








文章目录
- StellarGraph教程之基于深度图卷积的监督式图: https://stellargraph.readthedocs.io/en/stable/demos/graph-classification/dgcnn-graph-classification.html
本笔记本演示了如何使用深度图卷积神经网络(DGCNN)[1]算法在有监督的环境中训练图分类模型。
在监督式图分类模型中,我们得到了一组图,每个图都附有分类标签。例如,我们在这个演示中使用的蛋白质数据集PROTEINS是一组图,每个图代表一种化合物,并标记为酶或非酶。我们的目标是训练一个机器学习模型,该模型使用数据的图形结构以及图形节点可用的任何信息,例如蛋白质中化合物的化学属性,以预测之前未看到的图形的正确标签;以前看不见的图是没有用于训练和验证模型的图。
DGCNN架构是在[1]中提出的(参见[1]中的图5),使用了[2]中的图卷积层,但修改了传播规则(详见[1])。DGCNN引入了一个新的SortPooling层,以通过图卷积层的堆栈为每个节点学习的表示作为输入,为每个给定的图生成表示(也称为嵌入)。然后,SortPooling层的输出被用作一维卷积、最大池化和密集层的输入,这些层学习适合于预测图标签的图级特征。
参考文献:
[1] An End-to-End Deep Learning Architecture for Graph Classification, M. Zhang, Z. Cui, M. Neumann, Y. Chen, AAAI-18. (link)
[2] Semi-supervised Classification with Graph Convolutional Networks, T. N. Kipf and M. Welling, ICLR 2017. (link)
import pandas as pd
import numpy as np
import stellargraph as sg
from stellargraph.mapper import PaddedGraphGenerator
from stellargraph.layer import DeepGraphCNN
from stellargraph import StellarGraph
from stellargraph import datasets
from sklearn import model_selection
from IPython.display import display, HTML
from tensorflow.keras import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import Dense, Conv1D, MaxPool1D, Dropout, Flatten
from tensorflow.keras.losses import binary_crossentropy
import tensorflow as tf
1. 导入数据(Import the data)
(有关如何加载数据的详细信息,请参阅“Loading from Pandas”演示。)
dataset = datasets.PROTEINS()
display(HTML(dataset.description))
graphs, graph_labels = dataset.load()
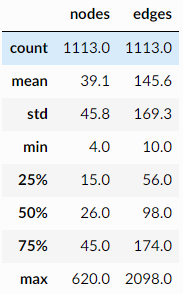
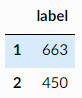
每个图表示一种蛋白质,图标签表示它们是酶还是非酶。该数据集包括1113个图,每个图平均有39个节点和73条边。图节点有4个属性(包括标签的一个热编码),每个图都被标记为属于2个类中的1个。【备注:TUDataset整理了超过120个用于图学习基准测试的数据集,https://github.com/chrsmrrs/tudataset】

graph的值是很多个StellarGraph实例构成的列表,其中每个图都有一些节点特征:
StellarGraph类的官方介绍: https://stellargraph.readthedocs.io/en/v0.8.2/api.html
用于无向图机器学习模型的StellarGraph类。它存储NetworkX Graph对象的图形信息以及用于机器学习的功能。
要创建一个准备好进行机器学习的StellarGraph对象,请至少将图结构作为NetworkX图传递给StellarGraph.
