






用LLama Factory的微调并导出大模型时.由于很多模块如之间的依赖关系复杂很容易造成版本冲突,主要涉及到cuda/pytorch/python/auto-gptq/vllm的版本选择.我在AutoDL上经实验了(高,低)两种组合能正常运行LLama Factory,以下是详细说明.
一.硬件配置
采用租用云算力服务器方式:由于是基于大于1B的大模型需要硬件配置较高,租用算力服务器比如AutoDL算力云一小时也就1-2元左右,主要是图方便,当然也比自购显卡省钱.关于购买云服务网上较多教程,也不复杂,可自行购买不过每次记得要人走关机,不然会继续扣费.
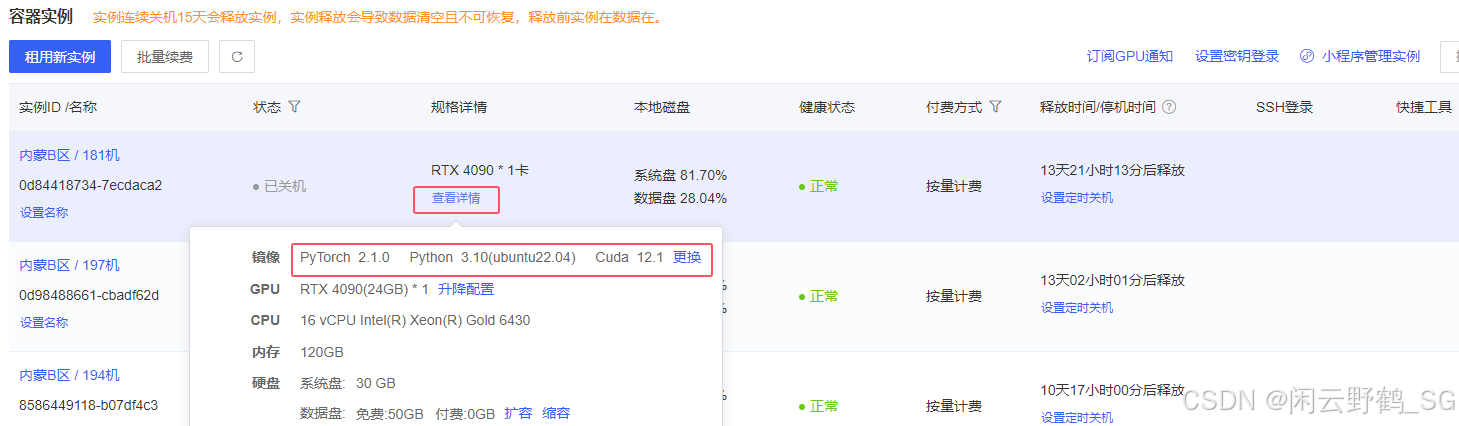
AutoDL服务器租用的时候一定要点"查看详情"查看一下红框内的参数选择,参数务必严格选择,若不一样一定要点击"更换"使之一样(这很重要!否则后续会很麻烦).
我选择的是:RTX4090 ,PyTorch 2.1.0 ,Python 3.10(ubuntu22.04) ,Cuda 12.1
二.环境配置
环境配置很容易出现各种版本冲突,以下是已验证的(高,低)两种组合,可以按需要取其一安装.
高配组合:尽量往高版本靠,忽略官方要求.能正常运行(推荐安装).
版本组合:cuda12.4/pytorch2.5.1/python3.10/auto-gptq 0.7.1/vllm0.6.5
安装方法:
pip install auto-gptq== 0.7.1 #一定要指定安装版本
pip install vllm==0.6.5# 注意:vllm安装的同时,CUDA 12.1将被自动安装覆盖为12.4版本,pytorch2.1.0将被自动安装覆盖为2.5.1版本,无须理会!!!
保守组合:均严格按照官方要求的支持的稳定版本.稳定性可能高些但性能可能低些.
