









 本文提出了一种使用Transformer架构进行关键点匹配的算法,通过结合自注意力和跨注意力机制处理图像特征。算法包括特征提取、位置编码、Transformer编码解码以及多层感知机预测等步骤,并通过迭代聚焦方法提高匹配精度。对于尺度变化,通过循环一致性损失筛选共同可见部分,以适应不同尺度的图像。此外,还提出剔除误匹配点的策略,以提高匹配质量。实验表明,该方法在稀疏和稠密匹配任务中表现出色。
本文提出了一种使用Transformer架构进行关键点匹配的算法,通过结合自注意力和跨注意力机制处理图像特征。算法包括特征提取、位置编码、Transformer编码解码以及多层感知机预测等步骤,并通过迭代聚焦方法提高匹配精度。对于尺度变化,通过循环一致性损失筛选共同可见部分,以适应不同尺度的图像。此外,还提出剔除误匹配点的策略,以提高匹配质量。实验表明,该方法在稀疏和稠密匹配任务中表现出色。
核心思想
本文提出一种使用Transform实现关键点匹配的算法。传统的关键点匹配算法通常包含:关键点检测、特征描述、特征匹配、利用几何约束筛除误匹配点等步骤。本文则是采用深度学习中最新的Transformer技术,实现关键点的匹配任务。作者把关键点匹配任务看作通过最小化损失函数得到最佳参数的过程,,给定一幅图像
I
I
I和图像中待匹配的点坐标
x
x
x,从另一幅图像
I
′
I'
I′中寻找到对应的匹配点
x
′
x'
x′,损失函数的定义如下

其中
L
c
o
r
r
L_{corr}
Lcorr表示匹配损失,
L
c
y
c
l
e
L_{cycle}
Lcycle表示循环一致性损失,目标就是得到最优的参数函数
F
Φ
F_{\Phi}
FΦ。算法处理流程如下图所示
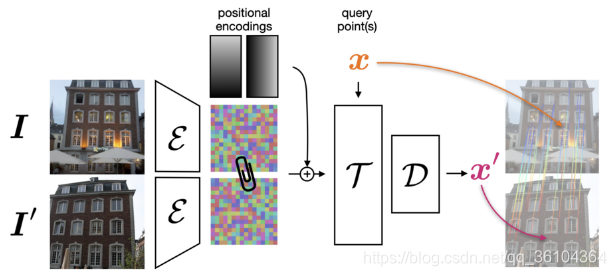
两个结构相同参数共享的特征提取网络
ε
\varepsilon
ε将图像下采样得到尺寸为16 * 16 * 256的特征图,将原图
I
I
I和目标图
I
′
I'
I′对应的特征图沿水平方向拼接起来,得到尺寸为16 * 32 *256的特征图,这样做的目的是让后面的Transformer编码过程能够建立起每幅图像内部(自注意力)和两幅图像之间的(跨注意力)位置关系。然后,对位置坐标进行线性编码,编码过程如下
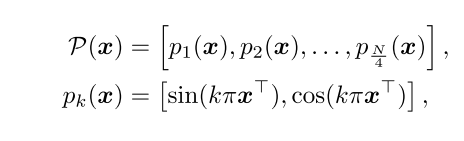
其中
x
=
[
x
,
y
]
\textbf{x}=[x,y]
x=[x,y]表示每个点的坐标,
N
N
N表示特征图通道数,本文取
N
=
256
N=256
N=256。因为
p
k
(
x
)
p_k(\textbf{x})
pk(x)包含四个值(
x
,
y
x,y
x,y分别对应两个值),因此位置坐标编码
P
(
x
)
P(\textbf{x})
P(x)的尺寸也为16 * 32 * 256,将位置坐标编码与拼接后的特征图相加,得到上下文特征图
c
c
c

