










Code: https://github.com/OpenGVLab/VisionLLM
目录
3.2 Unified Language Instruction
3.3 Language-Guided Image Tokenizer
3.4 LLM-based Open-Ended Task Decoder
摘要:
在计算机视觉领域,尽管有许多功能强大的视觉基础模型(VFMs),但它们难以与 LLMs 的开放式任务能力相媲美。
此论文任务:
以视觉为中心的任务提出了一个基于 LLM 的框架,称为 VisionLLM。
视觉和语言任务统一:该框架将图像视为一种外语,并将以视觉为中心的任务与可使用语言指令灵活定义和管理的语言任务相统一,从而为视觉和语言任务提供了一个统一的视角。
基于 LLM 的解码器可以根据这些指令对开放式任务进行适当的预测。
实验:
大量实验表明,所提出的 VisionLLM 可以通过语言指令实现不同程度的任务定制,从细粒度的对象级定制到粗粒度的任务级定制,均取得了良好的效果。
值得注意的是,在基于通用 LLM 的框架下,模型可以在 COCO 上实现超过 60% 的 mAP,与特定检测模型相当。希望这个模型能为通用视觉和语言模型设定一个新的基线。
1 Introduction
计算机视觉领域面临着一系列与 NLP 不同的独特挑战和范式。
视觉模型局限性:
视觉基础模型的传统模式是预训练,然后进行微调 [51 , 11 , 43 , 53, 17, 44 ],这种方法虽然有效,但在适应不同的下游场景时会产生巨大的边际成本。
如图 1a 所示,虽然多任务统一[38 , 50 , 1, 49 , 72]等方法已被用于实现通用能力,但它们往往难以克服预定义任务带来的限制,导致开放式任务能力与 LLM 相比存在差距。
最近,视觉提示调整[ 24 , 66 , 70, 67 , 54]作为一种方法出现,可以灵活地勾勒出一些纯视觉任务(见图 1b),如物体检测、实例分析、图像处理使用视觉掩蔽进行分割和姿势估计等。
然而,视觉提示的格式与语言指令的格式大相径庭,这使得将 LLMs 的推理能力和世界知识直接应用于视觉任务具有挑战性。
因此,需要一个统一的通用框架,将 LLM 的优势与以视觉为中心的任务的特殊要求完美地结合起来。
论文方法:
在这项工作中,作者提出了 VisionLLM,这是一个新颖的框架,它将以视觉为中心的任务定义与 LLM 的方法论相统一。
VisionLLM 利用 LLM 的推理和解析能力,旨在增强以视觉为中心的任务的开放式任务能力。
具体来说,它由三个核心部分组成:
(1) 专为视觉和视觉语言任务设计的统一语言指令;
(2) 语言引导的图像标记器;
(3) 基于 LLM 的开放式任务解码器,可使用语言指令协调各种任务。
有了这个框架,各种以视觉为中心的任务就可以无缝集成,包括物体检测、实例分割、图像字幕和视觉接地。此外,该框架还有助于在不同粒度水平上进行任务定制,允许定制目标对象、输出格式、任务描述等。
贡献:
VisionLLM 是第一个利用 LLM 的强大功能,以开放式和可定制的方式处理以视觉为中心的任务的框架。通过将以视觉为中心的任务定义与 LLM 方法相统一,VisionLLM 在实现视觉和语言的统一建模方面开辟了新天地,为推动该领域的发展提供了可能性。