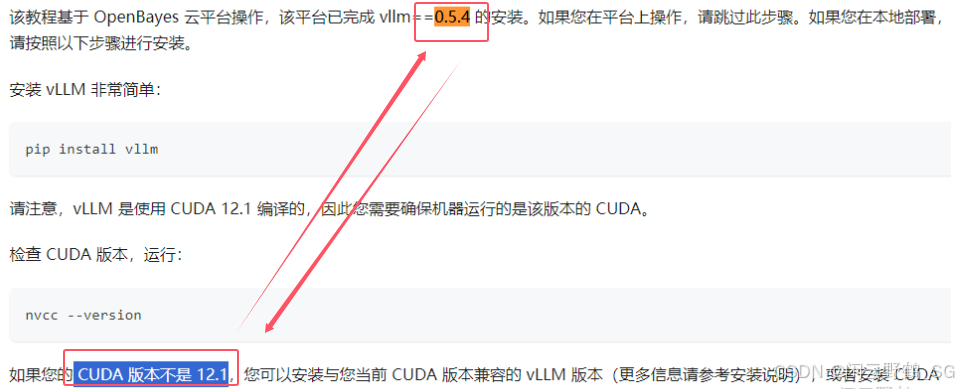
版本组合:cuda12.1/pytorch2.1.0/python3.10/auto-gptq0.5.1/vllm0.5.4安装方法:
pip install auto-gptq==0.5.1 #一定要指定安装版本
pip install vllm==0.5.4 # 注意:vllm安装的同时,CUDA 12.1和pytorch将被自
动再安装一次,无须理会!!!
这样cuda /pytorch /python /auto-gptq /vllm 基本环境就安装完了,且没有任何报错.
注意:你可以在安装后检查cuda版本,建议用以下方式查看.
import torch
print(torch.__version__) 不要用nvcc --version和 nvidia-smi查看,否则你看到的版本不一样.
因为在运行PyTorch时,实际使用的CUDA版本通常是PyTorch编译时所依赖的版本。例如,PyTorch显示的版本为2.5.1+cu124,但nvcc --version显示的却是CUDA 12.1版本即即CUDA Toolkit的版本。而PyTorch在运行时并不直接依赖nvcc,而是依赖于CUDA的动态链接库。只要系统上存在与PyTorch所依赖的CUDA 12.4版本兼容的动态链接库,PyTorch就能够正常运行。
此外,nvidia-smi显示的是GPU驱动程序能支持的CUDA运行时最高版本比如12.6。只要PyTorch的运行版本小于nvidia-smi显示的版本即就ok,比如12.4。
还可以查看vllm的版本:pip show vllm 应该显示Version: 0.6.5或者0.5.4
以下是2个版本中的保守组合的依据,当然你可以忽略以下1,2,3,4的解释:
-
AutoDL服务器的参数
-
vLLM 中文站的资料 https://vllm.hyper.ai/docs/getting-started/installation/
-
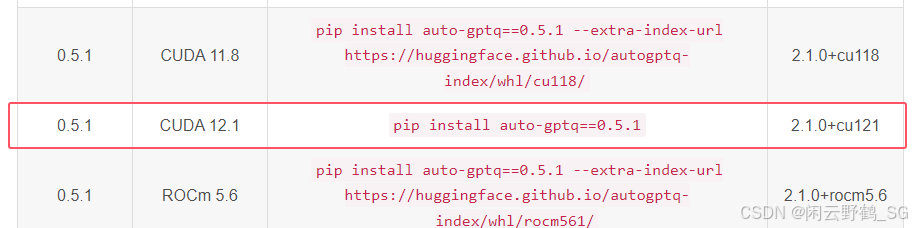
auto-gptq官网资料(科学上网): https://blog.csdn.net/qq_42755230/article/details/144427660
-
其它资料:
auto-gptq最高支持pytorch2.2.1,cuda12.1,后来没更新了.
vllm最高支持pytorch2.5.1版本v
vLLM 包含预编译的 C++ 和 CUDA (12.1) 二进制文件 Python:3.9 – 3.12
vLLM 的二进制文件默认使用 CUDA 12.1 和公共 PyTorch 发行版本进行编译。
vLLM在v0.5.2、v0.5.3和 v0.5.3.post1中,存在由 zmq 引起的错误.
