






最近学习了3D gaussian splattoing的一些知识,也了解了一些Nerf的相关知识。之前一直做2d多模态的相关知识,对于3d处于刚刚接触的阶段,想着以新手的视角记录一下学习过程,一来加深自己的理解,二来想与各位讨论求教。由于水平实在有限,本篇文章就讲究一个浅尝辄止,如果这些笔记有幸能够启发到各位那就再好不过了。很长,大家慢慢看,有参考链接还是得看人家写的博客,比我的详细多了。
一. 计算机图形学前置知识
主要是恶补一些计算机图形学的知识,深度学习相关知识就不在这里介绍了。
1.1 点云数据(point cloud data):
三维坐标系统中的一组向量集合,每一个点包含三维坐标,可能包含颜色信息(RGB)或反射强度信息(Intensity,表示每个点云中点的反射、反射率、反射强度)。 本质上是3D空间中无序、无结构的海量数据点的集合。
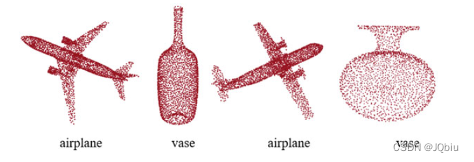
获取方式多种多样,在本文中主要会通过二维影像进行三维重建,在重建过程中获取点云数据。
对点云数据的处理有许多专门的工具框架,比如MATLAB中的LidarToolbox提供的3维点云可视化方法,以及Open3D等开源库提供的点云处理和分析功能。
1.2 三维几何表示
-
顶点表示(Vertex Represemtatopm):通过最简单和最基础的三维几何表示方法,通过一系列的顶点来定义物体的形状,每个顶点包含了其在三维空间中的坐标信息。通过连接这些顶点,可以形成线、面或体等几何形状。顶点表示适用于表示简单几何形状或离散的点云数据。
-
多边形网格表示(Polygon Mesh Representation):多边形网格是由连接顶点的边和面组成的结构。它是表示复杂几何形状的一种常见方法。多边形网格通常由三角形或四边形构成,但也可以包含更高阶的多边形。多边形网格可以表示平面几何形状,也可以通过三角剖分等技术表示曲面或复杂形状。
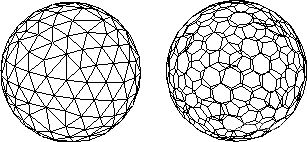
-
参数曲面表示(Parametric Surface Representation):参数曲面是通过参数化方程来表示的曲面。它使用参数化坐标(通常是二维参数)来描述曲面上的点。参数曲面可以通过数学函数或参数化曲线来生成,例如贝塞尔曲线和贝塞尔曲面。参数曲面表示适用于光滑的曲面和复杂的形状。
-
体素表示(Voxel Representation):体素是三维空间中的一个像素或体素元素,类似于二维图像中的像素。体素表示将三维空间划分为规则的体素网格,并使用每个体素的属性(如密度、颜色)来表示物体的形状和属性。体素表示适用于体积数据和体绘制应用,例如医学图像和体渲染
本文所涉及到的Nerf和3D Guassia splatting主要是使用体素进行三维几何表示。
1.3 渲染:
图像渲染是将三维场景转换为二维图像的过程。它是计算机图形学领域的一个重要任务,用于生成逼真的图像,以便在计算机屏幕上显示或进行进一步的图像处理。
光栅化(Rasterization):
找到所有被几何原型所占据的所有像素点然后逐个渲染这些点,得到图像的显示效果。光栅化渲染速度快,用于实时渲染,但渲染效果可能不如体渲染。
体渲染 (Volume Rendering):
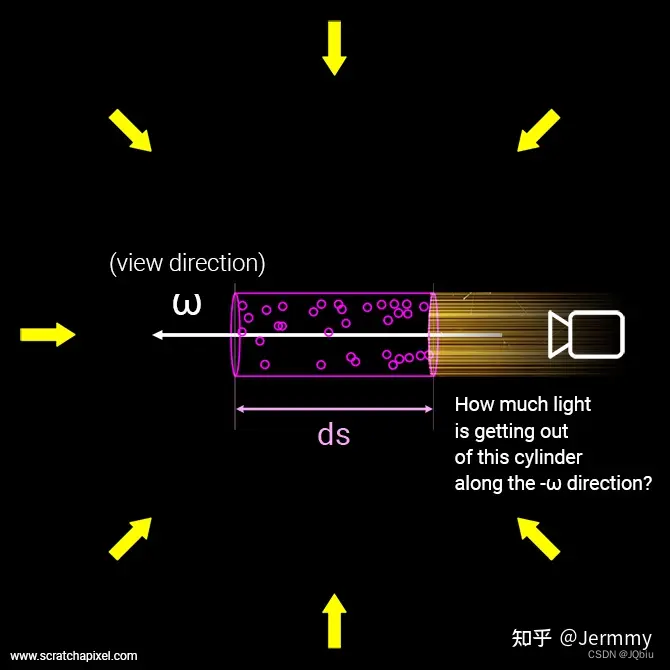
体渲染把气体等物质抽象成一团飘忽不定的粒子群。光线在穿过这类物体时,其实就是光子在跟粒子发生碰撞的过程。!