通过设计与语言模型格式相匹配的统一语言指令,克服了将 LLM 移植到以视觉为中心的任务时遇到的诸多困难,并涵盖了包括视觉感知在内的各种以视觉为中心的任务。相应地,开发了语言引导的图像标记器和基于 LLM 的任务解码器,它们可以根据给定的语言指令,基于 LLM 的推理和解析能力处理开放式任务。
作者构建了一系列不同粒度的任务来验证模型的有效性,这些任务从简单到困难,从预定义到灵活。通过这些验证,证明了模型具有显著的通用性,展示了它们处理不同任务的能力。包括随机对象类别、随机输出格式和随机任务描述,如图 2 所示。此外,通过基于 LLM 的通用框架,模型还在各种以视觉为中心的任务上产生了有希望的结果。

2 Related Work
2.1 Large Language Model
大语言模型(LLM)在语言生成、语境学习、世界知识和推理等方面的能力令人印象深刻,因此在自然语言处理(NLP)和人工通用智能(AGI)领域备受关注。GPT 系列,包括 GPT-3 [ 5 ]、ChatGPT [35]、GPT-4 [34] 和 InstructGPT [ 36] 是 LLMs 中最具代表性的作品。其他 LLMs,如 OPT [ 69 ]、LLaMA [ 46 ]、MOSS [ 14 ] 和 GLM [ 68 ] 也为该领域做出了重大贡献。这些模型性能很高,而且开源,是训练大型模型的宝贵资源,也是为特定目的进一步微调的基础。例如,Alpaca[45] 引入了一个自我指令框架,便于对 LLaMA 模型进行指令调整,减少了对人工编写指令数据的依赖。
最近,这些 LLM 的出现也为解决以视觉为中心的任务开辟了基于 API 的应用。这些应用程序将视觉应用程序接口与语言模型整合在一起,以实现基于视觉信息的决策或规划,如Visual ChatGPT [ 60 ]、MM-REACT [65 ]、HuggingGPT [42 ]、InternGPT [32 ]和VideoChat [28]。
然而,尽管使用基于语言的指令来定义任务和描述视觉元素非常方便,但这些交互系统 [60 , 65 , 42 , 32 , 28 ]在捕捉细粒度视觉细节和理解复杂的视觉环境方面仍然存在局限性,这阻碍了它们有效连接视觉和LLM的能力。总之,尽管 LLM 在各种 NLP 应用中展现出了巨大潜力,但其在以视觉为中心的任务中的适用性却受到了模态和任务格式所带来的挑战的限制。
2.2 Vision Generalist Mode
通用模型[74, 33, 62]旨在使用共享架构和参数处理各种任务,追求通用模型一直是机器学习界的长期目标。
受序列到序列(seq2seq)模型在 NLP 领域取得成功的启发[38],OFA[50]、Flamingo[1]和 GIT[49] 等最新研究成果提出将各种任务建模为序列生成任务。
Unified-IO [33]、Pix2Seq v2 [8] 和 UniTab [63] 通过使用离散坐标标记对更多任务的空间信息进行编码和解码,扩展了这一想法。
Gato [39] 也将强化学习任务纳入了 seq2seq 框架,而 GPV [ 19] 则通过将 seq2seq 模块与基于 DETR 的视觉编码器 [ 6] 相结合,开发了一种通用视觉系统。
然而,这些方法都存在一些局限性,如推理速度慢,以及由于非并行自动回归解码过程导致的性能下降。
Uni-Perceivers [74 , 72 , 26] 解决了这些问题,它将不同的任务统一起来,使用基于表征相似性的最大似然目标来处理每个输入,而不管它们的模态如何,这样就有可能在一个统一的框架中同时支持生成和非生成任务。
然而,这些通用模型仍然受限于预定义的任务,无法支持基于语言指令的灵活的开放式任务定制,如 LLMs