从pandas导入数据到StellarGraph类型: https://stellargraph.readthedocs.io/en/latest/demos/basics/loading-pandas.html
print(graphs[0].info())
StellarGraph: Undirected multigraph
Nodes: 42, Edges: 162
Node types:
default: [42]
Features: float32 vector, length 4
Edge types: default-default->default
Edge types:
default-default->default: [162]
Weights: all 1 (default)
Features: none
print(graphs[1].info())
StellarGraph: Undirected multigraph
Nodes: 27, Edges: 92
Node types:
default: [27]
Features: float32 vector, length 4
Edge types: default-default->default
Edge types:
default-default->default: [92]
Weights: all 1 (default)
Features: none
图大小的汇总统计信息表:
summary = pd.DataFrame(
[(g.number_of_nodes(), g.number_of_edges()) for g in graphs],
columns=["nodes", "edges"],
)
summary.describe().round(1)
Graph的标签是1或者2:
graph_labels.value_counts().to_frame()
对图片标签进行独热编码:
graph_labels = pd.get_dummies(graph_labels, drop_first=True)
2. 准备图生成器(Prepare graph generator)
为了将数据馈送到我们稍后将创建的tf.Keras模型,我们需要一个数据生成器。对于监督式图分类,我们创建了StellarGraph的PaddedGraphGenerator类的一个实例。
PaddedGraphGenerator的源代码参考: https://stellargraph.readthedocs.io/en/v1.2.0/_modules/stellargraph/mapper/padded_graph_generator.html
PaddedGraphGenerator是一个用于图分类算法的数据生成器。
提供的图应该是
StellarGraph类型的对象,并且具有节点特征。PaddedGraphGenerator使用flow方法提供graph的索引和(可选择的)目标,来得到一个可以作为Keras数据生成器的对象。这个生成器为一个小批次的“Keras”图分类模型提供特征数组和邻接矩阵。节点数量的差异是通过每个填充每个批次的特征和邻接矩阵来获得,通过提供布尔掩码来表明哪些是有效的,哪些是填充的。
enerator = PaddedGraphGenerator(graphs=graphs)
3. 创建Kereas图分类模型(Create the Keras graph classification model)
现在,我们已经准备好使用StellarGraph的DeepGraphCNN类以及标准的tf.Keras层Conv1D、MapPool1D、Dropout和Dense来创建一个tf.Keras图分类模型。
模型的输入是由其邻接矩阵和节点特征矩阵表示的图。前四层是图卷积的,如[2]所示,但使用[1]中的邻接归一化矩阵
D
−
1
A
D^{−1}A
D−1A,其中
A
A
A是具有自循环的邻接矩阵,
D
D
D是相应的度矩阵。图卷积层每个具有
32
32
32、
32
32
32、
32
32
32,
1
1
1个单元和tanh激活函数。
下一层是一维卷积层Conv1D,后面是最大池化层MaxPool1D。接下来是第二个Conv1D层,后面是两个Dense层,其中第二个用于二进制分类。卷积层和致密层使用relu激活函数,除了最后一个使用sigmoid进行分类的致密层。如[1]中所述,我们在第一个致密层之后添加一个Dropout层。
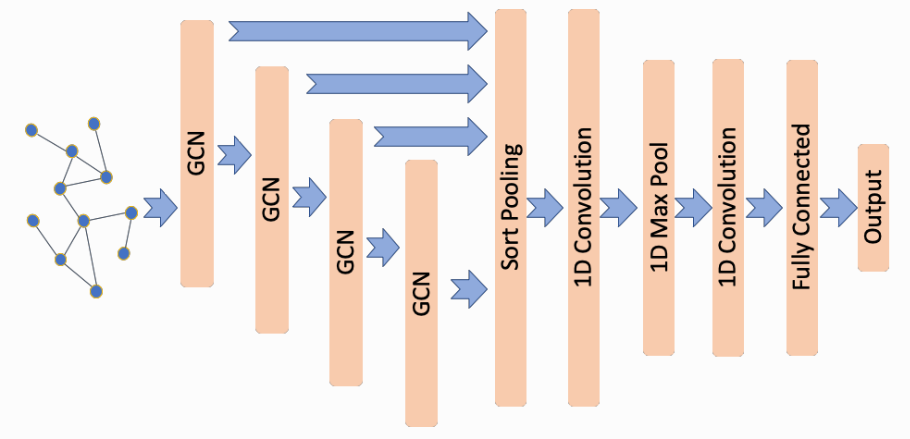
论文中关于Deep Graph Convolutional Neural Network (DGCNN)的介绍:
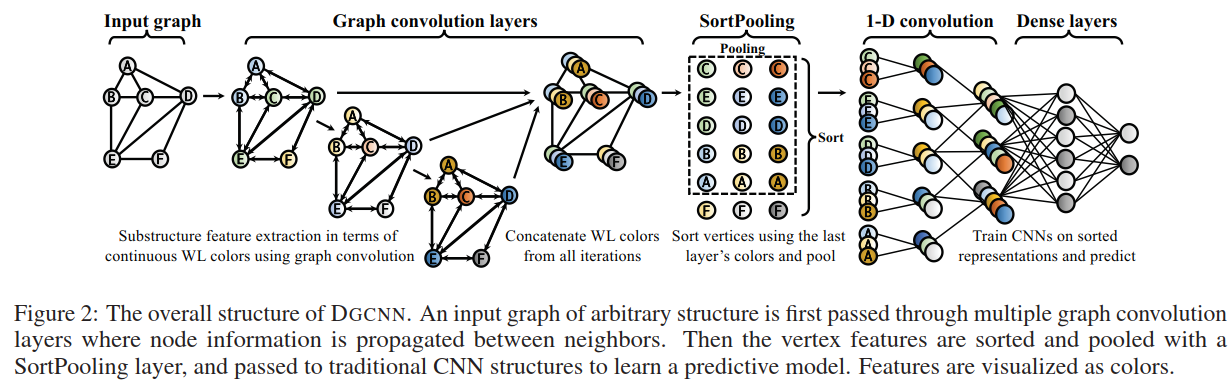
深度图卷积神经网络(DGCNN)有三个连续阶段:
1)**图卷积层(graph convolution layers)**提取顶点的局部子结构特征,并定义一致的顶点排序;
2) SortPooling layer按照先前定义的顺序对顶点特征进行排序,并统一输入大小;
3) **传统的卷积和稠密层(traditional convolutional and dense layers)**读取排序后的图表示并进行预测。
首先,我们创建了包括图卷积层和SortPooling层的基本DGCNN模型。