下图是体渲染建模的示意图。光沿直线方向穿过一堆粒子 (粉色部分),如果能计算出每根光线从最开始发射,到最终打到成像平面上的辐射强度(Nerf中其实可以理解为颜色),我们就可以渲染出投影图像。而体渲染要做的,就是对这个过程进行建模。为了简化计算,我们就假设光子只跟它附近的粒子发生作用,这个范围就是图中圆柱体大小的区间
此外还有线段技术渲染,图元技术渲染等等,因为Nerf和3d Gaussian splatting用到的渲染技术为体渲染和光栅化,本文暂不探究其他渲染技术。
关于光栅化,推荐博客(推荐顺序阅读):
1. https://zhuanlan.zhihu.com/p/449289345
2. https://zhuanlan.zhihu.com/p/450540827
关于体渲染,推荐博客:https://zhuanlan.zhihu.com/p/595117334
光照模型
光照模型是计算机图形学中用于模拟光线在三维场景中的传播和相互作用的模型。它们用于计算物体表面的颜色和亮度,以生成逼真的渲染结果。光照模型通常考虑光源、材质和表面法线等因素,以模拟光线在物体表面的反射、折射和散射等物理现象。
ps: 不清楚这一块是否和我们的主题有关系,暂时不提,需要再详细研究叭
1.4 相机内参和外参
相机内参通常包括焦距(fx, fy)、主点坐标(cx, cy)和像素尺寸(dw, dh)等参数,这些参数描述了相机内部的光学特性,对于理解和控制图像的形成至关重要
相机外参则包括相机的位置和姿态,通常通过相机的内参和一些附加的信息(如相机的镜头畸变系数)来估计。外参的主要作用是将相机坐标系下的点云(即相机捕获的三维空间中的点)转换到世界坐标系下
在3D Gaussia splatting中,相机的内参和外参被用来将点云投影到图像平面上,这一步叫做splatting。在此过程中,相机的内参帮助我们理解和控制图像的形成,而相机的外参则帮助我们将三维空间中的点映射到图像平面上。
关于这一部分的具体内容可以参考博客: https://blog.csdn.net/qq_43742590/article/details/104109103?spm=1001.2014.3001.5506
二. 核心前置知识
2.1 Nerf的简单总结
这篇文章的重头戏可能还是3D guassia splatting,所以简单总结一下Nerf吧:
NERF(Neural Radiance Fields)是一种基于神经网络的三维场景重建和渲染方法,它能够从有限的观测数据中推断出场景的几何形状和光照信息。以下是对NERF的总结:
- 原理:NERF使用神经网络来建模场景中每个点的辐射强度和颜色。它通过训练一个深度神经网络来学习表示场景的隐式函数,该函数将场景中的三维坐标和视线方向映射到对应点处的辐射强度和颜色值。
- 数据收集:为了训练NERF模型,需要从不同视角拍摄一系列的图像和相机参数。通常使用相机阵列或运动相机来捕捉场景的多个视角。同时,每个视角下还需要获取对应的深度图或射线方向信息。
- 训练过程:通过最小化预测辐射强度和颜色的神经网络与真实观测值之间的差距,来训练NERF模型。这可以通过最小化渲染图像与真实图像之间的重建误差来实现。训练过程通常使用渐进渲染和蒙特卡洛采样技术来提高训练效率和稳定性。
- 重建和渲染:训练完成的NERF模型可以用于重建和渲染新的视角。通过在新的视角上沿射线方向对场景进行采样,并通过神经网络预测每个采样点的辐射强度和颜色,最终生成逼真的渲染结果。