2.3 Instruction Tuning
正如 GPT-3 [5] 所介绍的那样,语言指令是表达各种 NLP 任务和 LLM 示例的强大方法。
秉承这一理念,InstructGPT [ 36 ]、FLAN [13, 59] 和 OPT-IML [23] 等后续作品探索了指令调整方法[58, 57],并证明这种简单的方法能有效增强 LLM 的zero-shot, few shot能力。
计算机视觉领域也采用了语言指令范式来定义图像到文本的任务。Flamingo [ 1] 是一项里程碑式的工作,它使用视觉和语言输入作为提示,并在各种视觉语言任务(如图像字幕 [ 9] 和 VQA [ 2] 等)中取得了显著的zero shot效果。
BLIP-2 [ 27 ] 通过查询transformer和线性投影层进一步将视觉编码器与 LLM 连接起来,从而建立了强大的多模态模型。
MiniGPT-4 [ 71 ] 和 LLaVA [ 30 ] 在合成的多模态指令跟随数据上对 BLIP-2 型模型进行了微调,以释放 LLM 的潜力。
然而,这些模型主要关注图像到文本的任务,未能解决视觉感知问题,如物体检测、实例分割、姿势估计等。
为了解决图像涂画任务,Bar 等人[3] 首次提出了利用离散标记在图像上进行涂画的视觉提示框架。
Painter [55] 和 SegGPT [56] 在原始像素上采用了遮罩图像建模,用于配对图像的上下文学习。
虽然这些视觉提示模型在分割任务中表现出了良好的效果,但要将它们应用到现实世界中的众多视觉任务中仍具有挑战性。此外,将视觉提示定义为图像内画与 LLM 的语言指令不一致,难以利用 LLM 的推理、解析能力和世界知识。
在这项工作中,作者旨在将以视觉为中心的任务与语言任务结合起来,使用语言指令统一、灵活地定义所有任务,并使用基于 LLM 的共享任务解码器来解决这些任务。
3 VisionLLM
3.1 Overall Architecture
这项工作的目标是提供一个统一的通用框架,将大型语言模型(LLM)的优势与以视觉为中心的任务的具体要求无缝结合起来。如图 3 所示,VisionLLM 的整体架构由三个关键设计组成:
(1)统一的语言指令,为以视觉为中心的任务定义和定制提供一致的界面;
(2)语言引导的图像标记器,根据给定的语言提示编码视觉信息,使模型能够有效地理解和解析视觉内容;
(3)基于 LLM 的开放式任务解码器,利用编码的视觉信息和语言指令生成令人满意的预测或输出。
这三种设计共同实现了一个灵活的开放式框架,可通过语言指令在不同的任务定制水平上处理各种以视觉为中心的任务。
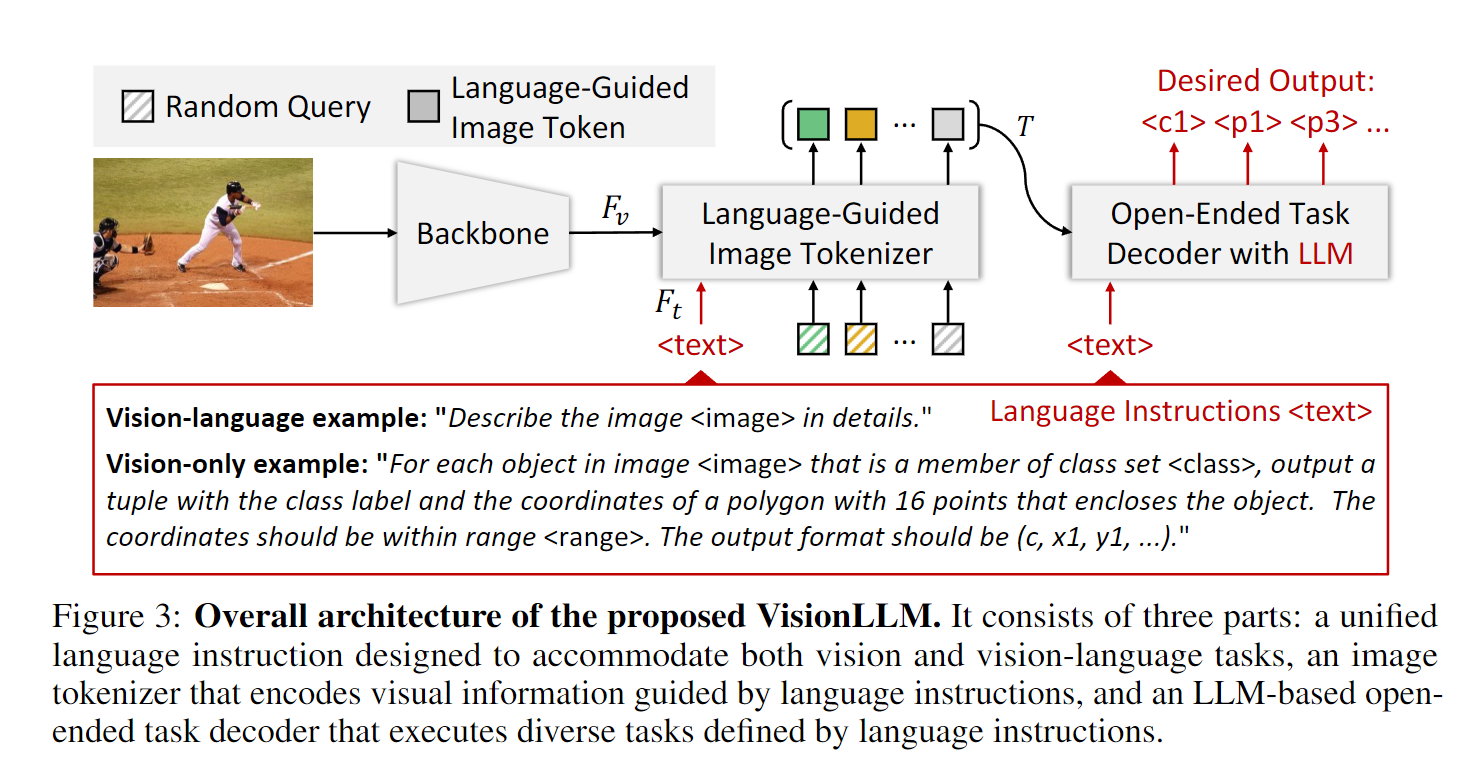
与以往依赖应用程序接口的交互式系统[60 , 65 , 42 , 32 , 28]不同, VisionLLM 提供了一个更加灵活的端到端流水线。
给定描述当前任务的语言指令和输入图像,模型首先使用语言引导的图像标记器,根据给定的提示对图像标记进行编码。
然后,将图像标记和语言指令输入基于 LLM 的开放式任务解码器。
最后,它根据统一语言指令给出的任务定义对生成的输出进行评估,使模型能够生成特定任务的结果。
这种无缝的端到端流水线使 VisionLLM 能够有效地将视觉和语言结合起来,在以视觉为中心的开放式和可定制的任务中实现卓越的性能。
3.2 Unified Language Instruction
