









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种基于外部记忆的小样本学习算法,其思想也比较简单,首先提取支持集中图片的特征,并将其与对应了类别标签构成“键-值对”储存在记忆模块中,然后对查询集图片进行特征提取,并与从记忆模块中读取的特征信息进行比对,选择相似程度最高的作为查询图片的类别。在具体的实现过程中,作者设计了记忆模块的读写策略,并利用一个RNN模型为查询集特征提取网络生成权重,整个网络的结构如下图所示。

如图所示,查询集中的图片
x
n
x_n
xn经过一个特征提取网络之后,得到对应的特征信息
z
n
z_n
zn,再经过一个变化矩阵
T
z
T_z
Tz进行维度变换后得到
z
n
k
z^k_n
znk
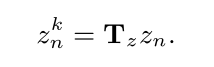
然后,要根据特征
z
n
k
z^k_n
znk与记忆模块中已经存储的其他特征信息之间的相似性,来决定
z
n
k
z^k_n
znk储存的位置,计算记忆模块中其他的特征信息与
z
n
k
z^k_n
znk的点乘积作为相似性,并选出最近邻
i
n
i_n
in,然后判断最近邻对应的值
m
i
n
v
m_{i_n}^v
minv(也就是对应的类别标签),与
z
n
k
z^k_n
znk对应的标签
y
n
y_n
yn是否相同,如果相同则按照下式的方式,更新最近邻
i
n
i_n
in对应的键
m
i
n
k
m_{i_n}^k
mink
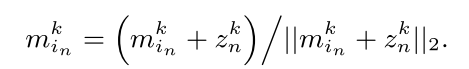
否则,就将
z
n
k
z^k_n
znk储存到一个新的记忆位置中去,如果记忆模块中没有新的空间可以储存了,那么就按上式的方法进行更新。再对新的查询样本进行预测时,就需要读取记忆模块中存储的特征信息,与单独的进行特征信息比对的方式不同,作者提出一种利用整体上下文信息(holistical contextual information)的方式。对于支持集中某个类别的图片
x
n
x_n
xn,其读取的特征信息不是简单的
z
n
z_n
zn或者
z
n
k
z^k_n
znk,而是先计算
z
n
k
z^k_n
znk与其他类别特征信息的点乘积相似性,并利用softmax函数将其转化为权重
a
i
,
n
a_{i,n}
ai,n,然后再利用该权重对记忆模块中的所有特征信息进行加权求和得到
c
n
c_n
cn,最后经过一个维度变换
T
c
T_c
Tc之后再与原特征信息
z
n
z_n
zn相加,计算过程如下
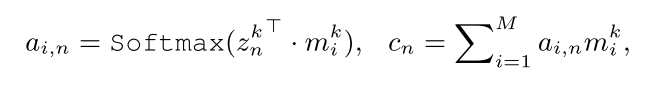
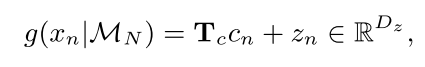
最后一步就是计算查询集图片对应的特征信息了,通常都是利用与支持集相同的网络,对查询集图像进行特征提取,但本文提出了一种叫做参数预测或者叫参数学习的方式,利用一个RNN网络对特征提取网络中卷积核的参数进行预测,而不是通过训练的方式去更新得到卷积核参数。这是因为作者认为由于训练样本较少,通过梯度下降法更新的权重值无法得到充足的训练,另一方面这一过程没用综合考虑所有类别的整体信息。因此,作者将记忆模块中储存的支持集的特征信息
M
N
\mathcal{M}_N
MN看作一个序列输入,并利用一个bi-LSTM网络作为上下文学习器
w
w
w,输出特征提取网络对应的卷积核参数
W
W
W
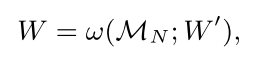
式中
W
′
W'
W′表示Bi-LSTM网络的权重参数。将查询集图片对应的特征信息
f
(
x
^
∣
M
N
)
f(\hat{x}|\mathcal{M}_N)
f(x^∣MN)与记忆模块中读取得到的支持集图片特征信息
g
(
x
n
∣
M
N
)
g(x_n|\mathcal{M}_N)
g(xn∣MN)进行点乘积计算,作为相似性得分,选择相似性得分最高的支持集图片对应的类别,作为查询图片的预测类别。
P
(
y
n
∣
x
^
,
M
N
)
=
f
(
x
^
∣
M
N
)
T
⋅
g
(
x
n
∣
M
N
)
P(y_n|\hat{x},\mathcal{M}_N)=f(\hat{x}|\mathcal{M}_N)^T\cdot g(x_n|\mathcal{M}_N)
P(yn∣x^,MN)=f(x^∣MN)T⋅g(xn∣MN)
实现过程
网络结构
文中没有具体介绍
损失函数
在给定支持集
S
\mathcal{S}
S和查询集
B
\mathcal{B}
B的条件下,采用sotfmax损失来度量
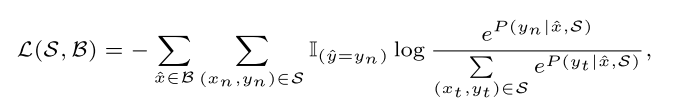
其中 P ( y n ∣ x ^ , S ) P(y_n|\hat{x},\mathcal{S}) P(yn∣x^,S)就是上文介绍的相似性得分。
创新点
- 采用外部记忆模块实现小样本学习任务,并设计了记忆读取和写入策略
- 利用bi-LSTM网络,根据记忆模块中存储的特征信息学习特征提取网络的卷积核参数
算法评价
本文应该是一篇非常具有特色的基于外部记忆的小样本学习文章,在记忆模块的读取方面都有创新性的设计,尤其是采用参数学习的方式,利用一个bi-LSTM网络去生成另外一个网络的权重,这个方式还是比较少见和新颖的。该方式比较类似于快权重的方式,就是权重值不通过SGD反复迭代更新的慢方式获得,而是直接利用另一个模型生成对应的权重,这在另一篇基于外部记忆的算法《Meta Networks》中也有过类似的应用。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。
















 3200
3200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











