杂的任务。
- 多模态上下文能力。通过多模态输入和输出,该模型展示了广泛的多功能性,并且比以前的具有单模态输出的上下文模型具有优势。这些特征将该模型与以前的方法区分开来,并为各种视觉和视觉语言应用程序建立了一个领先的基础 MLLM。
Contributions
- 支持使用文本、视觉和上下文指令来完成数百项视觉语言任务,包括多模态对话、对象检测、实例分割、交互式分割、姿势估计、图像生成和编辑等。
- 在多个领域 (例如工业,医疗和遥感图像) 显示出强大的通用性。
- 在各种标准基准上与专家模型实现了可比的性能。
Method
模型结构
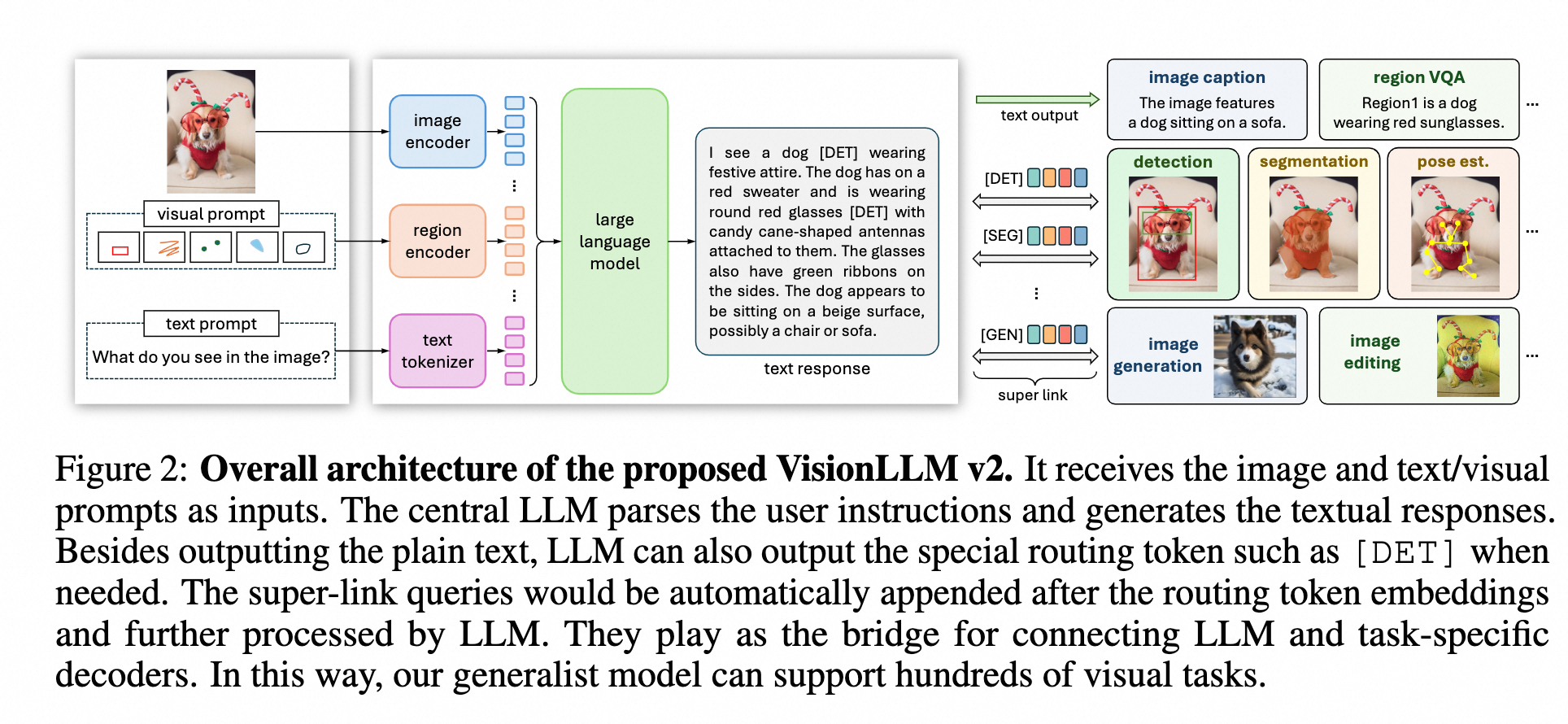
VisionLLM v2主要由以下四个结构组成
- Prompt处理部分
(image encoder, region encoder, text tokenizer)用来编码图片维度和region维度的信息。这一个结构对不同类型的prompt输入的处理方式
- text prompts, 与其他LLM相同,使用tokenizer来进行编码
- image input,利用CLIP等视觉模型提取图片特征,过程中使用动态分辨率策略,将图片切分为多个336*336的图片
- visual prompt,使用二进制掩码来灵活地表示visual prompt,例如点、框、涂鸦和掩码。为了提取region嵌入,首先将二进制掩码与沿通道维度的输入图像连接起来,然后用三个卷积层对其进行处理(下采样 14 倍),另外通过添加全局图像的特征图进一步增强了这个特征图。最后,利用grid sampling提取掩码区域内的特征,并对这些特征进行平均,形成visual prompt的特征
- 大语言模型部分
处理多模态输入然后生成令人满意的文本响应。
- 一系列特定任务的decoders
用来执行对应的下游视觉任务,实现方式是丢弃这些decoders的文本编码器部分,并通过super link技术将它们与MLLM链接,来实现端到端训练。具体下游任务与其对应的模型:
- 目标定位:Grounding DINO
- 图片分割:mask decoder
- 姿态估计:UniPose