将特征图
c
c
c输入到Transformer编码器
T
ε
T_{\varepsilon}
Tε中,并将编码结果
T
ε
(
c
)
T_{\varepsilon}(c)
Tε(c)和待匹配的点
x
x
x对应的编码值
P
(
x
)
P(x)
P(x)一起输入到Transformer解码器
T
D
T_{D}
TD中,最后将解码结果输入到一个多层感知机
D
D
D中得到最终的预测坐标值。
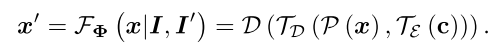
在前向计算过程中,由于Transformer计算成本较高,因此需要对图像进行严重的下采样,这使得匹配的准确性受到较大影响,为缓解这个问题,作者提出了一种迭代聚焦逐步优化的方法,如下图所示。
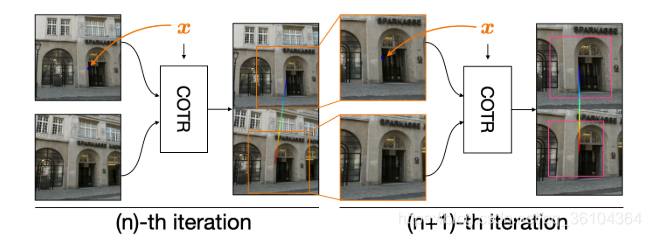
首先将原图进行下采样,并在下采样后的图像上进行匹配,以计算出来的匹配点位置坐标为中心,重新在原图上选取对应大小尺寸的图块,重新进行匹配。反复迭代,并且每次迭代图款尺寸都会缩小为原来的1/2,这样起到一种逐步聚焦的效果,得到更加精确的匹配结果。
对于尺度变化较大的匹配图像,作者认为尺度变化的比例应该和两幅图像之间共同可见部分的图像比例一致,如下图所示

作者认为近处拍摄宫殿(图1)相对于远处拍摄宫殿(图2)的放大比例,与两幅图之间的共同可见部分(图3和图4)之间的比例是一样的。为了补偿这个尺度变化,作者先对下采样后的原图进行一次匹配,并根据循环一致性损失值滤除掉两幅图之间不是共同可见的部分,得到图3和图4的效果。根据图3和图4中有效像素数目的比例,来调整从原图
I
I
I和目标图
I
′
I'
I′中选取的图块尺寸。
对于不同尺寸的图像,本文都将其变形为256 * 256大小输入到网络中,而由于使用了上文介绍的迭代聚焦逐步优化的方法,即使对于那些长宽比比较大的图像,本文仍能取得较好的匹配效果。
对于错误的匹配点(部分匹配点由于遮挡或者视野变化并不存在真实匹配点),本文选择将其筛除。筛选方法一方面是根据循环一致性损失,将循环一致性损失超过一定阈值的匹配点筛除;另一方面是将迭代聚焦过程中不能收敛的匹配点筛除。
对于稠密的匹配任务(每个点都要进行匹配,如立体匹配或光流估计任务),可以通过逐点匹配的方式或对稀疏匹配结果进行插值处理的方式完成,后者能够利用GPU更高效的实现。
实现过程
网络结构
特征提取网络采用ResNet-50网络,Transformer的编码解码器都包含6层网络,每个编码器层都包含一个8 heads的自注意力层;每个解码器都包含一个8 heads的编码解码注意力层,但没有自注意力层。多层感知机包含3个全连接层。
损失函数
训练策略
训练过程分为三个阶段,第一阶段冻结特征提取网络部分的参数(该部分参数已经在ImageNet数据集上进行预训练),只对剩余部分网络进行训练,共300k次迭代;然后对整个网络进行端到端的训练,共2M次迭代;最后采用上文介绍的迭代聚焦方法进行训练,共300次迭代。
算法推广
本文提出的算法可在稀疏匹配,稠密匹配,大基线立体匹配和光流估计等任务中取得SOTA的效果。
创新点
- 采用Transformer结构实现图像关键点的匹配过程,并将稀疏匹配和稠密匹配整合为一个参数优化的问题
- 提出了一种迭代聚焦,逐步优化的匹配方法
算法评价
本文较早的将Transformer技术引入到图像匹配的领域中,并且针对Transformer结构需要对图像进行多次下采样来降低计算量的问题,提出了迭代聚焦,逐步优化的方法,在保证计算速度的条件下,提高了匹配的精度。对于尺度变化较大的图像、尺寸不一致的图像以及误匹配点等问题也提出了相应的解决措施。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