三.微调大模型(lora)
-
安装LLaMA-Factory:先把AutoDL服务器开机,然后通过vscode去连接服务器,通过vscode去连接的好处是,vscode可以直接打开远程页面,因为vscode做了内网穿透.输入身份和密码后打开root目录。在终端输入如下指令即可下载和安装LLaMA-Factory:
source /etc/network_turbo #加速用 git clone https://github.com/hiyouga/LLaMA-Factory.git #下载 cd LLaMA-Factory #一定要进入LLaMA-Factory目录 pip install -e . #安装其它依赖 -
下载大模型:在服务器的autodl_tmp文件夹下建一个test01.py文件用来下载大模型.这里我选择魔塔社区的大模型,当然你可以选择比1B大一点的模型如3B,但不能太大,否则会因为数据集不足造成微调效果不好:
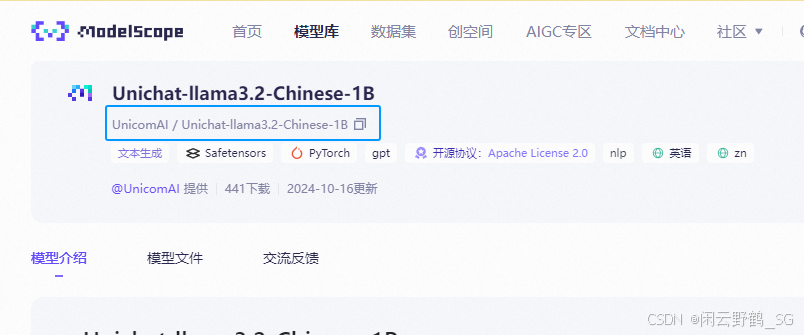
首先安装modelscope: pip install modelscope
然后在服务器的autodl_tmp文件夹下建一个test01.py文件用来下载大模型.
#大模型下载 from modelscope import snapshot_download model_dir = snapshot_download('UnicomAI/Unichat-llama3.2-Chinese-1B',cache_dir="/root/autodl-tmp/llm/")运行test01.py文件下载大模型到/root/autodl-tmp/llm/ 路径下
