








论文题目:《Wasserstein GAN》( 2017年收录于ICML )
1 背景
生成对抗网络GAN( General Adversarial Networks )诞生以来出现的 一些问题。问题核心在GAN的目标函数JS散度:
-
当判别器D训练得越好,生成器G的梯度消失越严重。
优化JS散度,相当于两个分布更加接近,让两个分布重叠的时候,可以达到“以假乱 真”。但是经过分析,两种分布重叠的概率很小。 也就是说,无论两种分布相距多远,JS 散度为一个常数,因此导致生成器的梯度近似为零,梯度消失。
-
梯度不稳定,多样性不足
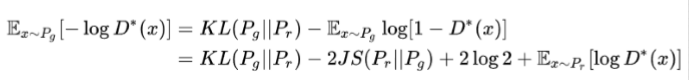
一是同时最小化生成分布与真实分布的KL散度,最大化JS散度,产生矛盾,造成 梯度不稳定;二是KL散度不是一个对称的衡量,通过分析可知,KL(Pg||Pr) 和 KL(Pr||Pg) 对不同的惩罚不一样,造成生成器G生成一些重复但是“安全”的样本,不愿生成多样性 的样本。
2 WGAN
提出Wasserstein 距离代替JS散度
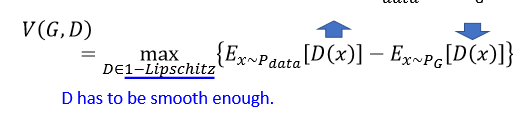

3 代码实现
计算损失:
real_x = tf.placeholder(tf.float32, shape=[batch_size, mnist_dim])
random_x = tf.placeholder(tf.float32, shape=[batch_size, random_dim])
random_y = Generator(random_x)
eps = tf.random_uniform([batch_size, 1], minval=0., maxval=1.)#
inter_x = eps * real_x + (1. - eps) * random_y
grad = tf.gradients(Discriminator(inter_x), [inter_x])[0]
grad_norm = tf.sqrt(tf.reduce_sum((grad)**2,axis = 1))
grad_pen = 10 * tf.reduce_mean(tf.nn.relu(grad_norm - 1.))
D_loss = tf.reduce_mean(Discriminator(random_y)) - tf.reduce_mean(Discriminator(real_x)) + grad_pen
G_loss = -tf.reduce_mean(Discriminator(random_y))
其中
tf.reduce_mean
reduce_mean(
input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None
)
#!/usr/bin/python
import tensorflow as tf
import numpy as np
initial = [[1.,1.],[2.,2.]]
x = tf.Variable(initial,dtype=tf.float32)
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print(sess.run(tf.reduce_mean(x)))
print(sess.run(tf.reduce_mean(x,0))) #Column
print(sess.run(tf.reduce_mean(x,1))) #row
ref
https://www.alexirpan.com/2017/02/22/wasserstein-gan.html
https://vincentherrmann.github.io/blog/wasserstein/
https://zhuanlan.zhihu.com/p/25071913















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