DeepGraphCNN相关介绍参考: https://stellargraph.readthedocs.io/en/v1.2.1/api.html
DGCNN将堆叠的
GraphConvolution层与一个SortPooling层结合, 使用图卷积操作 (https://arxiv.org/abs/1609.02907)可实现非监督的图分类网络。DCGNN模型首次由M. Zhang等人提出。该模型最低限度地要求将GCN层大小指定为:与每个隐藏层的特征维度相对应的整数列表、每个隐藏层中的激活函数、生成器对象和
SortPooling层的输出节点数数目。要将此类用作Keras模型,应使用PaddedGraphGenerator类提供特征和预处理的邻接矩阵。
k = 35 # the number of rows for the output tensor
layer_sizes = [32, 32, 32, 1]
###DeepGraphCNN for a specialisation using SortPooling, 主要特点在于排序池化层。
dgcnn_model = DeepGraphCNN(
layer_sizes=layer_sizes,
activations=["tanh", "tanh", "tanh", "tanh"],
k=k,
bias=False,
generator=generator,
)
x_inp, x_out = dgcnn_model.in_out_tensors()
接下来,我们添加卷积层(convolution)、最大池化层(max pooling)和密集层(dense layers)。相关函数都Keras中的,可参考:
- Conv1D layer: 用于文本数据,只对宽度进行卷积,对高度不卷积。https://keras.io/api/layers/convolution_layers/convolution1d/
- MaxPooling1D layer: 通过在大小为
pool_size的空间窗口上取最大值来对输入表示进行下采样。https://keras.io/api/layers/pooling_layers/max_pooling1d/ - Dropout layer: 以某个频率
rate将输入单元设置为0, 从而帮助避免过拟合(overfitting)。https://keras.io/api/layers/regularization_layers/dropout/ - Dense layer: 通过
output = activation(dot(input, kernel) + bias)操作实现。Dense层的目的是将前面提取的特征,在Dense层经过特征变换后,提取这些特征之间的关联,最后映射到输出空间上。https://keras.io/api/layers/core_layers/dense/
x_out = Conv1D(filters=16, kernel_size=sum(layer_sizes), strides=sum(layer_sizes))(x_out)
x_out = MaxPool1D(pool_size=2)(x_out)
x_out = Conv1D(filters=32, kernel_size=5, strides=1)(x_out)
x_out = Flatten()(x_out)
x_out = Dense(units=128, activation="relu")(x_out)
x_out = Dropout(rate=0.5)(x_out)
predictions = Dense(units=1, activation="sigmoid")(x_out)
最后,我们创建Keras模型,并通过指定损失和优化算法为其进行训练做好准备。
model = Model(inputs=x_inp, outputs=predictions)
model.compile(
optimizer=Adam(lr=0.0001), loss=binary_crossentropy, metrics=["acc"],
)
4. 训练模型(Train the model)
我们现在可以使用模型的拟合fit方法来训练模型。
但首先我们需要将数据拆分为训练集和测试集(使用sklearn.model_selection.train_test_split进行训练集和测试集划分)。我们将使用90%的数据进行训练,其余10%用于测试。这种90\10的划分相当于[1]中使用的10折交叉验证方案中的一折。
train_graphs, test_graphs = model_selection.train_test_split(
graph_labels, train_size=0.9, test_size=None, stratify=graph_labels,
)
考虑到数据分为训练集和测试集,我们创建了一个StellarGraph.PaddedGenerator生成器对象,该对象为训练准备数据。我们通过调用指定训练和测试数据的后一个生成器的flow方法,创建适合在tf.keras模型中训练的数据生成器。
gen = PaddedGraphGenerator(graphs=graphs)
train_gen = gen.flow(
list(train_graphs.index - 1),