-
下载弱智吧数据集:注意下载数据集后一定要将格式转换为如下格式,转换可用脚本或者AI帮助转换(略)

-
将转换后的数据集拖到服务器的Data目录下(即拷贝)
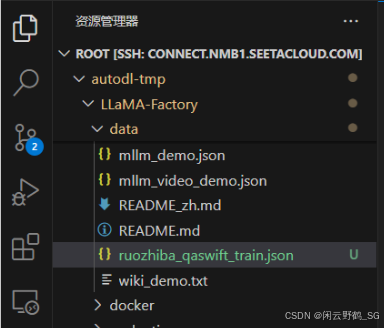
-
将数据集添加到配置文件中:
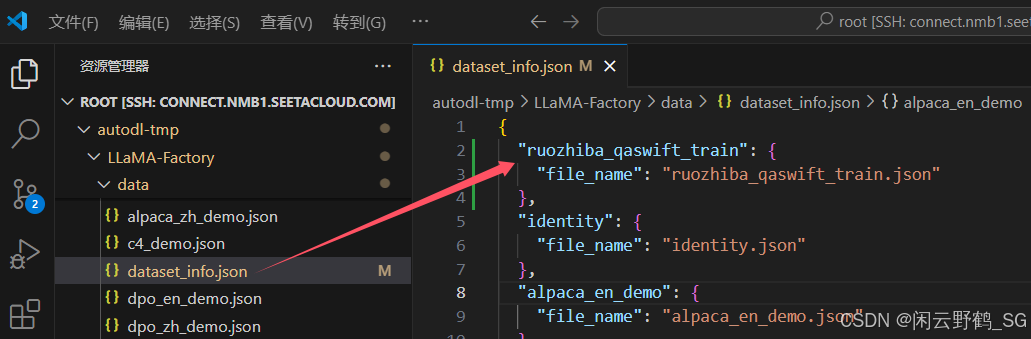
-
启动webUI
cd LLaMA-Factory llamafactory-cli webui -
填写参数:
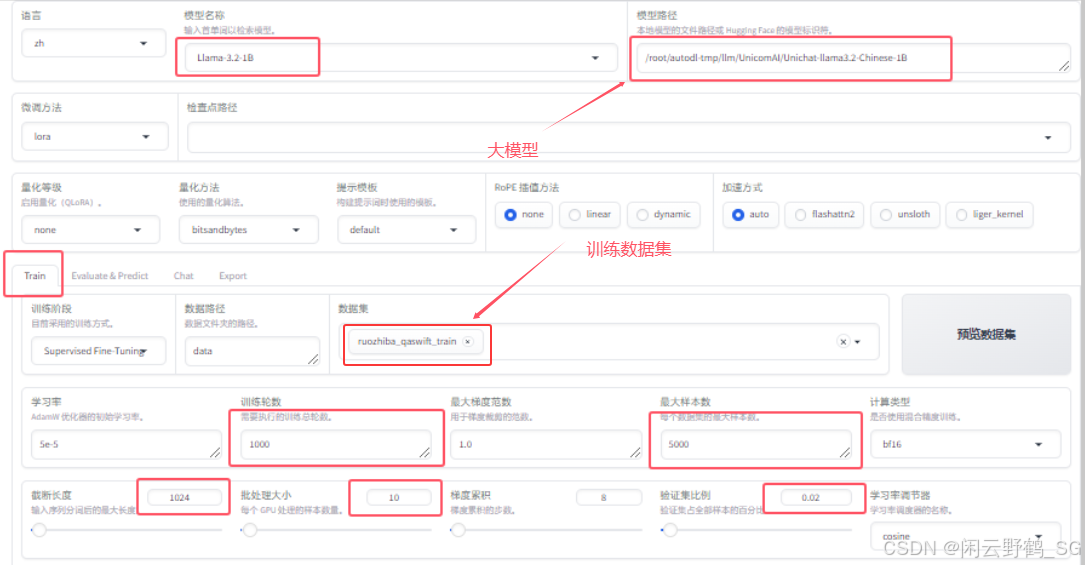
-
点击"开始"进行训练:注意到曲线基本接近水平即可停止训练.