首先引入统一的语言指令来描述以视觉为中心的任务。这种设计能够统一各种纯视觉和视觉语言任务描述,并允许灵活的任务定制。
视觉语言任务。图像字幕和视觉问题解答(VQA)等视觉语言任务的指令简单明了,与 NLP 任务类似。按照以前的方法 [ 27 , 74, 30 ],将图像标题任务描述为 "该图像为 <image>。请为该图像生成一个标题: ",而 VQA 任务则是 "图像是 <image>。请根据问题为图像生成答案: <问题>"。这里,<image> 和 <question> 分别是图片标记和问题的占位符。图片标记直接放置在占位符 <image> 中。
视觉任务。由于视觉和语言在模态和任务格式上的差异,为视觉任务设计有效的语言指令是一项极具挑战性的工作。在此,通过提供任务说明和指定所需的输出格式来描述视觉任务。
(1) 任务描述向语言模型传达了预期任务。按照自我指令[57]的方法,设计了一组带有占位符的种子指令,并利用 LLM 生成大量相关的任务描述,然后在训练过程中随机选择其中之一。
(2) 对于物体检测和实例分割等传统视觉感知任务,提出了一种统一的输出格式,用元组(C,P)表示,其中 C 表示类别集 <class> 中的类别索引,P = {xi, yi} 表示定位物体的 N 个点。为了与词token的格式保持一致,类别索引 C 和点 xi、yi 的坐标都被转换为离散化的标记。
具体来说,类别索引是一个从 0 开始的整数,而点的连续坐标则被统一离散为[-<range>, <range>]范围内的整数。
对于物体检测和视觉任务,点数 N 等于 2,代表物体边界框的左上角和右下角的点。
在实例分割的情况下,沿物体边界使用多个(N > 8)点来表示实例掩码[ 61 ]。其他感知任务,如姿势估计(关键点检测),也可以用这种方法表述为语言指令。
实例分割任务的语言指令示例如下: "分割图像 <range> 范围内类别集 <class> 的所有对象,并生成格式为 (c, x1, y1, x2, y2, ..., x8, y8) 的列表。其中,c 代表从 0 开始的类别标签索引,而 (x1, y1, x2, y2, ..., x8, y8) 则对应于对象边界点相对于中心点的偏移量。图像为 <image>"
3.3 Language-Guided Image Tokenizer
VisionLLM 将图像视为一种外语,并将其转换为token表示法。与以往利用固定大小的批嵌入来表示图像的工作[16, 52, 31]不同,引入了语言引导的图像标记器,以灵活编码与特定任务的语言提示或指令相一致的视觉信息。
具体来说,给定一幅高度为 H、宽度为 W 的图像 ,首先将其输入图像骨干(如 ResNet [21]),然后提取四种不同尺度的视觉特征 Fv。此外,还利用文本编码器(如 BERT [ 15 ])从给定的提示中提取语言特征 Fl。然后,通过交叉关注(cross attention)[47]将语言特征注入每个尺度的视觉特征中,从而获得多尺度语言感知视觉特征,实现跨模态的特征对齐。
之后,建议采用基于transformer的网络(如可变形 DETR [73]),用 M 个随机初始化查询 Q = {qi} 来捕捉图像的高级信息。在多尺度语言感知视觉特征的基础上构建基于transformer的网络,提取 M 个图像标记 T = {(ei, li),每个标记由一个嵌入 ei 和一个位置 li 表示,表示标记的语义和位置信息。这种设计不仅不受输入分辨率的影响,而且还能提取出与语言提示相关的视觉表征信息.
