







卷积神经网络是一种特殊的多层神经网络,像其它的神经网络一样,卷积神经网络也使用一种反向传播算法来进行训练,不同之处在于网络的结构。卷积神经网络的网络连接具有局部连接、参数共享的特点。局部连接是相对于普通神经网络的全连接而言的,是指这一层的某个节点只与上一层的部分节点相连。参数共享是指一层中多个节点的连接共享相同的一组参数。
一个典型的神经网络的结构是全连接的,即某一层的某个节点与上一层的每个节点相连,且每个节点各自使用一套参数,这样的结构就是经典的全连接结构。在全连接的网络中,假如k层有n个节点,k+1层有m个节点,则一共有n*m个连接;每个连接都有一个参数,外加每个k+1层节点有一个bias,则共有n*m + m个训练参数,所以全连接的层的连接数、参数数量的数量级约为O(n^2)。全连接的网络的结构如下图:
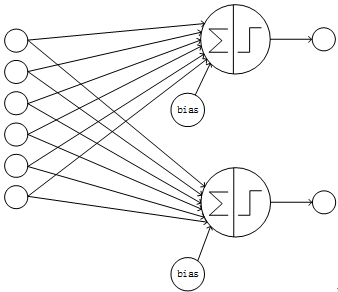
Figure1 全连接的网络
卷积神经网络采用局部连接和参数共享的方式连接网络。对于一个卷积神经网络,假如该网络的第k层有n个节点,k+1层为卷积层且有m个节点,则k+1层的每个节点只与k层的部分节点相连,此处假设只与k层的i个节点相连(局部连接);另外k+1层的每个节点的连接共享相同的参数、相同的bias(参数共享)。这样该卷积神经网络的第k、k+1层间共有m*i个连接、i+1个参数。由于i小于n且为常数,所以卷积层的连接数、参数数量的数量级约为O(n),远小于全连接的O(n^2)的数量级。卷积神经网络的部分连接的结构如下图:
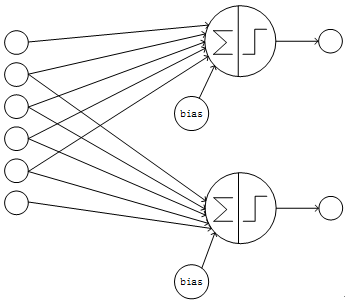
Figure2 部分连接且卷积层各节点的输入节点有重叠的网络
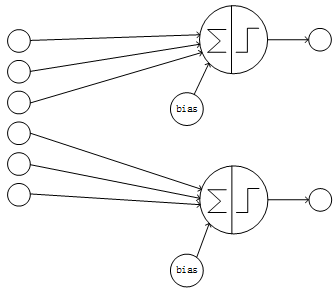
Figure3 部分连接且卷积层各节点的输入节点无重叠的网络
卷积神经网络在使用时往往是多层的,下面通过LeNet-5的网络连接来举例说明一个卷积神经网络的结构和特点。LeNet-5是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,是早期卷积神经网络中最有代表性的实验系统之一。
LenNet-5共有7层(不包括输入层),每层都包含不同数量的训练参数。各层的结构如Figure 4所示:
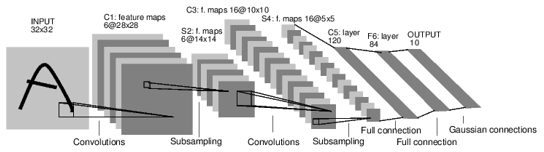
Figure4 LeNet-5的网络结构
LeNet-5中主要的有卷积层、下抽样层、全连接层3中连接方式。全连接层在这里就不赘述。
卷积层采用的都是5x5大小的卷积核,且卷积核每次滑动一个像素,一个特征图谱使用同一个卷积核(即特征图谱内卷积核共享参数),卷积核的结构见Figure 5。每个上层节点的值乘以连接上的参数,把这些乘积及一个偏置参数相加得到一个和,把该和输入激活函数,激活函数的输出即是下一层节点的值。卷积核有5x5个连接参数加上1个偏置共26个训练参数。这样局部连接、参数共享的方式,在数学上相当于上一层节点矩阵与连接参数矩阵做卷积得到的结果矩阵,即下一层的节点值,这是卷积神经网络名字的由来。Figure 6显示了卷积神经网络连接于矩阵卷积的对应关系:
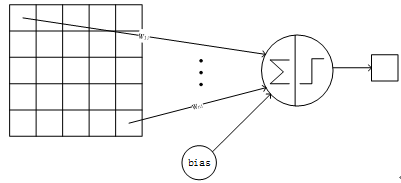
Figure5 一个卷积节点的连接方式
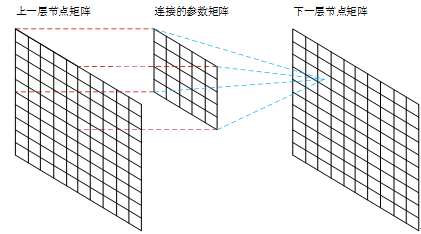
Figure6 卷积神经网络连接与矩阵卷积的对应关系
下抽样层采用的是2x2的输入域,即上一层的4个节点作为下一层1个节点的输入,且输入域不重叠,即每次滑动2个像素,下抽样节点的结构见Figure 6。每个下抽样节点的4个输入节点求和后取平均,均值乘以一个参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。一个下抽样节点只有2个训练参数。