有关于Nerf,可以查看博客:https://zhuanlan.zhihu.com/p/597579341
2.2 球谐函数
傅里叶级数
首先回顾一下傅里叶,通过傅里叶去类比球谐函数,任何一个二维函数都可以分解成为不同的正弦与余弦之和:
f ( x ) = a 0 + ∑ n = 1 + ∞ a n c o s n π l x + b n s i n n π l x f(x)=a_0+\sum_{n=1}^{+\infty}a_ncos\frac{n\pi}{l}x+b_nsin\frac{n\pi}{l}x f(x)=a0+n=1∑+∞ancoslnπx+bnsinlnπx
这里 c o s n π l x cos\frac{n\pi}{l}x coslnπx和 s i n n π l x sin\frac{n\pi}{l}x sinlnπx就叫作基函数,原则上来讲当 n − > + ∞ n->+\infty n−>+∞时,我们就可以完美拟合这个函数,即使只有有限个 n n n,我们也可以对这个函数进行近似。
f ( x ) ≈ a 0 + ∑ n = 1 i a n c o s n π l x + b n s i n n π l x f(x) \approx a_0+\sum_{n=1}^{i}a_ncos\frac{n\pi}{l}x+b_nsin\frac{n\pi}{l}x f(x)≈a0+n=1∑iancoslnπx+bnsinlnπx
球谐函数
这种基函数的思想其实在数学中很常见。
我们考虑一个有界,闭合的,平滑的曲面。
它可以用球面函数表示方法来表示
f
(
θ
,
ϕ
)
f(\theta,\phi)
f(θ,ϕ),这样一个函数同样可以有自己的基函数来组成。
它的基函数长这样:

这个就是球谐函数。球谐函数的推导比较复杂,而且是递推的,这里不做介绍,只列一些比较低阶的球谐函数的方程:
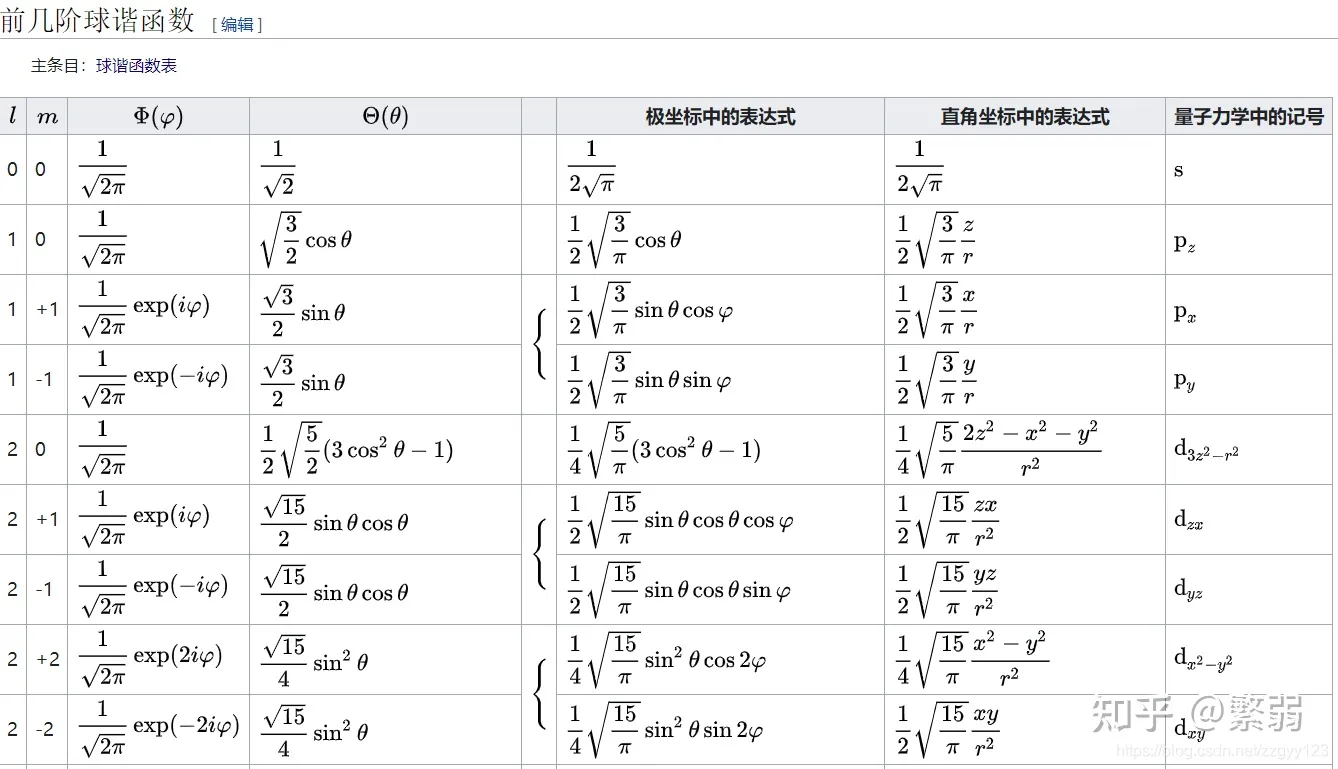
与傅里叶级数相似,任意一个球面坐标的函数,就可以用多个球谐函数来近似。
f ( θ , ϕ ) ≈ a 0 f l = 0 , m = 0 f ( θ , ϕ ) + a 1 f l = 1 , m = − 1 f ( θ , ϕ ) + a 2 f l = 1 , m = 0 f ( θ , ϕ ) + a 3 f l = 1 , m = 1 f ( θ , ϕ ) + a 4 f l = 2 , m = − 2 f ( θ , ϕ ) + a 5 f l = 2 , m = − 1 f ( θ , ϕ ) + . . . f(\theta,\phi) \approx a_0f_{l=0,m=0}f(\theta,\phi)+a_1f_{l=1,m=-1}f(\theta,\phi)+a_2f_{l=1,m=0}f(\theta,\phi)+a_3f_{l=1,m=1}f(\theta,\phi)+a_4f_{l=2,m=-2}f(\theta,\phi)+a_5f_{l=2,m=-1}f(\theta,\phi)+... f(θ,ϕ)≈a0fl=0,m=0f(θ,ϕ)+a1fl=1,m=−1f(θ,ϕ)+a2fl=1,m=0f(θ,ϕ)+a3fl=1,m=1f(θ,ϕ)+a4fl=2,m=−2f(θ,ϕ)+a5fl=2,m=−1f(θ,ϕ)+...