3.4 LLM-based Open-Ended Task Decoder
解码器基于 Alpaca[45],它是从 LLaMA[ 46 ]改进而来的 LLM,可以在语言引导下处理各种与视觉相关的任务。然而,对于以视觉为中心的任务来说,Alpaca 有一些固有的缺点,例如:(1) 它的词汇中只有少数几个数字标记(如 0∼9),这限制了它通过数字定位对象的能力;(2) 它使用多个标记来表示类别名称,导致对象分类方案效率低下;(3) 它是一个因果模型,对于视觉感知任务效率低下.
为了解决这些问题,扩展了 LLM 的词汇量,增加了专为以视觉为中心的任务设计的token。首先,添加了一组位置标记,表示为{<p-512>, ..., <p0>, ..., <p512>},其中 <p i> 表示 i∈ [-512, 512] 对图像标记的位置 li 的离散偏移,与图像高度或宽度的相对值等于 i/512。这些标记成功地将物体定位任务从连续变量预测转变为更加统一的离散二进制分类。
其次,引入了语义无关的分类标记 {<c0>, <c1>, ..., <c511>} 来替代类别名称标记,从而克服了使用多个标记来表示类别的低效率问题。
语言指令的类别集 <class> 灵活地提供了类别名称和分类标记之间的映射,例如 {"人":<c0>, "车":<c1>, "黑猫":<c2>, ...}。这种设计允许模型从提供的类别集中选择适当的类别名称,从而促进高效、准确的对象分类
此外,为了解决因果框架造成的低效率问题,引入了输出格式即查询解码。首先使用 LLMs 从任务指令中解析结构输出格式(例如,"<cls> <x1> <y1> <x2> <y2>"用于物体检测,"<bos>"用于图像字幕),然后将结构输出格式的标记作为查询输入解码器,根据查询生成所需的输出。这种简单的方法使模型不仅避免了视觉感知任务中逐个token解码的低效率,还为视觉语言任务保留了一个统一的框架。
请注意,在物体检测任务的训练和推理阶段,向解码器输入了 100 组"<cls> <x1> <y1> <x2> <y2>",从而生成了 100 个物体预测。根据物体检测任务的常见做法,置信度较高的预测将被保留下来.
这样,物体定位和分类的输出被表述为一种外语,从而将这些以视觉为中心的任务统一为token分类的格式。因此,无论是视觉语言任务还是纯视觉任务,都可以像语言任务一样使用交叉熵损失进行监督。此外,为了提高训练效率,采用了低阶适应(Low-Rank Adaptation,LoRA)方法[22],这种方法允许在不花费过多计算成本的情况下训练和微调模型。将 LoRA 的等级设置为 64,并在注意力层中的 QKVO(查询、键、值和输出)上使用 LoRA。它还充当了语言和视觉标记之间的桥梁,促进了两种模式之间的有效协调,确保了更好的任务定制,并提高了整个系统的收敛性。