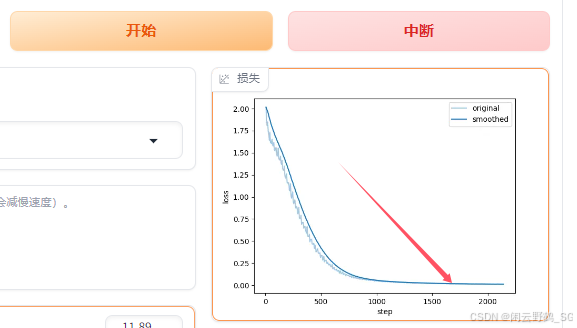
每次训练完之后的权重都会存储在saves路径下面:
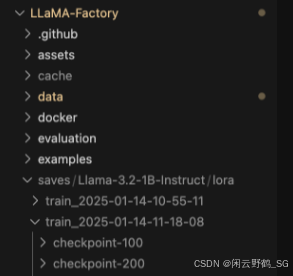
我们可以选取任意一个去进行推理,测试一下我们的训练结果。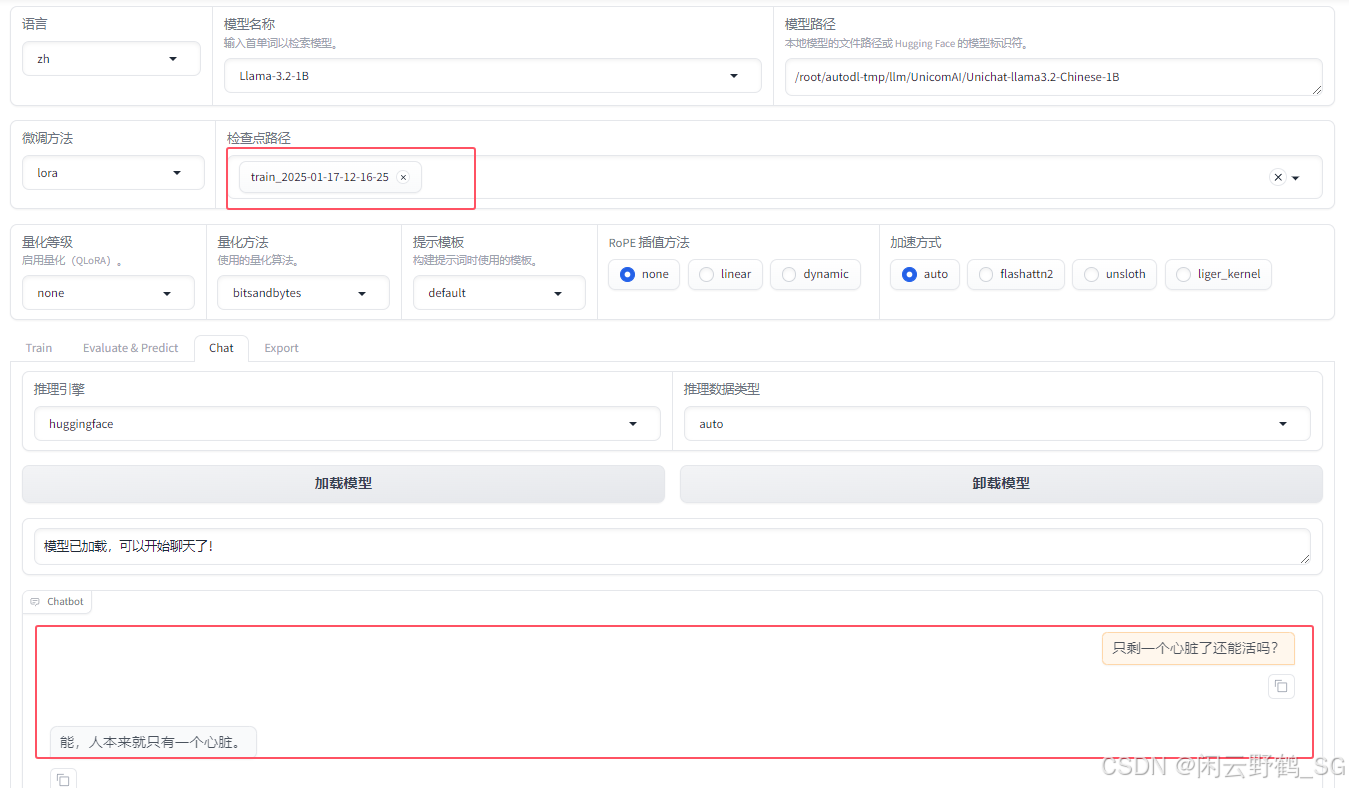
四.合并大模型
-
将saves下面的检查点复制绝对路径到检查点路径,选择导出目录,切换到Export(合并导出)其他参数保持不变.
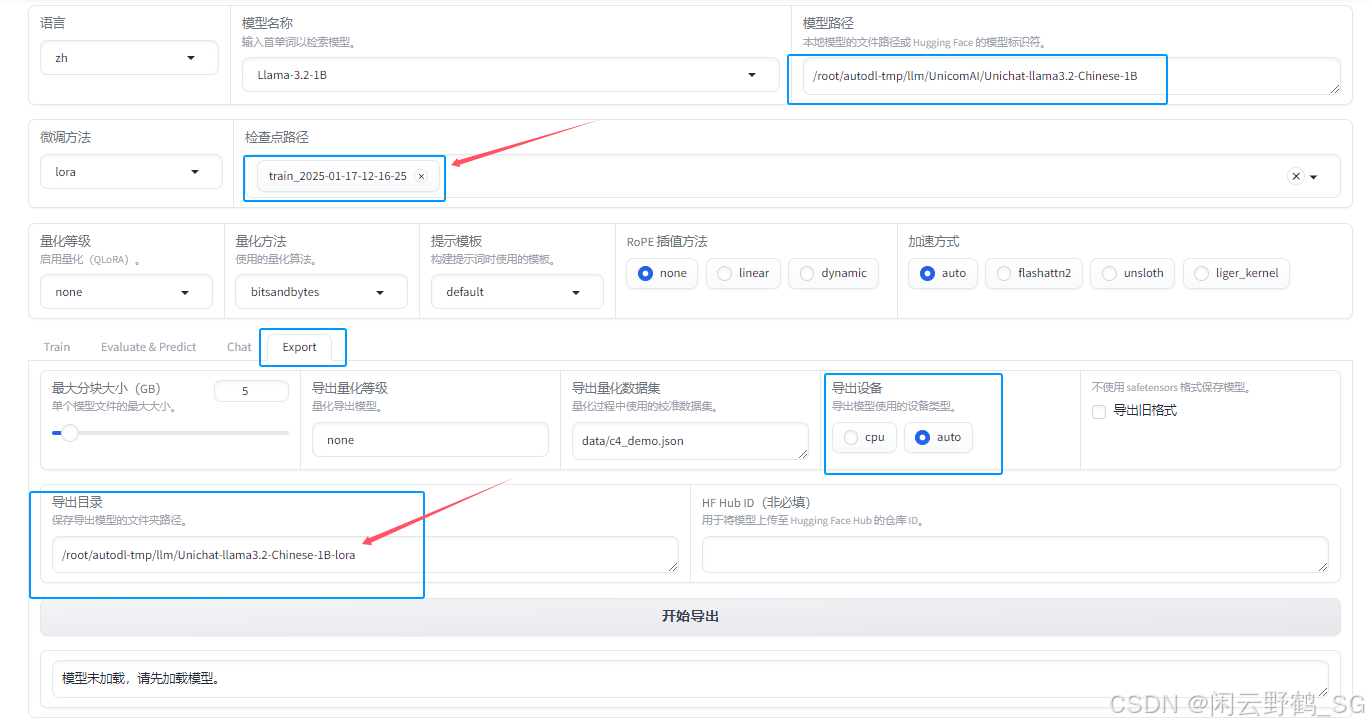
-
重新加载合并后的模型进行检测:
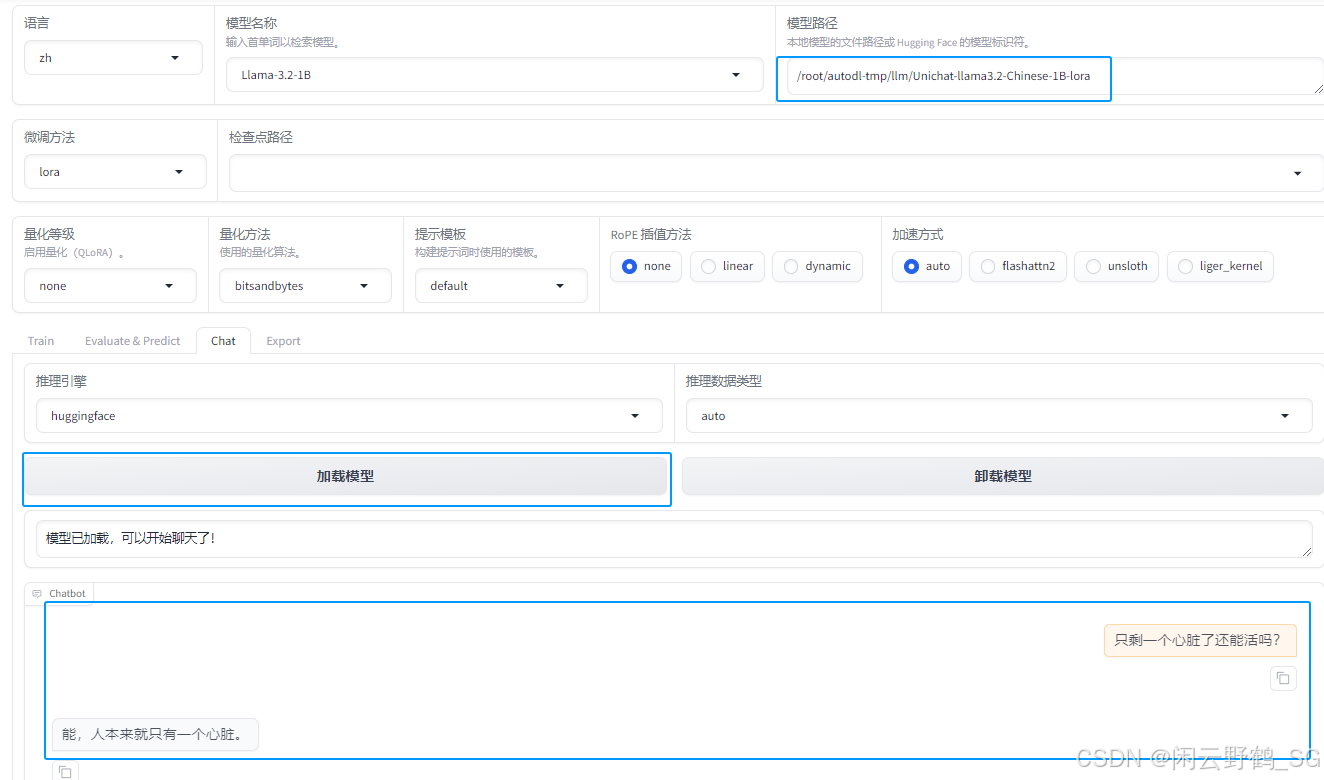
-
可以看到回答同样的问题但是一样的,说明训练成功!