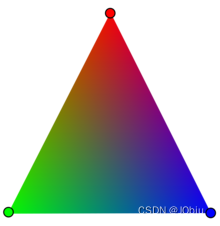
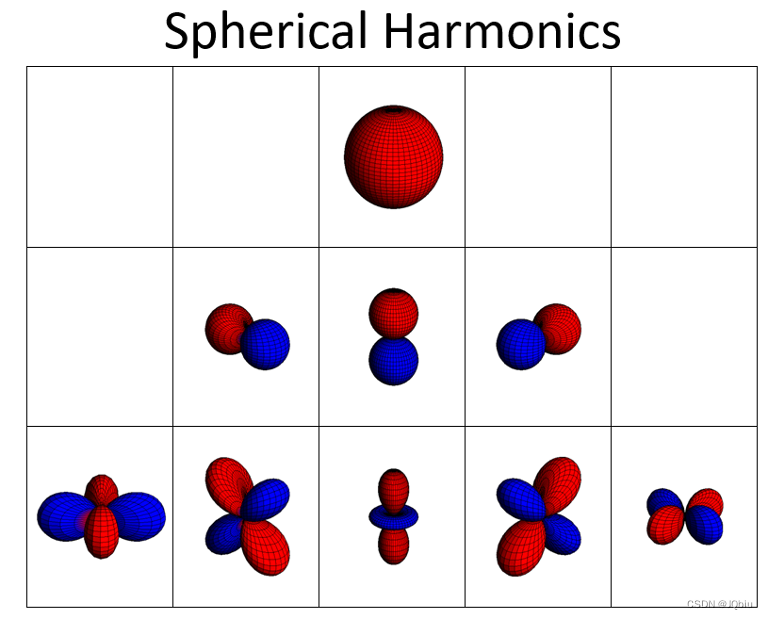
总而言之,球谐函数是一种在球面坐标系中表示函数的方法,可以用于表示物体的颜色信息。在渲染过程中,在渲染过程中,球谐函数通常用于估计物体的颜色,并根据对应的法线信息,从球谐函数中获取对应的颜色信息。要强调一下,在实际应用中,球谐函数的值可以作为颜色值,从光照的角度来说,就是表示光照的强度。这也是为什么球谐函数可以用于表示物体的颜色信息,特别是在光照效果复杂的情况下,如环境光、反射光等。最后附上一张彩色图片
2.3 图形学渲染
坐标变换
前面已经简单介绍过渲染的概念了。在图形学渲染中,坐标变换是非常关键的一部分,它涉及到从一个坐标系到另一个坐标系的转换,以便于在不同的坐标系中表示和操作图形元素。
简单来说,需要把空间里面的物体投影到相机的平面,也就是需要知道空间中每个点投影到特定相机平面上的位置是多少,在传统图形学里面的流程通常是这样的: 先把视椎内物体进行一个透视投影,压缩到一个非透视的空间内,然后使用正交投影,将视椎内物体压缩到各维度为[-1,1]的空间内。
这部分内容请参考博客:https://zhuanlan.zhihu.com/p/113662566
透视投影
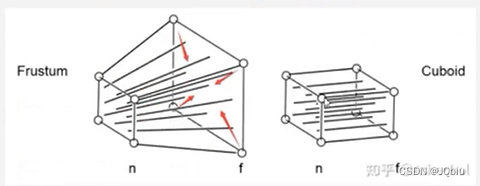
设近平面为
n
n
n,远平面为
f
f
f,这里假设我们相机坐标的位置如下(采用右手坐标系):
空间内任一点
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)投影到相机平面的位置为
(
x
′
,
y
′
,
z
′
)
(x',y',z')
(x′,y′,z′),投影矩阵为
P
P
P, 则有:
x
′
=
n
z
x
,
y
′
=
n
z
y
x'=\frac{n}{z}x,y'=\frac{n}{z}y
x′=znx,y′=zny
换成齐次坐标表示,也就是经过。
[
x
,
y
,
z
,
1
]
T
−
>
[
n
x
,
n
y
,
?