4 Experiment
4.1. Implementation Details
使用两种图像骨干实现了 VisionLLM 的两种变体,即 ResNet [ 21 ] 和 InternImage-H [ 51 ]。
在语言引导图像token器方面,采用 BERT-Large [ 4 ] 作为文本编码器,并采用可变形 DETR (D-DETR) [73] 来捕捉高级信息。
在 LLM 方面,采用了 Alpaca-7B [45],一个用指令微调的 LLaMA [46] 模型,并为其配备了 LoRA [22],以进行参数高效微调。
模型的训练分为两个阶段。在第一阶段,使用预先训练好的 D-DETR 和 BERT 权重对模型进行初始化,并训练视觉骨干和语言引导的图像token器,以生成语言感知的视觉特征。
在第二阶段,将图像标记器与 Alpaca-7B 相连接,并引入多个任务的统一监督。
在冻结视觉骨干的同时,还冻结了 LLM 的大部分参数(少数 LoRA 参数除外)。有关实验设置的更多详情,请参阅补充材料的 B 章。
4.2 任务级定制
首先评估了 VisionLLM 的任务级定制能力。VisionLLM 支持粗粒度任务定制,包括视觉感知任务和视觉语言任务。
表 1 列出了以视觉为中心的四项标准任务的评估结果,包括物体检测、实例分割、视觉接地和图像字幕。
将模型与特定任务方法以及最近提出的视觉通用模型进行了比较。模型的结果来自共享参数的通用模型,并且仅通过改变语言指令来切换不同的任务。详细说明见补充材料。
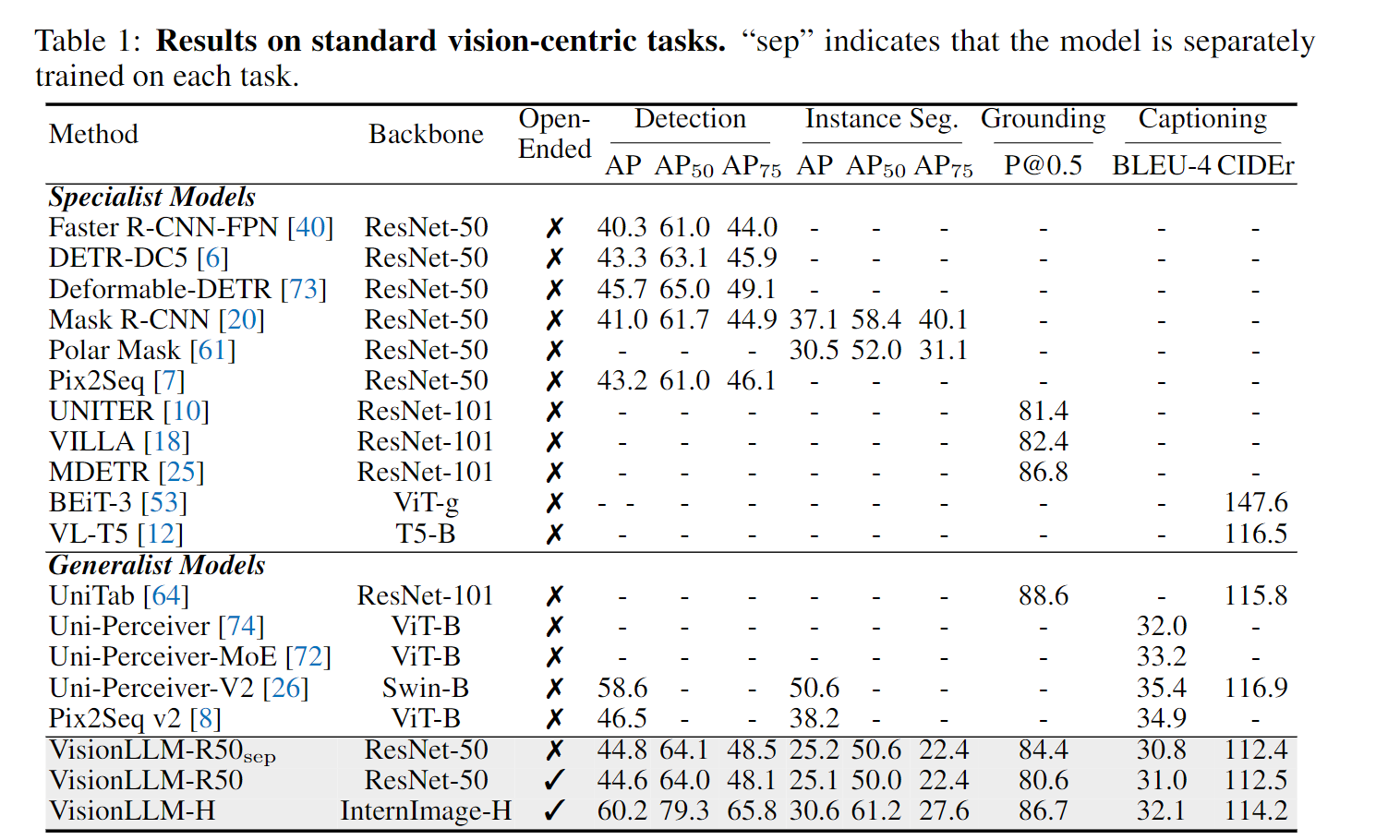
物体检测 :物体检测是一项基本的计算机视觉任务,涉及在图像中识别和定位感兴趣的物体。方法在使用 ResNet-50 [21] 骨干网时,取得了与其他方法相当或更高的结果,即 44.6 mAP。使用相同的骨干网,即 ResNet-50,方法比 Pix2Seq [7] 高出 1.4 mAP,后者也将输出坐标离散为整数。此外,受益于输出格式即查询框架(见第 3.4 节),可以在推理过程中并行解码多个预测,从而使方法更加高效。使用 InternImage-H [ 51] 作为视觉骨干,获得了 60.2% 的 mAP,接近当前最先进的检测专用模型 [51],这证明了通用模型的可扩展性。