targets=train_graphs.values,
batch_size=50,
symmetric_normalization=False,
)
test_gen = gen.flow(
list(test_graphs.index - 1),
targets=test_graphs.values,
batch_size=1,
symmetric_normalization=False,
)
注意:我们将epochs的数量设置为一个大值,因此稍后对model.fit(…)的调用可能需要很长时间才能完成。为了获得更快的性能,将epochs设置为较小的值;但如果你这样做,发现模型的准确性可能会很低。
epochs = 100
我们现在可以通过调用它的拟合方法fit来训练模型。
history = model.fit(
train_gen, epochs=epochs, verbose=1, validation_data=test_gen, shuffle=True,
)
[‘…’]
[‘…’]
Train for 21 steps, validate for 112 steps
Epoch 1/100
21/21 [] - 3s 139ms/step - loss: 0.6640 - acc: 0.5824 - val_loss: 0.6188 - val_acc: 0.5982
Epoch 2/100
21/21 [] - 2s 74ms/step - loss: 0.6526 - acc: 0.6234 - val_loss: 0.6003 - val_acc: 0.6429
Epoch 3/100
21/21 [] - 2s 86ms/step - loss: 0.6468 - acc: 0.6643 - val_loss: 0.5987 - val_acc: 0.7411
Epoch 4/100
21/21 [] - 2s 76ms/step - loss: 0.6361 - acc: 0.7123 - val_loss: 0.5843 - val_acc: 0.7321
Epoch 5/100
21/21 [] - 2s 83ms/step - loss: 0.6301 - acc: 0.7143 - val_loss: 0.5786 - val_acc: 0.7500
Epoch 6/100
21/21 [] - 2s 86ms/step - loss: 0.6061 - acc: 0.7073 - val_loss: 0.5716 - val_acc: 0.7500
Epoch 7/100
21/21 [] - 2s 81ms/step - loss: 0.6129 - acc: 0.7173 - val_loss: 0.5626 - val_acc: 0.7500
Epoch 8/100
21/21 [] - 2s 82ms/step - loss: 0.6274 - acc: 0.7163 - val_loss: 0.5637 - val_acc: 0.7411
Epoch 9/100
21/21 [] - 2s 84ms/step - loss: 0.5985 - acc: 0.7243 - val_loss: 0.5606 - val_acc: 0.7411
Epoch 10/100
21/21 [] - 2s 86ms/step - loss: 0.6066 - acc: 0.7223 - val_loss: 0.5568 - val_acc: 0.7411
Epoch 11/100
21/21 [] - 2s 82ms/step - loss: 0.5956 - acc: 0.7273 - val_loss: 0.5530 - val_acc: 0.7411
Epoch 12/100
21/21 [] - 2s 75ms/step - loss: 0.5852 - acc: 0.7203 - val_loss: 0.5493 - val_acc: 0.7500
Epoch 13/100
21/21 [] - 2s 81ms/step - loss: 0.5995 - acc: 0.7233 - val_loss: 0.5482 - val_acc: 0.7500
Epoch 14/100
21/21 [] - 2s 89ms/step - loss: 0.5898 - acc: 0.7303 - val_loss: 0.5452 - val_acc: 0.7411
Epoch 15/100
21/21 [] - 2s 88ms/step - loss: 0.6028 - acc: 0.7233 - val_loss: 0.5467 - val_acc: 0.7589
Epoch 16/100
21/21 [] - 2s 84ms/step - loss: 0.5850 - acc: 0.7223 - val_loss: 0.5444 - val_acc: 0.7500
Epoch 17/100
21/21 [] - 2s 80ms/step - loss: 0.5793 - acc: 0.7243 - val_loss: 0.5436 - val_acc: 0.7589
Epoch 18/100
21/21 [] - 2s 87ms/step - loss: 0.5705 - acc: 0.7133 - val_loss: 0.5413 - val_acc: 0.7500