,
z
]
[x,y,z,1]^T->[nx,ny,?,z]
[x,y,z,1]T−>[nx,ny,?,z]
P = [ n 0 0 0 0 n 0 0 ? ? ? ? 0 0 1 0 ] P= \begin{bmatrix} n && 0 && 0 && 0\\ 0 && n && 0 && 0\\ ? && ? && ? && ?\\ 0 && 0 && 1 && 0 \end{bmatrix} P= n0?00n?000?100?0
我们还有两个约束条件,在近平面上,所有点的
z
z
z坐标不会变,都为
n
n
n,在远平面上,所有点的
z
z
z坐也不会变:
[
x
,
y
,
n
,
1
]
−
>
[
n
x
,
n
y
,
n
2
,
n
]
[x,y,n,1]->[nx,ny,n^2,n]
[x,y,n,1]−>[nx,ny,n2,n]
[
x
,
y
,
f
,
1
]
−
>
[
x
′
,
y
′
,
f
,
1
]
=
[
n
x
f
,
n
y
f
,
f
,
1
]
=
[
n
x
,
n
y
,
f
2
,
f
]
[x,y,f,1]->[x',y',f,1]=[\frac{nx}{f},\frac{ny}{f},f,1]=[nx,ny,f^2,f]
[x,y,f,1]−>[x′,y′,f,1]=[fnx,fny,f,1]=[nx,ny,f2,f]
所以
P
P
P一定满足如下的形式:
P = [ n 0 0 0 0 n 0 0 0 0 A B 0 0 1 0 ] P= \begin{bmatrix} n && 0 && 0 && 0\\ 0 && n && 0 && 0\\ 0 && 0 && A && B\\ 0 && 0 && 1 && 0 \end{bmatrix} P= n0000n0000A100B0
其中
A
n
+
B
=
n
2
An+B=n^2
An+B=n2,
A
f
+
B
=
f
2
Af+B=f^2
Af+B=f2
解出来为:
A
=
n
+
f
,
B
=
−
n
f
A=n+f, B=-nf
A=n+f,B=−nf
因此,投影距离为:
P = [ n 0 0 0 0 n 0 0 0 0 n + f − n f 0 0 1 0 ] P= \begin{bmatrix} n && 0 && 0 && 0\\ 0 && n && 0 && 0\\ 0 && 0 && n+f && -nf\\ 0 && 0 && 1 && 0 \end{bmatrix} P= n0000n0000n+f100−nf0
正交投影
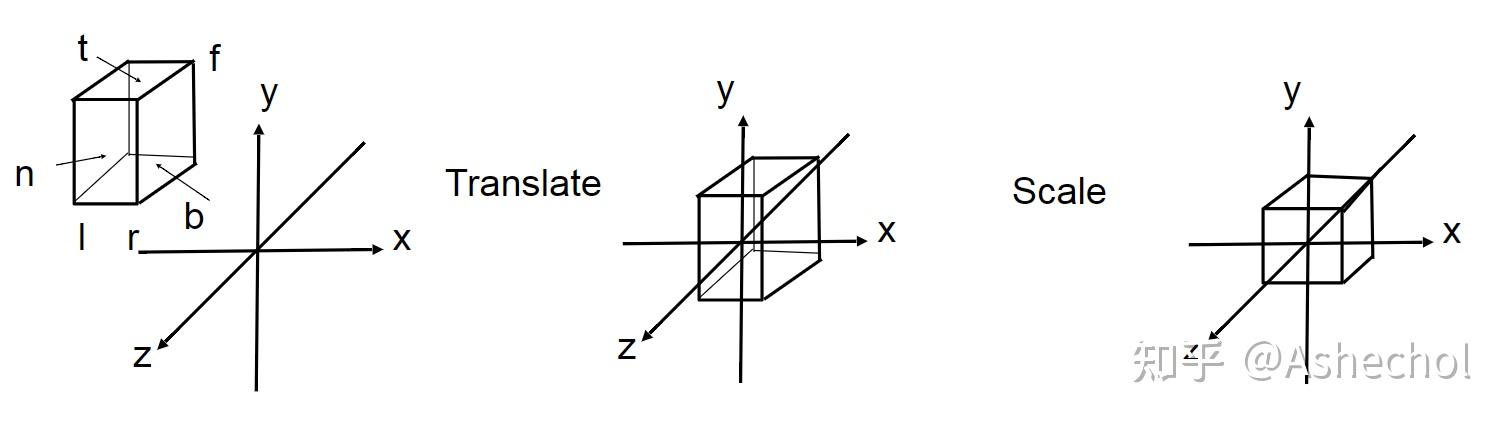
下交投影相对较简单,只需要将非透视空间内的内容挪到坐标原点,并规范化到[-1,1]的空间内,设x坐标的范围为[l,r],y坐标为[b,t],z坐标为[n,f], 我们可以先把坐标得到了零点,再做各个维度的压缩,从坐标到零点的变换矩阵为:
T 1 = [ 1 0 0 − l + r 2 0 1 0 − t + b 2 0 0 1 − n + f 2 0 0 0 1 ] T_1= \begin{bmatrix} 1 & 0 & 0 & -\frac{l+r}{2}\\ 0 & 1 & 0 & -\frac{t+b}{2}\\ 0 & 0 & 1 & -\frac{n+f}{2}\\ 0 & 0 & 0 & 1\\ \end{bmatrix} T1= 100001000010−2l+r−2t+b−2n+f1
缩放矩阵如下:
T 2 = [ 2 r − l 0 0 0 0 2 t − b 0 0 0 0 2 n − f 0 0 0 0 1 ] T_2= \begin{bmatrix} \frac{2}{r-l} & 0 & 0 & 0\\ 0 & \frac{2}{t-b} & 0 & 0\\ 0 & 0 & \frac{2}{n-f} & 0\\ 0 & 0 & 0 & 1\\ \end{bmatrix} T2= r−l20000t−b20000n−f200001