五.采用qlora加速量化大模型训练
qlora加速需要安装bitsandbytes,且必须指定版本,否则很容易出现版本冲突.
pip install bitsandbytes==0.39.0然后点"开始"训练,红色框为与qlora相关的关键参数:
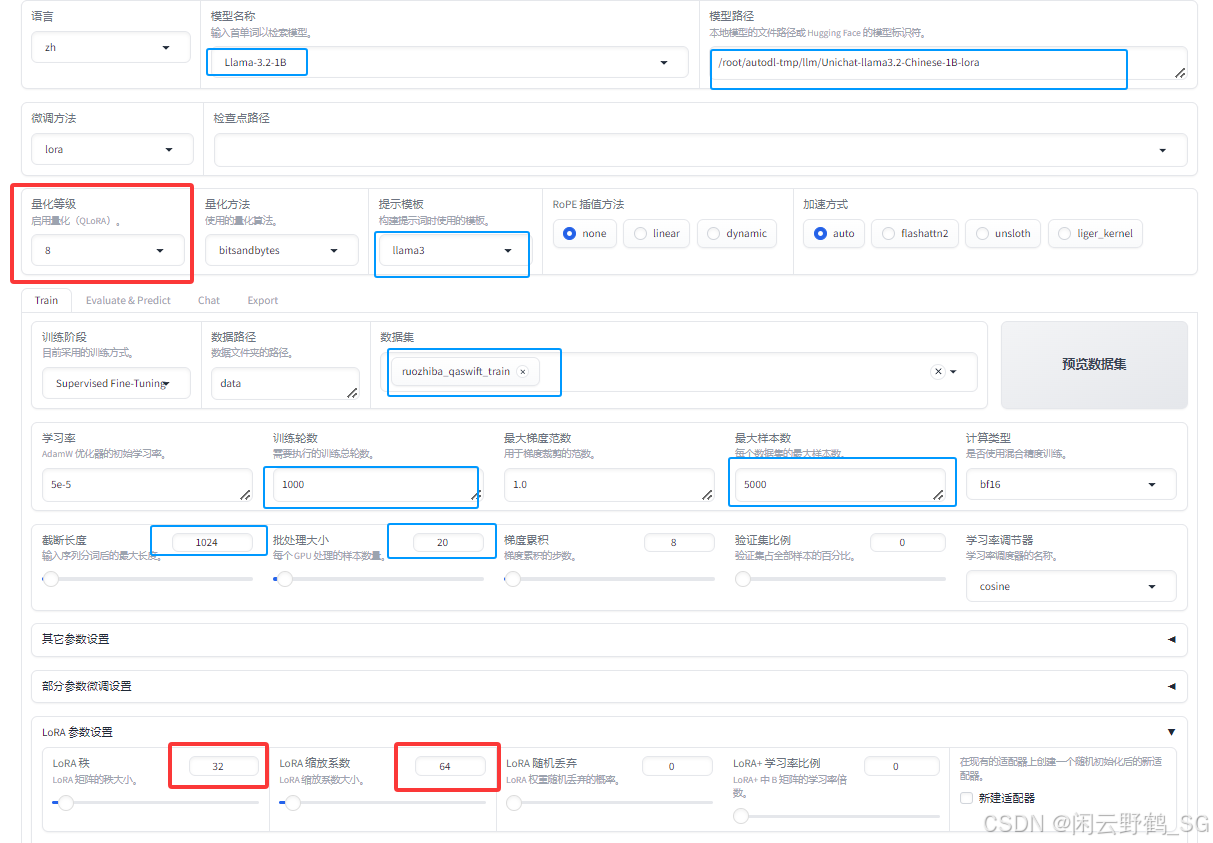
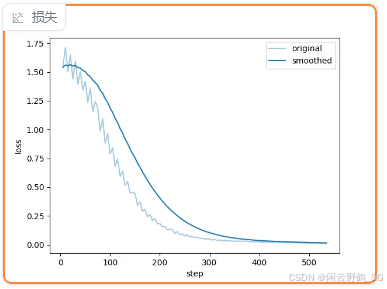
在loss为0.01左右停止训练时的数据:
训练结束后可以保存训练模型,方法见 "四.合并大模型"
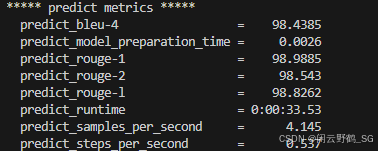
六.客观评估训练效果:
注:由于数据是抽取训练集中的约1/10来做实验,没有严格按照训练数据集与评估数据集分开,所以仅作为实验参考.