Epoch 19/100
21/21 [] - 2s 78ms/step - loss: 0.5829 - acc: 0.7263 - val_loss: 0.5426 - val_acc: 0.7411
Epoch 20/100
21/21 [] - 2s 88ms/step - loss: 0.5796 - acc: 0.7133 - val_loss: 0.5423 - val_acc: 0.7411
Epoch 21/100
21/21 [] - 2s 93ms/step - loss: 0.5772 - acc: 0.7053 - val_loss: 0.5397 - val_acc: 0.7321
Epoch 22/100
21/21 [] - 2s 79ms/step - loss: 0.5818 - acc: 0.7143 - val_loss: 0.5378 - val_acc: 0.7500
Epoch 23/100
21/21 [] - 2s 86ms/step - loss: 0.5733 - acc: 0.7133 - val_loss: 0.5381 - val_acc: 0.7321
Epoch 24/100
21/21 [] - 2s 85ms/step - loss: 0.5670 - acc: 0.7143 - val_loss: 0.5390 - val_acc: 0.7321
Epoch 25/100
21/21 [] - 2s 81ms/step - loss: 0.5688 - acc: 0.7143 - val_loss: 0.5374 - val_acc: 0.7321
Epoch 26/100
21/21 [] - 2s 86ms/step - loss: 0.5671 - acc: 0.7103 - val_loss: 0.5372 - val_acc: 0.7232
Epoch 27/100
21/21 [] - 2s 89ms/step - loss: 0.5639 - acc: 0.7103 - val_loss: 0.5362 - val_acc: 0.7232
Epoch 28/100
21/21 [] - 2s 96ms/step - loss: 0.5732 - acc: 0.7143 - val_loss: 0.5377 - val_acc: 0.7321
Epoch 29/100
21/21 [] - 2s 86ms/step - loss: 0.5655 - acc: 0.7073 - val_loss: 0.5363 - val_acc: 0.7232
Epoch 30/100
21/21 [] - 2s 82ms/step - loss: 0.5683 - acc: 0.7153 - val_loss: 0.5366 - val_acc: 0.7321
Epoch 31/100
21/21 [] - 2s 84ms/step - loss: 0.5752 - acc: 0.7203 - val_loss: 0.5345 - val_acc: 0.7232
Epoch 32/100
21/21 [] - 2s 96ms/step - loss: 0.5778 - acc: 0.7183 - val_loss: 0.5392 - val_acc: 0.7321
Epoch 33/100
21/21 [] - 2s 90ms/step - loss: 0.5649 - acc: 0.7253 - val_loss: 0.5352 - val_acc: 0.7500
Epoch 34/100
21/21 [] - 2s 87ms/step - loss: 0.5700 - acc: 0.7153 - val_loss: 0.5337 - val_acc: 0.7321
Epoch 35/100
21/21 [] - 2s 74ms/step - loss: 0.5621 - acc: 0.7083 - val_loss: 0.5358 - val_acc: 0.7411
Epoch 36/100
21/21 [] - 2s 83ms/step - loss: 0.5729 - acc: 0.7273 - val_loss: 0.5371 - val_acc: 0.7232
Epoch 37/100
21/21 [] - 2s 84ms/step - loss: 0.5735 - acc: 0.7153 - val_loss: 0.5316 - val_acc: 0.7321
Epoch 38/100
21/21 [] - 2s 92ms/step - loss: 0.5694 - acc: 0.7043 - val_loss: 0.5309 - val_acc: 0.7411
Epoch 39/100
21/21 [] - 2s 88ms/step - loss: 0.5589 - acc: 0.7173 - val_loss: 0.5315 - val_acc: 0.7411
Epoch 40/100
21/21 [] - 2s 89ms/step - loss: 0.5687 - acc: 0.7163 - val_loss: 0.5314 - val_acc: 0.7321
Epoch 41/100