- 图片生成:Stable Diffusion v1.5
- 图片编辑:InstructPix2Pix
- super link
使用routing token和super-link queries用于高效且无冲突的信息传递。
Super link
Super link包含两部分,routing token和super-link queries。
- Routing Token
增加特殊token([DET], [POSE], [GEN]等)到MLLM词表中,当MLLM预测出对应的token表示选择对应的decoder。
- Super-Link Queries
与Routing Token绑定的随机初始化的可学习权重。这些queries在Routing Token之后附加并由 MLLM 处理以提取特定于任务的信息,然后将其发送到目标decoder。
- Forward方式
Super Link实现了灵活的任务信息传输,允许解码器梯度反向传播到MLLM,并通过确保Queries绑定到Routing Token而不是跨任务共享来避免任务冲突。为了使模型能够识别要执行哪些任务和要输出哪些Routing Token,论文使用 ChatGPT 为不同的任务构建一系列指令模板。
Super-Link Queries定义为一组固定的嵌入。当LLM预测出Routing Token时,对应的Queries会添加到Routing Token后面,然后利用一层MLP将最后一层的hidden states进行编码,然后送到对应的下游任务decoder作为条件输入来处理对应下游任务,不同的任务对应着不同的forward方式:
- Visual Perception (object detection, instance segmentation, pose estimation, etc.):通过从相应的Super-Link Queries中提取 MLLM 的输出hidden states并将它们池化为一个嵌入来获得per-region表示。这些嵌入被送到分割解码器作为条件特征,只需要一次forward来为所有区域生成分割结果。

- Visual Generation:放弃文本encoder,并使用 MLLM 的输出隐藏状态作为 Stable Diffusion 的图像生成条件。图像编辑任务也可以通过使用图像和文本提示作为输入在以相同的方式完成。