最后的矩阵就是两个矩阵乘起来:
T = T 2 T 1 = [ 2 r − l 0 0 − r + l r − l 0 2 t − b 0 − t + b t − b 0 0 2 n − f − n + f n − f 0 0 0 1 ] T=T_2T_1= \begin{bmatrix} \frac{2}{r-l} & 0 & 0 & -\frac{r+l}{r-l}\\ 0 & \frac{2}{t-b} & 0 & -\frac{t+b}{t-b}\\ 0 & 0 & \frac{2}{n-f} & -\frac{n+f}{n-f}\\ 0 & 0 & 0 & 1\\ \end{bmatrix} T=T2T1= r−l20000t−b20000n−f20−r−lr+l−t−bt+b−n−fn+f1
综合一下,将一个坐标先经过矩阵
P
P
P, 再过
T
T
T的变换就可以变到NDC坐标系。
可参考:https://www.bilibili.com/video/BV1dC4y1c7R8/?share_source=copy_web
2.4 3D Gaussia
一维高斯
公式为:
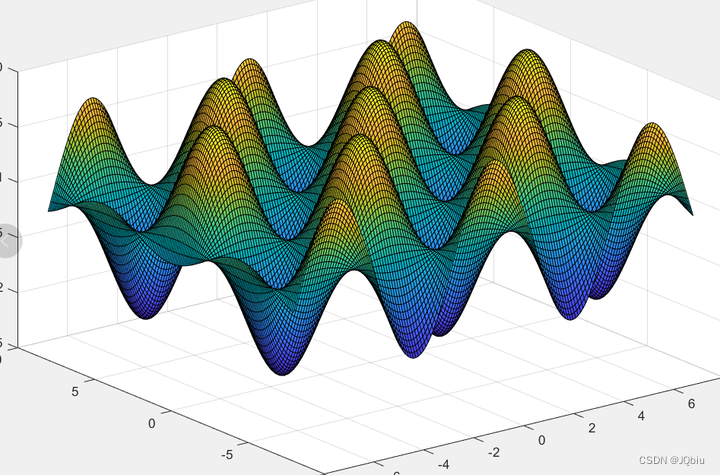
p ( x ) = 1 2 π σ e − ( x − u ) 2 2 σ 2 p(x)=\frac{1}{\sqrt {2 \pi}\sigma}e^{-\frac{(x-u)^2}{2 \sigma^2}} p(x)=2πσ1e−2σ2(x−u)2
其图像如下:

其均值为
u
u
u,方差为
σ
\sigma
σ,数据会以99%的概率落在
u
−
3
σ
u-3\sigma
u−3σ到
u
+
3
σ
u+3\sigma
u+3σ之中。
三维高斯
公式如下:
1 ( 2 π ) N 2 ∣ Σ ∣ e − 1 2 ( x − u ) T Σ − 1 ( x − u ) \frac{1}{(2 \pi)^{\frac{N}{2}}|\Sigma|}e^{-\frac{1}{2}(x-u)^T\Sigma^{-1} (x-u)} (2π)2N∣Σ∣1e−21(x−u)TΣ−1(x−u)
使用固定概率为 p p p的三维高斯窥探一下三维高斯分布分布长什么样。
1 ( 2 π ) N 2 ∣ Σ ∣ e − 1 2 ( x − u ) T Σ − 1 ( x − u ) = p \frac{1}{(2 \pi)^{\frac{N}{2}}|\Sigma|}e^{-\frac{1}{2}(x-u)^T\Sigma^{-1} (x-u)}=p (2π)2N∣Σ∣1e−21(x−u)TΣ−1(x−u)=p
− l n ( 2 π ) N 2 ∣ Σ ∣ − 1 2 ( x − u ) T Σ ( x − u ) = l n p -ln(2 \pi)^{\frac{N}{2}}|\Sigma|-\frac{1}{2}(x-u)^T\Sigma (x-u)=lnp −ln(2π)2N∣Σ∣−21(x−u)TΣ(x−u)=lnp
( x − u ) T Σ ( x − u ) = − 2 l n p − 2 l n ( 2 π ) N 2 ∣ Σ = C (x-u)^T\Sigma (x-u)=-2lnp-2ln(2 \pi)^{\frac{N}{2}}|\Sigma=C (x−u)TΣ(x−u)=−2lnp−2ln(2π)2N∣Σ=C
这里, Σ \Sigma Σ是一个实对称矩阵,令:
Σ = P T ∧ P \Sigma=P^T\wedge P Σ=PT∧P