在评估前需要安装3个包:
pip install jieba
pip install nltk
pip install rouge_chinese
然后点击"开始"评估,下图红框意为保持与原训练参数一致,蓝色框意义见图中标注:
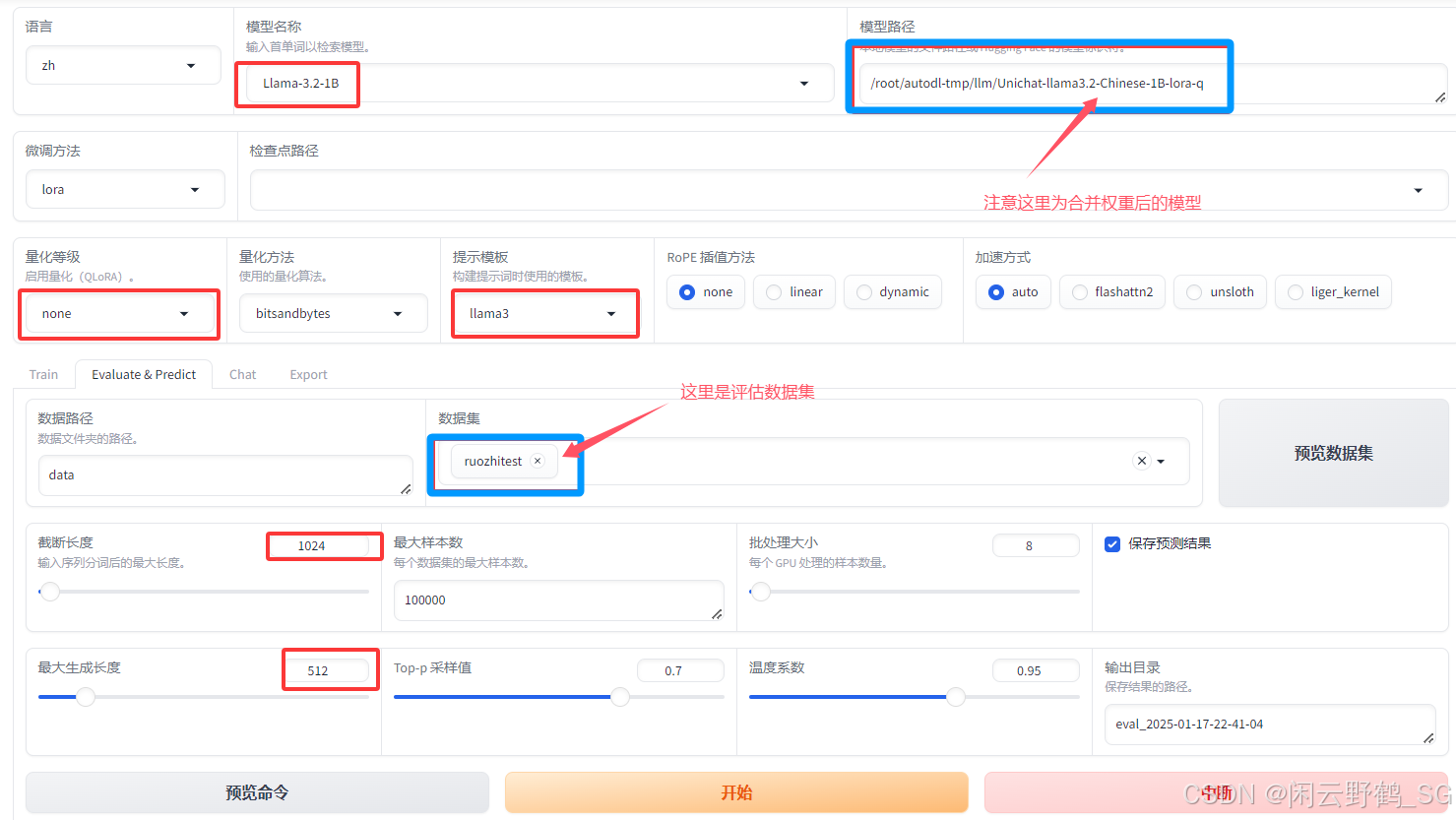
实测结果如下,由于非标准评估集,所以仅作实验性参考:

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