21/21 [] - ETA: 0s - loss: 0.5534 - acc: 0.728 - 2s 86ms/step - loss: 0.5523 - acc: 0.7283 - val_loss: 0.5301 - val_acc: 0.7411
Epoch 42/100
21/21 [] - 2s 93ms/step - loss: 0.5596 - acc: 0.7113 - val_loss: 0.5306 - val_acc: 0.7411
Epoch 43/100
21/21 [] - 2s 90ms/step - loss: 0.5518 - acc: 0.7193 - val_loss: 0.5293 - val_acc: 0.7500
Epoch 44/100
21/21 [] - 2s 86ms/step - loss: 0.5579 - acc: 0.7153 - val_loss: 0.5299 - val_acc: 0.7500
Epoch 45/100
21/21 [] - 2s 82ms/step - loss: 0.5565 - acc: 0.7253 - val_loss: 0.5276 - val_acc: 0.7500
Epoch 46/100
21/21 [] - 2s 83ms/step - loss: 0.5576 - acc: 0.7113 - val_loss: 0.5294 - val_acc: 0.7500
Epoch 47/100
21/21 [] - 2s 83ms/step - loss: 0.5624 - acc: 0.7203 - val_loss: 0.5291 - val_acc: 0.7500
Epoch 48/100
21/21 [] - 2s 89ms/step - loss: 0.5552 - acc: 0.7223 - val_loss: 0.5268 - val_acc: 0.7500
Epoch 49/100
21/21 [] - 2s 90ms/step - loss: 0.5536 - acc: 0.7223 - val_loss: 0.5250 - val_acc: 0.7589
Epoch 50/100
21/21 [] - 2s 98ms/step - loss: 0.5693 - acc: 0.7153 - val_loss: 0.5281 - val_acc: 0.7589
Epoch 51/100
21/21 [] - 2s 90ms/step - loss: 0.5521 - acc: 0.7243 - val_loss: 0.5256 - val_acc: 0.7589
Epoch 52/100
21/21 [] - 2s 89ms/step - loss: 0.5536 - acc: 0.7203 - val_loss: 0.5217 - val_acc: 0.7589
Epoch 53/100
21/21 [] - 2s 93ms/step - loss: 0.5489 - acc: 0.7143 - val_loss: 0.5197 - val_acc: 0.7679
Epoch 54/100
21/21 [] - 2s 88ms/step - loss: 0.5478 - acc: 0.7283 - val_loss: 0.5211 - val_acc: 0.7679
Epoch 55/100
21/21 [] - 2s 90ms/step - loss: 0.5569 - acc: 0.7263 - val_loss: 0.5201 - val_acc: 0.7589
Epoch 56/100
21/21 [] - 2s 101ms/step - loss: 0.5530 - acc: 0.7183 - val_loss: 0.5204 - val_acc: 0.7857
Epoch 57/100
21/21 [] - 2s 91ms/step - loss: 0.5453 - acc: 0.7183 - val_loss: 0.5171 - val_acc: 0.7768
Epoch 58/100
21/21 [] - 2s 88ms/step - loss: 0.5390 - acc: 0.7303 - val_loss: 0.5161 - val_acc: 0.7857
Epoch 59/100
21/21 [] - 2s 90ms/step - loss: 0.5410 - acc: 0.7283 - val_loss: 0.5128 - val_acc: 0.7857
Epoch 60/100
21/21 [] - 2s 97ms/step - loss: 0.5602 - acc: 0.7213 - val_loss: 0.5173 - val_acc: 0.7679
Epoch 61/100
21/21 [] - 2s 90ms/step - loss: 0.5449 - acc: 0.7243 - val_loss: 0.5138 - val_acc: 0.7768
Epoch 62/100
21/21 [] - 2s 89ms/step - loss: 0.5492 - acc: 0.7243 - val_loss: 0.5125 - val_acc: 0.7768
Epoch 63/100