视觉接地。视觉定位将文字描述与图像中的相应区域或对象联系起来。训练视觉接地和物体检测可能会相互冲突,因为物体检测的目的是检测所有物体,而视觉接地只应定位所指物体,抑制其他物体。得益于统一的任务指令和 LLM 强大的指令理解能力,我们的模型能有效地完成这两项任务,并在视觉接地方面取得了 80.6 P@0.5 的结果。以 InternImage-H 为骨干,我们在 RefCOCO 的验证集上实现了 86.7 P@0.5。
实例分割。实例分割包括识别和分割图像中的单个对象。沿物体边界采用灵活的点数(即 8∼24)来表示实例掩码。与针对实例的主流模型相比,在分割方面,模型具有可比的掩码 AP50(与 InternImage-H [ 51] 相比为 61.2%),但掩码 AP75 相对较低。这种差距可能是由以下因素造成的: (1) 为了统一任务,将输出坐标离散化为整数,这带来了信息损失;(2) 由于内存和计算限制,模型中的点数量有限,这也导致了性能下降;(3) 与直接掩膜预测方法(如 Mask R-CNN [20] )相比,基于点的方法通常结果较低。
图像标题。还在具有代表性的视觉语言任务(即图像字幕任务)中评估了模型,并报告了 BLEU-4 [37] 和 CIDEr [48] 指标。请注意,我们没有采用 CIDEr 优化[41]。我们可以看到,VisionLLM 的性能与之前的方法相比具有竞争力。使用 ResNet-50 时,我们的 BLEU-4 得分为 31.0,CIDEr 得分为 112.5。当使用 InternImage-H 作为骨干时,我们的模型获得了 32.1 的 BLEU-4 分和 114.2 的 CIDEr 分。这些结果证明了 VisionLLM 在为图像生成描述性和上下文相关的标题方面的有效性。
4.3 对象级和输出格式定制
VisionLLM 不仅可以自定义任务描述,还可以使用语言指令调整目标对象和输出格式。在此,在 COCO 上评估模型的细粒度定制能力。特别是,为了定制目标对象,修改了语言指令中的<class>,将模型的识别目标从 10 个类别改为 80 个类别。同样,为了定制输出格式,修改了语言指令中的点数,从而改变了任务输出格式。表 2 显示,方法在对象级和输出格式更改方面都表现出色。
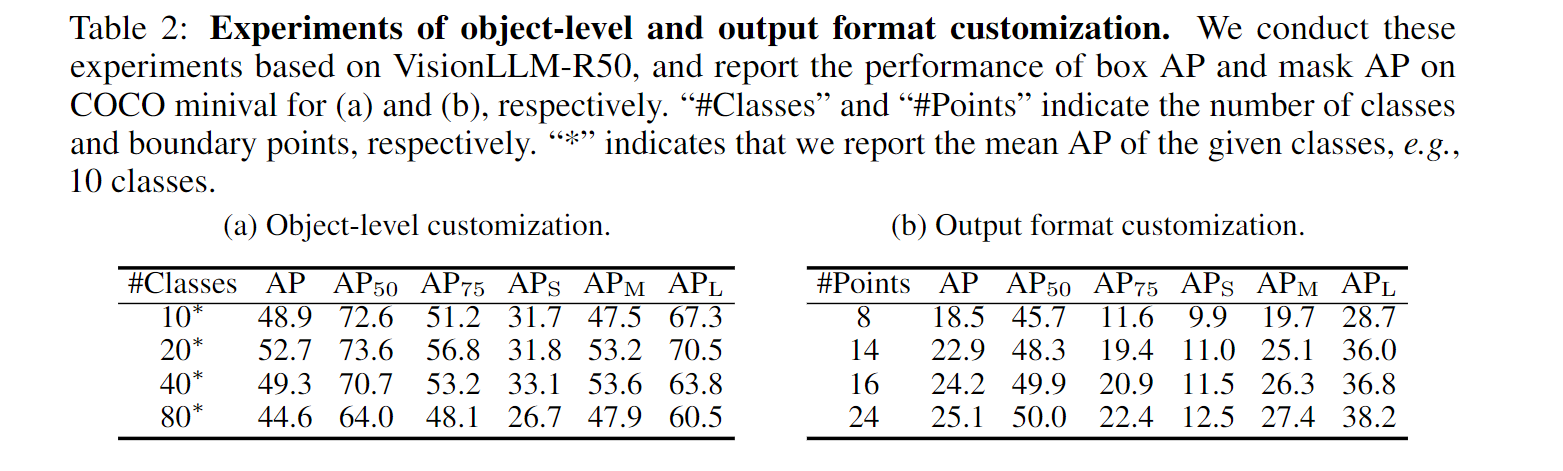