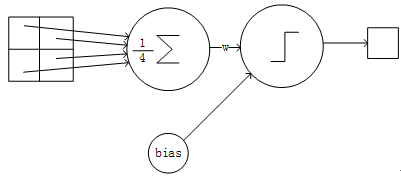
Figure7 一个下抽样节点的连接方式
输入层是32x32像素的图片,比数据集中最大的的字符(最大体积是20x20像素的字符位于28x28像素区域的中心)大很多。这样做的原因是能使潜在的特征比如边缘的端点、拐角能够出现在最高层次的特征解码器的接收域的中心。LeNet-5的最后一个卷积层(C3,见后面)的接收域的中心与输入的32x32的图像的中心的20x20的区域相连。输入的像素值被标准化为背景色(白色)值为-0.1、前景色(黑色)值为1.175,这样使得输入的均值大致为0、方差大致为1,从而有利于加快训练的速度。
在后面的描述中,卷积层用Cx标记,子抽样层用Sx标记,全连接层用Fx标记,其中x表示该层的是LeNet的第x层。
C1层是卷积层,形成6个特征图谱。特征图谱中的每个单元与输入层的一个5x5的相邻区域相连,即卷积的输入区域大小是5x5,每个特征图谱内参数共享,即每个特征图谱内只使用一个共同卷积核,卷积核有5x5个连接参数加上1个偏置共26个参数。卷积区域每次滑动一个像素,这样卷积层形成的特征图谱每个的大小是28x28。C1层共有26x6=156个训练参数,有(5x5+1)x28x28x6=122304个连接。Figure 8 是C1层的连接结构。
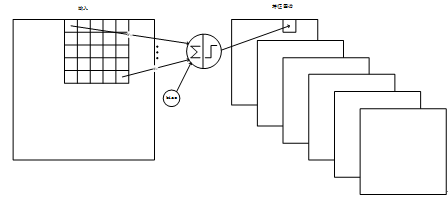
Figure8 C1层的结构
S2层是一个下抽样层。C1层的6个28x28的特征图谱分别进行以2x2为单位的下抽样得到6个14x14的图。每个特征图谱使用一个下抽样核,每个下抽象核有两个训练参数,所以共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。Figure 9是S2层的网络连接的结构。
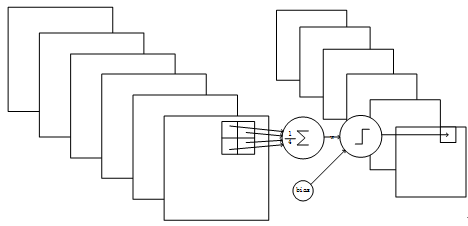
Figure9 S2层的网络结构
C3层是一个卷积层,卷积和和C1相同,不同的是C3的每个节点与S2中的多个图相连。C3层有16个10x10的图,每个图与S2层的连接的方式如Table1 所示。C3与S2中前3个图相连的卷积结构见Figure 10.这种不对称的组合连接的方式有利于提取多种组合特征。改成有(5x5x3+1)x6 + (5x5x4 + 1) x 3 + (5x5x4 +1)x6 + (5x5x6+1)x1 = 1516个训练参数,共有1516x10x10=151600个连接。
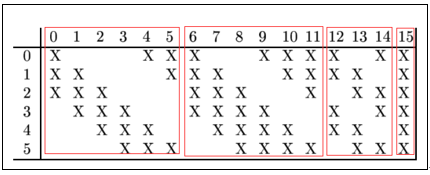
Table 1 C3与S2的连接关系
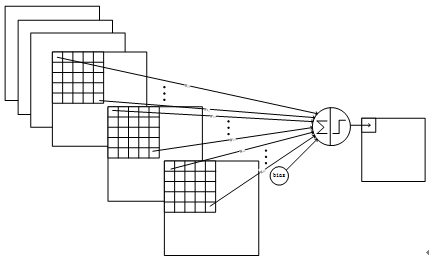
Figure10 C3与S2中前3个图相连的卷积结构
S4是一个下采样层。C3层的16个10x10的图分别进行以2x2为单位的下抽样得到16个5x5的图。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。
C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构见Figure 11。
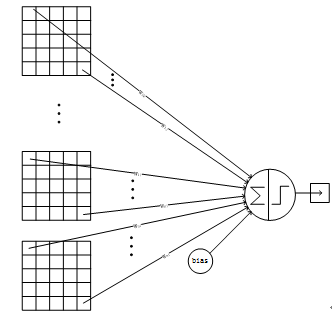
Figure11 C5层的连接方式
F6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164. 比特图的样式见Figure 12,连接方式见Figure 13.