21/21 [] - 2s 84ms/step - loss: 0.5466 - acc: 0.7213 - val_loss: 0.5161 - val_acc: 0.7768
Epoch 64/100
21/21 [] - 2s 83ms/step - loss: 0.5475 - acc: 0.7213 - val_loss: 0.5135 - val_acc: 0.7768
Epoch 65/100
21/21 [] - 2s 86ms/step - loss: 0.5409 - acc: 0.7243 - val_loss: 0.5125 - val_acc: 0.7857
Epoch 66/100
21/21 [] - 2s 95ms/step - loss: 0.5404 - acc: 0.7303 - val_loss: 0.5095 - val_acc: 0.7857
Epoch 67/100
21/21 [] - 2s 85ms/step - loss: 0.5453 - acc: 0.7213 - val_loss: 0.5029 - val_acc: 0.7857
Epoch 68/100
21/21 [] - 2s 88ms/step - loss: 0.5374 - acc: 0.7293 - val_loss: 0.5086 - val_acc: 0.7768
Epoch 69/100
21/21 [] - 2s 97ms/step - loss: 0.5409 - acc: 0.7353 - val_loss: 0.5077 - val_acc: 0.7768
Epoch 70/100
21/21 [] - 2s 92ms/step - loss: 0.5439 - acc: 0.7293 - val_loss: 0.5043 - val_acc: 0.7857
Epoch 71/100
21/21 [] - 2s 90ms/step - loss: 0.5330 - acc: 0.7313 - val_loss: 0.5090 - val_acc: 0.7768
Epoch 72/100
21/21 [] - 2s 82ms/step - loss: 0.5328 - acc: 0.7303 - val_loss: 0.5092 - val_acc: 0.7768
Epoch 73/100
21/21 [] - 2s 84ms/step - loss: 0.5333 - acc: 0.7273 - val_loss: 0.5098 - val_acc: 0.7857
Epoch 74/100
21/21 [] - 2s 96ms/step - loss: 0.5384 - acc: 0.7313 - val_loss: 0.5049 - val_acc: 0.7679
Epoch 75/100
21/21 [] - 2s 83ms/step - loss: 0.5417 - acc: 0.7233 - val_loss: 0.5086 - val_acc: 0.7768
Epoch 76/100
21/21 [] - 2s 81ms/step - loss: 0.5364 - acc: 0.7253 - val_loss: 0.5088 - val_acc: 0.7589
Epoch 77/100
21/21 [] - 2s 89ms/step - loss: 0.5365 - acc: 0.7313 - val_loss: 0.5083 - val_acc: 0.7768
Epoch 78/100
21/21 [] - 2s 86ms/step - loss: 0.5378 - acc: 0.7363 - val_loss: 0.5084 - val_acc: 0.7679
Epoch 79/100
21/21 [] - 2s 86ms/step - loss: 0.5373 - acc: 0.7293 - val_loss: 0.5049 - val_acc: 0.7768
Epoch 80/100
21/21 [] - 2s 87ms/step - loss: 0.5344 - acc: 0.7373 - val_loss: 0.5063 - val_acc: 0.7679
Epoch 81/100
21/21 [] - 2s 87ms/step - loss: 0.5344 - acc: 0.7313 - val_loss: 0.5039 - val_acc: 0.7679
Epoch 82/100
21/21 [] - 2s 90ms/step - loss: 0.5304 - acc: 0.7363 - val_loss: 0.5078 - val_acc: 0.7589
Epoch 83/100
21/21 [] - 2s 93ms/step - loss: 0.5382 - acc: 0.7303 - val_loss: 0.5116 - val_acc: 0.7589
Epoch 84/100
21/21 [] - 2s 79ms/step - loss: 0.5315 - acc: 0.7293 - val_loss: 0.4988 - val_acc: 0.7500
Epoch 85/100
21/21 [] - 2s 91ms/step - loss: 0.5358 - acc: 0.7293 - val_loss: 0.4974 - val_acc: 0.7679