( x − u ) T P T ∧ P ( x − u ) = ( P ( x − u ) ) T ∧ P ( x − u ) = C (x-u)^TP^T\wedge P(x-u)=(P(x-u))^T \wedge P(x-u)=C (x−u)TPT∧P(x−u)=(P(x−u))T∧P(x−u)=C
令:
y
=
P
(
x
−
u
)
y=P(x-u)
y=P(x−u),
令:
∧ = [ σ 1 2 0 0 0 σ 2 2 0 0 0 σ 3 2 ] \wedge= \begin{bmatrix} \sigma_1^2 & 0 & 0\\ 0 & \sigma_2^2 & 0 \\ 0 & 0 & \sigma_3^2 \end{bmatrix} ∧= σ12000σ22000σ32
原式子变为
y T ∧ y = σ 1 2 y 1 2 + σ 2 2 y 2 2 + σ 3 2 y 3 2 y^T \wedge y=\sigma_1^2y_1^2+\sigma_2^2y_2^2+\sigma_3^2y_3^2 yT∧y=σ12y12+σ22y22+σ32y32
这是一个标准的椭球的方程,所以原式子就是把标准椭球先经过经过一个旋转变换 P − 1 P^{-1} P−1,再挪到 u u u点得到。所以对于一个三维高斯而言,同一个椭球表面其概率密度相同,离 u u u越远,其概率越小。

所以一个多元高斯轴的长度为
Σ
\Sigma
Σ的特征值。
跟一维一样,有99%的概率落在3倍方差之内,也就是有99%的概率落在
3
σ
1
,
3
σ
2
,
3
σ
3
3\sigma_1,3\sigma_2,3\sigma_3
3σ1,3σ2,3σ3所在的椭球内,另外
σ
1
,
σ
2
,
σ
3
\sigma_1,\sigma_2,\sigma_3
σ1,σ2,σ3为
Σ
\Sigma
Σ的特征值。
相关知识可以参考:https://www.bilibili.com/video/BV1dC4y1c7R8/?share_source=copy_web
到此,了解了以上概念之后,就可以看看3D Gaussian splatting是什么东西了!
三. 3D Gaussian splatting
在开始3D Gaussian splatting之前,我们一起来再接触几个概念:
- SFM(Structure from Motion): 使一组照片可以合成新的视图,用于初始化3D高斯点云
- 抛雪球(splatting): 也被称为抛雪球法或足迹法,是一种用于处理三维数据的算法。它与光线投射法不同,是反复对体素的投影叠加效果进行运算
- 在Splatting中,每一个体素被视为一个模糊的球,投影到屏幕上。在Ray-cast中,我们计算出每个像素点受到每个体素影响的方式来生成最终图像。在Splatting中,我们计算出每个体素如何影响每个像素点
- Splatting方法的核心思想是将一组2d图像转换成点云,然后将点云变成3d空间中的椭球体,每个椭球体都拥有位置、大小和选择都经过优化颜色和不透明度。当这些椭球体混合在一起时,可以产生从任何角度渲染的完整模型的可视化效果
- 与光线投射法相比,抛雪球法的主要优点是速度较快。在光线投射中,要对沿光线的每个样本点(设共有k 个样本点) 进行重建,在每个样本点,要用k3 卷积过滤。平均来讲,即使n3 个体素的每一个只采样一次,光线投射至少有k3n3的时间复杂度。另一方面,在抛雪球法中,卷积被预计算,并且每个体素被准确溅射一次,每个抛雪球要求k2 次合成操作,所以,可望最多k2n3 的时间复杂度。这就使抛雪球法具有一个特有的速度优势。更多特点可以参考:https://blog.csdn.net/AYGdexiaotianxin/article/details/107225053
