








Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的是自动驾驶领域中的3D占用预测问题。具体来说,它旨在通过构建一个紧凑的3D占用表示(Occupancy Representation),来提高对自动驾驶车辆周围环境的3D场景理解。这个问题的挑战在于:
-
现有的3D表示方法(如Tri-Perspective View, TPV)在压缩视图时会丢失3D几何信息。
-
原始的占用表示(Occupancy Representation, OCC)虽然能保留更多的几何信息,但是计算成本高,且由于其稀疏性,信息密度低,存在大量冗余。
-
现有的3D占用表示缺乏语义可区分性,这限制了网络成功识别稀有物体的能力,这部分是由于数据集中的类别不平衡问题导致的。
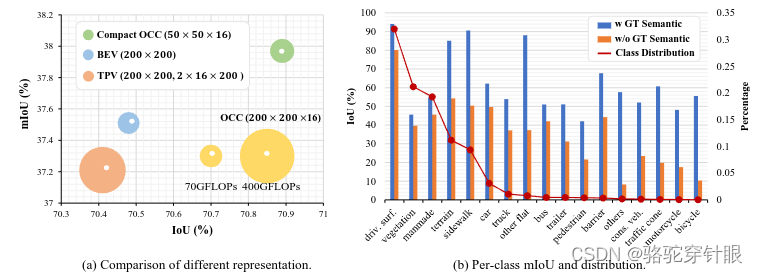
为了解决这些问题,论文提出了一种名为Compact Occupancy TRansformer(COTR)的方法,它包括一个几何感知的占用编码器和一个语义感知的组解码器,以重建一个紧凑的3D OCC表示。这种方法旨在保留丰富的几何信息,最小化计算成本,同时提高语义可区分性。通过实证实验,COTR在多个基线模型上显示出显著的性能提升,证明了该方法的优越性。
结构图
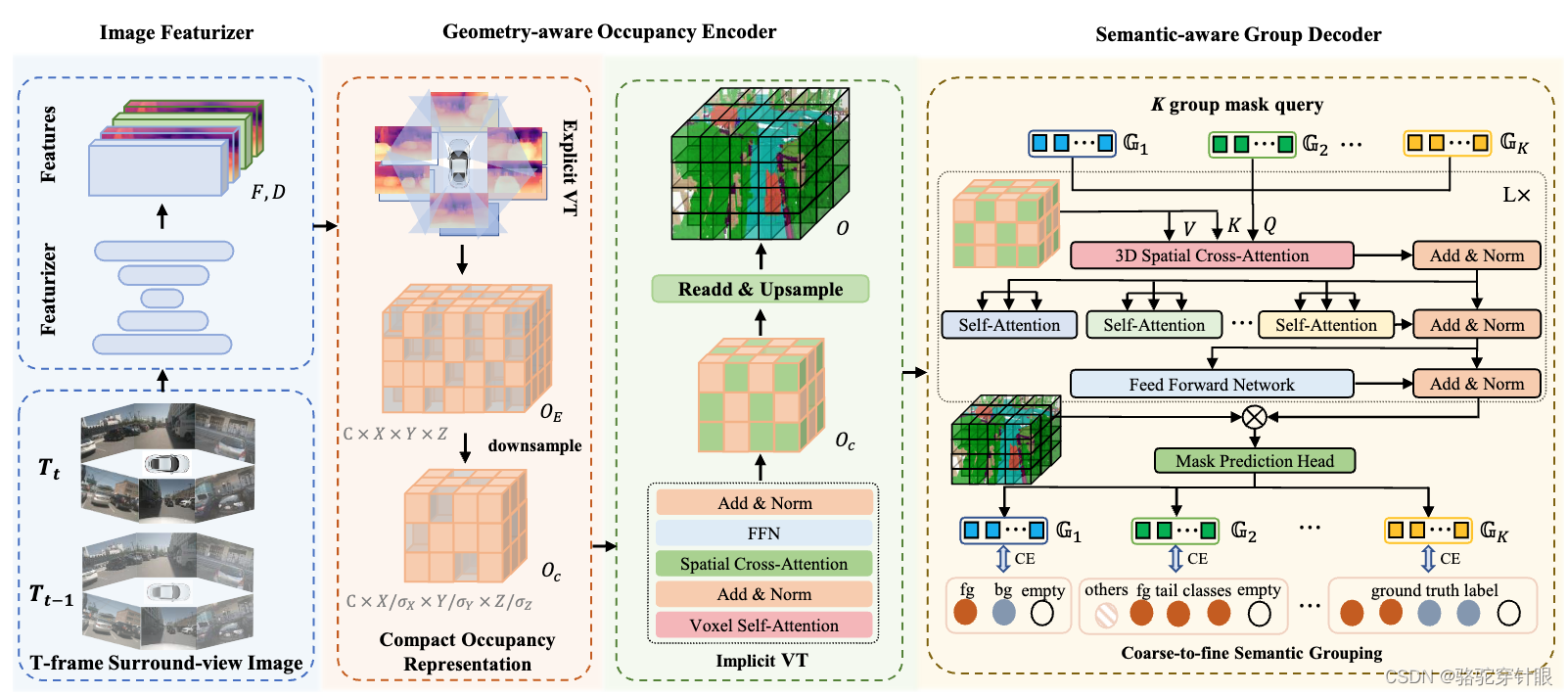
Q: 论文如何解决这个问题?
A: 论文提出了一种名为Compact Occupancy TRansformer(COTR)的方法来解决3D占用预测问题。COTR通过以下几个关键技术来解决现有方法的局限性:
- 几何感知的占用编码器(Geometry-aware Occupancy Encoder):该编码器使用显式-隐式视图转换(Explicit-Implicit View Transformation)来生成一个紧凑的几何感知的3D占用特征。首先,通过显式视图转换(EVT)生成一个稀疏但高分辨率的3D占用特征,然后将其下采样到一个紧凑的占用表示,该表示的大小仅为原始大小的1/16,同时没有性能损失。接着,隐式视图转换(IVT)通过空间交叉注意力和自注意力进一步丰富这个紧凑的特征。
通过特征提取image Feature 生成 F , 然后跟深度分布进行点乘 D
F ⊗ D F \otimes D F⊗D
计算得到伪点云
P ∈ R N c D b i n C × X × Y × Z P \in \mathbb{R}^{N_c D_{bin} C \times X \times Y \times Z } P∈RNcDbinC×X×Y×Z
通过体素化
O c ∈ R C × X σ x × Y σ y × Z σ z \ Oc \in R^{C \times \frac{X}{\sigma_x} \times \frac{Y}{\sigma_y} \times \frac{Z}{\sigma_z}} \ Oc∈RC×σx
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