Figure12 编码的比特图
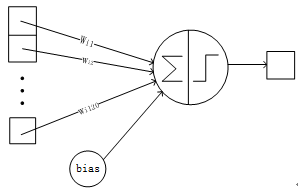
Figure13 F6层的连接方式
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
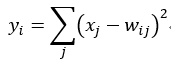
的值由i的比特图编码确定。越接近于0,则越接近于,即越接近于i的比特图编码,表示当前网络输入的识别结果是字符i。该层有84x10=840个设定的参数和连接。连接的方式见Figure 14.
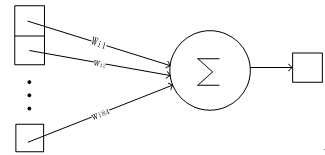
Figure14 Output层的网络连接方式
以上是LeNet-5的卷积神经网络的完整结构,共约有60,840个训练参数,340,908个连接。一个数字识别的效果如Figure 15所示。
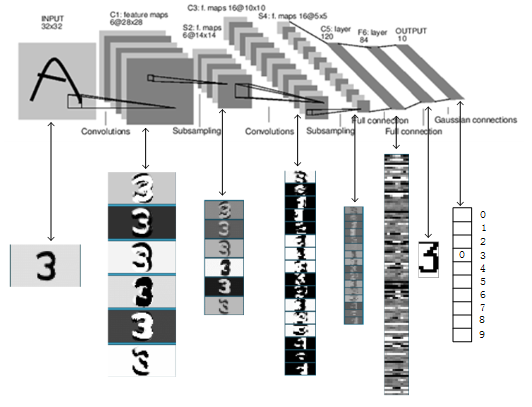
Figure15 LeNet-5识别数字3的过程
通过对LeNet-5的网络结构的分析,可以直观地了解一个卷积神经网络的构建方法,为分析、构建更复杂、更多层的卷积神经网络做准备。
参考文献:
[1] Yoshua Bengio, DEEP LEARNING, Convolutional Networks, http://www.iro.umontreal.ca/~bengioy/dlbook/ .
[2] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. **mnist数据集png图片格式下载链接:** 链接:http://pan.baidu.com/s/1eRG6TqU 密码:uf4m **代码:**
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 10 23:33:01 2018
@author: Administrator
"""
from skimage import io,transform
import os
import glob
import numpy as np
import tensorflow as tf
#将所有的图片重新设置尺寸为32*32
w = 32
h = 32
c = 1
#mnist数据集中训练数据和测试数据保存地址
train_path = "F:/deeplearning/model/Lenet/mnist/train/"
test_path = "F:/deeplearning/model/Lenet/mnist/test/"
#读取图片及其标签函数
def read_image(path):
label_dir = [path+x for x in os.listdir(path) if os.path.isdir(path+x)]
images = []
labels = []
for index,folder in enumerate(label_dir):
for img in glob.glob(folder+'/*.png'):
print("reading the image:%s"%img)
image = io.imread(img)
image = transform.resize(image,(w,h,c))
images.append(image)
labels.append(index)
return np.asarray(images,dtype=np.float32),np.asarray(labels,dtype=np.int32)
#读取训练数据及测试数据
train_data,train_label = read_image(train_path)
test_data,test_label = read_image(test_path)
#打乱训练数据及测试数据
train_image_num = len(train_data)
train_image_index = np.arange(train_image_num)
np.random.shuffle(train_image_index)
train_data = train_data[train_image_index]
train_label = train_label[train_image_index]
test_image_num = len(test_data)
test_image_index = np.arange(test_image_num)
np.random.shuffle(test_image_index)
test_data = test_data[test_image_index]
test_label = test_label[test_image_index]
#搭建CNN
x = tf.placeholder(tf.float32,[None,w,h,c],name='x')
y_ = tf.placeholder(tf.int32,[None],name='y_')
def inference(input_tensor,train,regularizer):
#第一层:卷积层,过滤器的尺寸为5×5,深度为6,不使用全0补充,步长为1。
#尺寸变化:32×32×1->28×28×6
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable('weight',[5,5,c,6],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable('bias',[6],initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor,conv1_weights,strides=[1,1,1,1],padding='VALID')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
#第二层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
#尺寸变化:28×28×6->14×14×6
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#第三层:卷积层,过滤器的尺寸为5×5,深度为16,不使用全0补充,步长为1。
#尺寸变化:14×14×6->10×10×16
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable('weight',[5,5,6,16],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',[16],initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1,conv2_weights,strides=[1,1,1,1],padding='VALID')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
#第四层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
#尺寸变化:10×10×6->5×5×16
with tf.variable_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#将第四层池化层的输出转化为第五层全连接层的输入格式。第四层的输出为5×5×16的矩阵,然而第五层全连接层需要的输入格式