训练策略
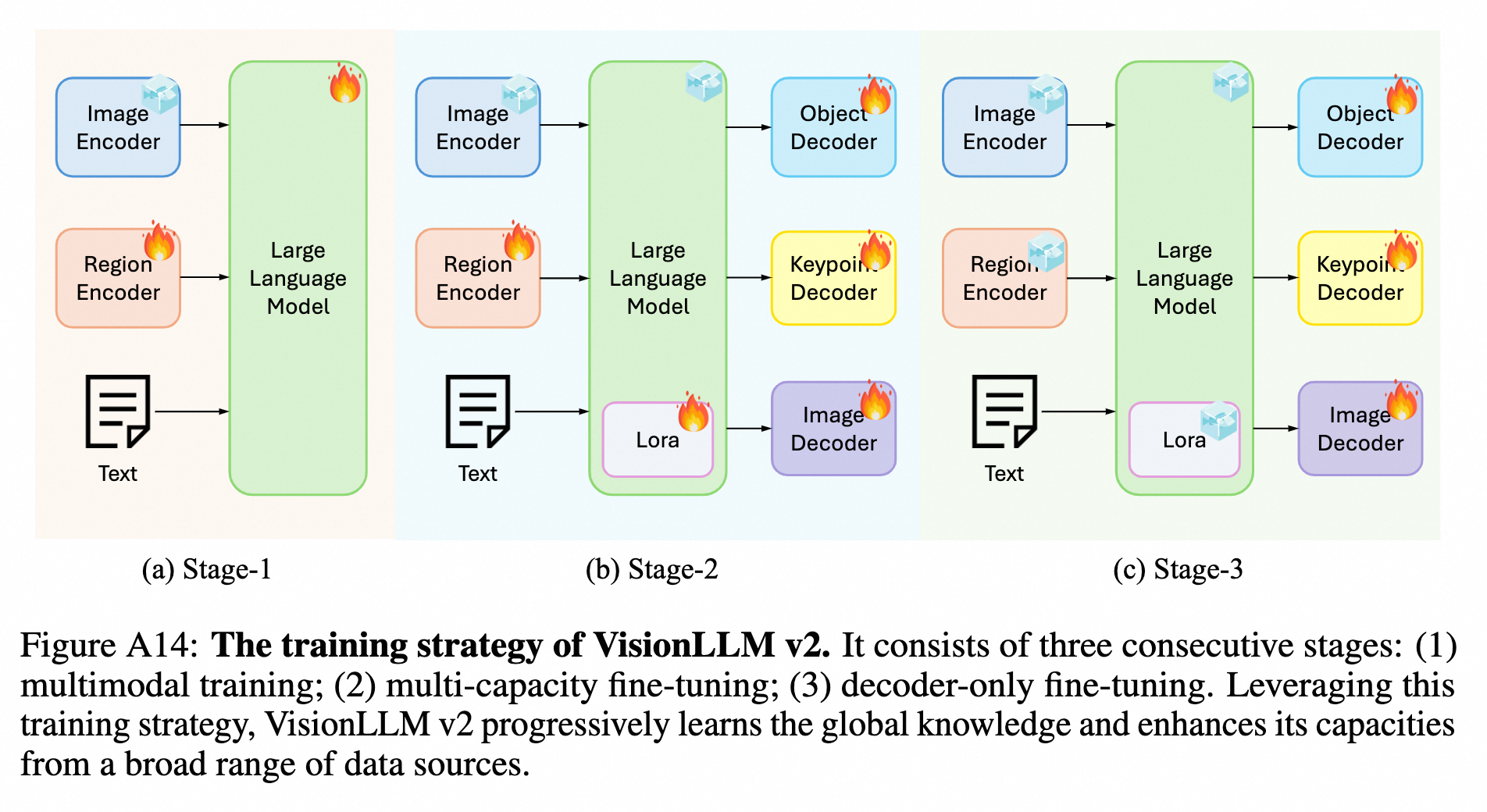
三阶段训练策略,第一阶段专注于构建一个强大的image-level和region-level的视觉理解能力的MLLM,随后阶段添加特定任务的decoder然后继续训练来给模型额外的能力
- Mutimodal Training:Pre-training and instruction tuning,得到VisionLLM v2-Chat
- Multi-capacity Fine-tuning:结合decoder和LLM来处理多任务联合训练,该阶段LLM使用LoRA微调,decoder全量训练
- Decoder-only Fine-tuning:由于解码器不能在单个 epoch 内收敛,我们使用视觉数据集进一步训练解码器 12 个 epoch,同时冻结所有其他组件。值得注意的是,在这个阶段继续训练超级链接查询。在完成三阶段训练后,我们的模型在保持全局视觉理解中的有效性的同时,对视觉任务具有不同的能力,称为VisionLLM v2
模型细节
- Image Encoder
- CLIP-L/14
- LLM
- Vicuna-7B-v1.5
- Decoders
- 目标定位:Grounding DINO
- 图片分割:mask decoder
- 姿态估计:UniPose
- 图片生成:Stable Diffusion v1.5
- 图片编辑:InstructPix2Pix
模型效果
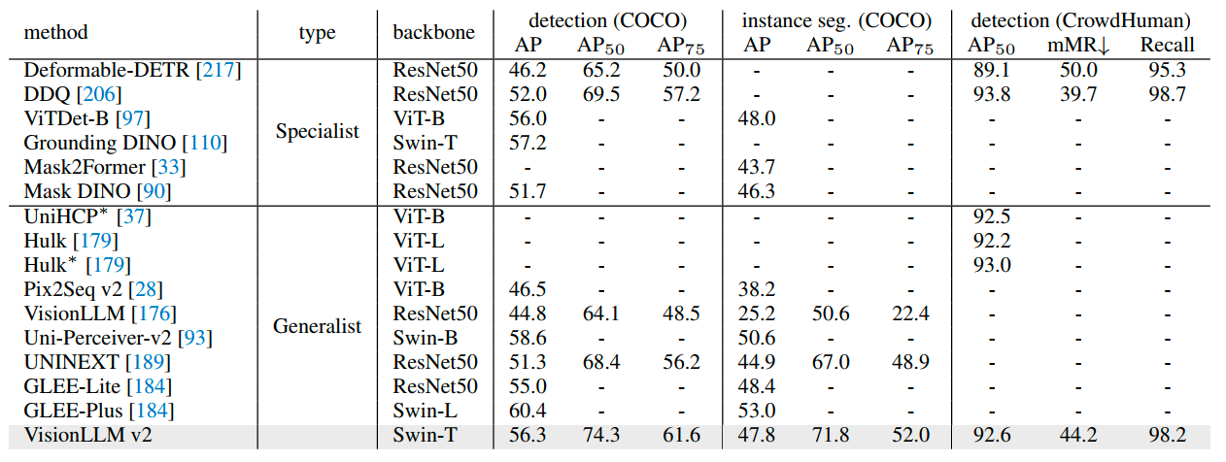
Quantative Results
Object Detection and Instance Segmentation
Pose Estimation

Qualitative Results
Visual Perception


Visual Generation

















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