Epoch 86/100
21/21 [] - 2s 77ms/step - loss: 0.5424 - acc: 0.7283 - val_loss: 0.5009 - val_acc: 0.7679
Epoch 87/100
21/21 [] - 2s 88ms/step - loss: 0.5300 - acc: 0.7403 - val_loss: 0.5085 - val_acc: 0.7768
Epoch 88/100
21/21 [] - 2s 82ms/step - loss: 0.5436 - acc: 0.7253 - val_loss: 0.5046 - val_acc: 0.7500
Epoch 89/100
21/21 [] - 2s 90ms/step - loss: 0.5346 - acc: 0.7323 - val_loss: 0.5002 - val_acc: 0.7589
Epoch 90/100
21/21 [] - 2s 91ms/step - loss: 0.5323 - acc: 0.7373 - val_loss: 0.5056 - val_acc: 0.7679
Epoch 91/100
21/21 [] - 2s 93ms/step - loss: 0.5290 - acc: 0.7313 - val_loss: 0.5071 - val_acc: 0.7589
Epoch 92/100
21/21 [] - 2s 86ms/step - loss: 0.5340 - acc: 0.7313 - val_loss: 0.5086 - val_acc: 0.7679
Epoch 93/100
21/21 [] - 2s 98ms/step - loss: 0.5271 - acc: 0.7313 - val_loss: 0.5063 - val_acc: 0.7679
Epoch 94/100
21/21 [] - 2s 83ms/step - loss: 0.5236 - acc: 0.7413 - val_loss: 0.5102 - val_acc: 0.7679
Epoch 95/100
21/21 [] - 2s 86ms/step - loss: 0.5237 - acc: 0.7333 - val_loss: 0.5103 - val_acc: 0.7411
Epoch 96/100
21/21 [] - 2s 95ms/step - loss: 0.5196 - acc: 0.7353 - val_loss: 0.5110 - val_acc: 0.7768
Epoch 97/100
21/21 [] - 2s 94ms/step - loss: 0.5250 - acc: 0.7293 - val_loss: 0.5076 - val_acc: 0.7411
Epoch 98/100
21/21 [] - 2s 87ms/step - loss: 0.5259 - acc: 0.7403 - val_loss: 0.5087 - val_acc: 0.7679
Epoch 99/100
21/21 [] - 2s 99ms/step - loss: 0.5315 - acc: 0.7413 - val_loss: 0.5080 - val_acc: 0.7679
Epoch 100/100
21/21 [] - 2s 93ms/step - loss: 0.5292 - acc: 0.7313 - val_loss: 0.5223 - val_acc: 0.7589
接下来,让我们绘制训练历史(训练和测试数据的损失和准确性)。
sg.utils.plot_history(history)
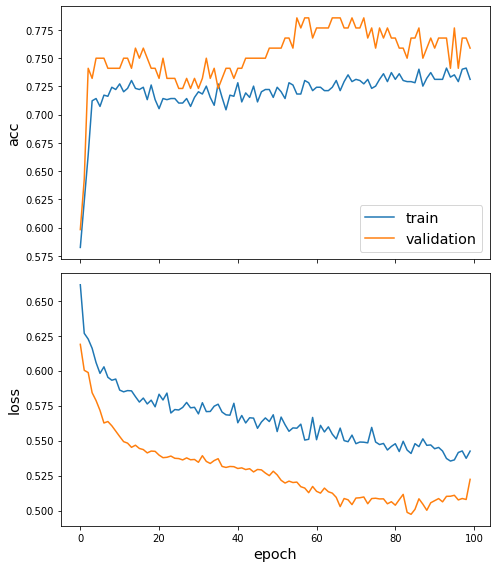
最后,让我们在测试数据上计算训练模型的性能。
test_metrics = model.evaluate(test_gen)
print("\nTest Set Metrics:")
for name, val in zip(model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
[‘…’]
112/112 [==============================] - 0s 1ms/step - loss: 0.5223 - acc: 0.7589
Test Set Metrics:
loss: 0.5223
acc: 0.7589
5.结论(Conclusion)
我们演示了将StellarGraph的DeepGraphCNN实现用于监督图分类算法。更具体地说,我们展示了如何预测以图形表示的化合物是否是酶。
性能与[1]中报告的性能相似,但确实存在微小差异。这种差异可归因于下面列出的少数因素,-我们使用了不同的训练方案,即对数据进行90/10的单一分割,而不是[1]中使用的重复10倍交叉验证方案。为了便于展示,我们使用了单一折叠。[1]中的实验评估方案没有指定一些重要的细节,例如:用于神经网络层的正则化;如果包含一个偏倚项;所使用的权重初始化方法;以及批量大小。















 4732
4732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