(对象级和输出格式定制实验。在 VisionLLM-R50 的基础上进行了这些实验,并分别报告了(a)和(b)在 COCO minival 上方框 AP 和掩码 AP 的性能。"#类 "和 "#点 "分别表示类和边界点的数量。*"表示报告的是给定类别的平均 AP 值,例如 10 个类别)
4.4 Ablation Study
分析关键组件和超参数对 VisionLLM 的影响。在 COCO2017 [29] 上对具有随机类别和任务描述的物体检测任务进行消融实验。
单一任务与多重任务。进行了一项消融研究,以评估带有语言指令的多任务学习对 VisionLLM 的影响。如表 1 所示,除图像字幕外,单任务训练模型 VisionLLM-R50sep 略优于联合训练模型 VisionLLM-R50。这是由于多任务冲突造成的,这种冲突也影响到以前的泛化模型[74, 72],它反映了准确性和泛化之间的权衡。
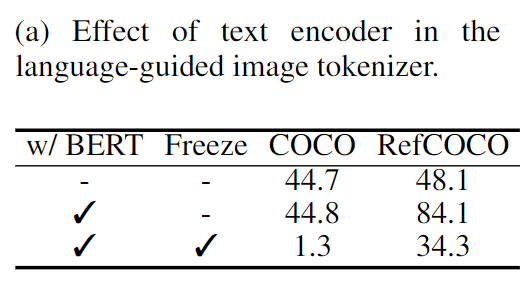
语言引导图像标记符中的文本编码器。在表 3a 中考察了文本编码器(即 BERT)在语言引导图像标记器中的作用,其中报告了对象检测和视觉接地的结果。前两行显示,BERT 对于物体检测并不重要,但对于视觉接地却至关重要。还研究了在训练过程中冻结文本编码器的效果。最后一行表明,冻结 BERT 会阻碍视觉和语言模式的协调,从而降低这两项任务的性能。
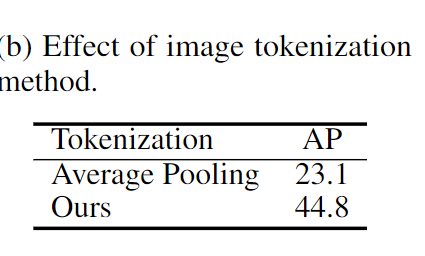
图像标记化方法。作为与基于查询的标记化方法的比较,对来自 D-DETR 编码器的特征图进行平均池化处理,以获得 M 个补丁嵌入,作为图像的标记表示。表 3b 中的结果表明,方法具有明显的优势。这是因为方法能够以更灵活的方式捕捉不同大小物体的信息。
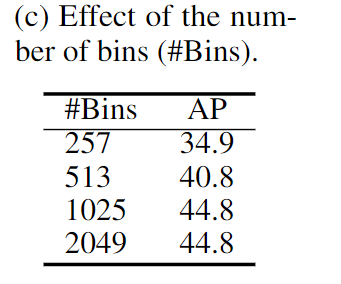
本地化令牌数量。将定位标记数从 257(即-128∼128)改为 2049(即-1024∼1024),以研究其对视觉感知性能的影响。如表 3c 所示,随着定位标记数量的增加,模型的性能不断提高,直至达到饱和点。值得注意的是,当数量从 257 个增加到 1025 个(+9.9 AP)时,性能得到大幅提升。这些结果表明,更多的定位标记数能够使模型实现更精细的定位能力,从而提高定位精度。

















 6981
6981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