#为向量,所以我们需要把代表每张图片的尺寸为5×5×16的矩阵拉直成一个长度为5×5×16的向量。
#举例说,每次训练64张图片,那么第四层池化层的输出的size为(64,5,5,16),拉直为向量,nodes=5×5×16=400,尺寸size变为(64,400)
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped = tf.reshape(pool2,[-1,nodes])
#第五层:全连接层,nodes=5×5×16=400,400->120的全连接
#尺寸变化:比如一组训练样本为64,那么尺寸变化为64×400->64×120
#训练时,引入dropout,dropout在训练时会随机将部分节点的输出改为0,dropout可以避免过拟合问题。
#这和模型越简单越不容易过拟合思想一致,和正则化限制权重的大小,使得模型不能任意拟合训练数据中的随机噪声,以此达到避免过拟合思想一致。
#本文最后训练时没有采用dropout,dropout项传入参数设置成了False,因为训练和测试写在了一起没有分离,不过大家可以尝试。
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable('weight',[nodes,120],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc1_weights))
fc1_biases = tf.get_variable('bias',[120],initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_weights) + fc1_biases)
if train:
fc1 = tf.nn.dropout(fc1,0.5)
#第六层:全连接层,120->84的全连接
#尺寸变化:比如一组训练样本为64,那么尺寸变化为64×120->64×84
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable('weight',[120,84],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc2_weights))
fc2_biases = tf.get_variable('bias',[84],initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2 = tf.nn.relu(tf.matmul(fc1,fc2_weights) + fc2_biases)
if train:
fc2 = tf.nn.dropout(fc2,0.5)
#第七层:全连接层(近似表示),84->10的全连接
#尺寸变化:比如一组训练样本为64,那么尺寸变化为64×84->64×10。最后,64×10的矩阵经过softmax之后就得出了64张图片分类于每种数字的概率,
#即得到最后的分类结果。
with tf.variable_scope('layer7-fc3'):
fc3_weights = tf.get_variable('weight',[84,10],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc3_weights))
fc3_biases = tf.get_variable('bias',[10],initializer=tf.truncated_normal_initializer(stddev=0.1))
logit = tf.matmul(fc2,fc3_weights) + fc3_biases
return logit
#正则化,交叉熵,平均交叉熵,损失函数,最小化损失函数,预测和实际equal比较,tf.equal函数会得到True或False,
#accuracy首先将tf.equal比较得到的布尔值转为float型,即True转为1.,False转为0,最后求平均值,即一组样本的正确率。
#比如:一组5个样本,tf.equal比较为[True False True False False],转化为float型为[1. 0 1. 0 0],准确率为2./5=40%。
regularizer = tf.contrib.layers.l2_regularizer(0.001)
y = inference(x,False,regularizer)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=y_)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(y,1),tf.int32),y_)
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#每次获取batch_size个样本进行训练或测试
def get_batch(data,label,batch_size):
for start_index in range(0,len(data)-batch_size+1,batch_size):
slice_index = slice(start_index,start_index+batch_size)
yield data[slice_index],label[slice_index]
#创建Session会话
with tf.Session() as sess:
#初始化所有变量(权值,偏置等)
sess.run(tf.global_variables_initializer())
#将所有样本训练10次,每次训练中以64个为一组训练完所有样本。
#train_num可以设置大一些。
train_num = 10
batch_size = 64
for i in range(train_num):
train_loss,train_acc,batch_num = 0, 0, 0
for train_data_batch,train_label_batch in get_batch(train_data,train_label,batch_size):
_,err,acc = sess.run([train_op,loss,accuracy],feed_dict={x:train_data_batch,y_:train_label_batch})
train_loss+=err;train_acc+=acc;batch_num+=1
print("train loss:",train_loss/batch_num)
print("train acc:",train_acc/batch_num)
test_loss,test_acc,batch_num = 0, 0, 0
for test_data_batch,test_label_batch in get_batch(test_data,test_label,batch_size):
err,acc = sess.run([loss,accuracy],feed_dict={x:test_data_batch,y_:test_label_batch})
test_loss+=err;test_acc+=acc;batch_num+=1
print("test loss:",test_loss/batch_num)
print("test acc:",test_acc/batch_num)
















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