其实splatting基本就是3D Gaussia splatting 了。
万事具备,让我们快速了解一下什么是3D Gaussia splatting。
至于3D Gaussian splatting,首先推荐两篇博客,里面包含了3D Guassia的更详细的推导:https://blog.csdn.net/koukutou_mikiya/article/details/134834955
https://blog.csdn.net/su_zy_/article/details/134226262
3.1 3DGS流程
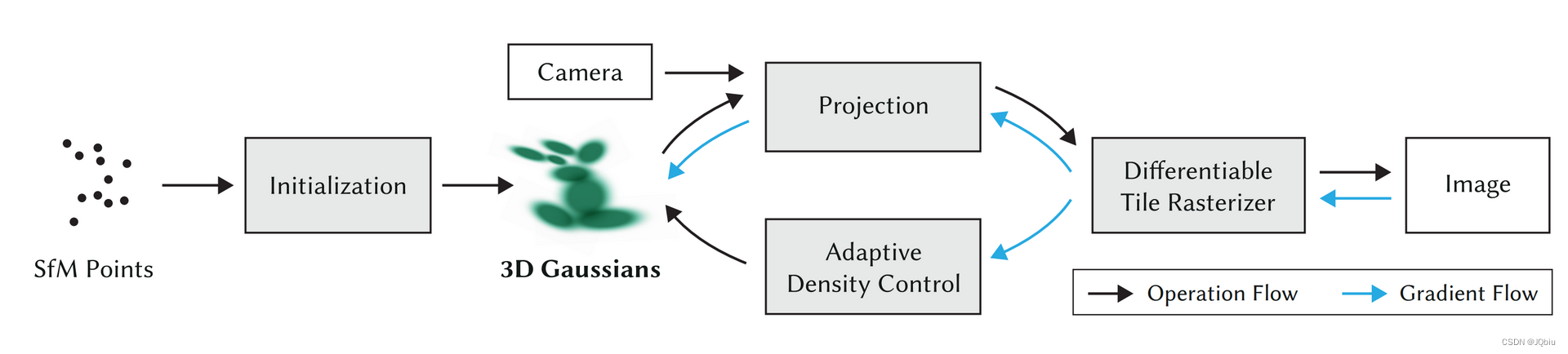
- 给一组照片,通过SFM对点云数据进行初始化
- 引入各向异的3D高斯分布,作为高质量、非结构化的辐射场表达。结合相机内参,进行透视投影。
3D高斯点云中储存了: 位置坐标、协方差矩阵、不透明度(用于spaltting)和球谐函数 (拟合视角相关外观) - 快速可微调光栅化
- 将整图划分为
16
×
16
16 \times 16
16×16 的tiles(不知道怎么翻译,个人理解就是视锥),从每个tiles视锥内挑选可视的3D Guassian
- 每个视锥内只取置信度>99%的高斯
- 设置一个保护带,剔除位于极端位置的高斯模型(如均值接近平面,或在视锥之外)
- 将高斯实例化为高斯对象(结合Gaussia所在tiles的ID和对应视域的深度,为其分配key值),且按照深度信息进行排序
- 并行地在tile上进行splat操作。
- 将排序号的Gaussias从近到远在对应的tile上做splatting,然后在每个tile上对高斯模型留下的splat做堆叠(类似与 α − b l e n d i n g \alpha -blending α−blending),累积透明度 α \alpha α和颜色 C C C,直到所有像素的不透明度都饱和,则停止操作( α = 1 \alpha = 1 α=1)
- PS: 再理解一下splat,传统的光栅化渲染管线只能够逐像素进行,将三角形(也有可能是正方形或者其他几何形状)网格分解为像素,并且经过颜色插值、深度测试等一系列像素处理步骤,最终将结果渲染在图像上。
- 将整图划分为
16
×
16
16 \times 16
16×16 的tiles(不知道怎么翻译,个人理解就是视锥),从每个tiles视锥内挑选可视的3D Guassian
- 梯度反向传播的时候,按照tile对高斯进行索引,并更新其参数

3.2 3DGS的优化
- 优化的目的: 创建一组密集的3DGaussia以精确的表示场景
- 优化的参数:三维位置(
P
P
P),透明度(
α
\alpha
α),各项异性协方差(
∑
\sum
∑),球谐函数(
S
H
SH
SH)
注意:”参数优化“和"自适应控制高斯模型”这两个动作交替进行
参数优化
- 优化的过程需要能够创建集合体,并在错误的位置处销毁或者移动几何体。
- 参数优化使用SGD连续迭代完成,每一轮迭代都会渲染图像并将其与真实的训练图作比较(后面会简单说一下我认为这种方式会带来的缺点)
- α \alpha α限制透明度区间: ( 0 , 1 ) (0,1) (0,1),使用sigmoid实现
- ∑ \sum ∑使用指定的激活函数激活
- P P P使用指数衰减调度技术进行优化
- 损失函数:
L = ( 1 − λ ) L 1 + λ L D − S S I M L = (1-\lambda)L_1 + \lambda L_{D-SSIM} L=(1−λ)L1+λLD−SSIM
D-SSIM(结构相异性):
D − S S I M = 1 1 − S S I M ( x , y ) D-SSIM = \frac{1}{1-SSIM(x,y)} D−SSIM=1−SSIM(x,y)1
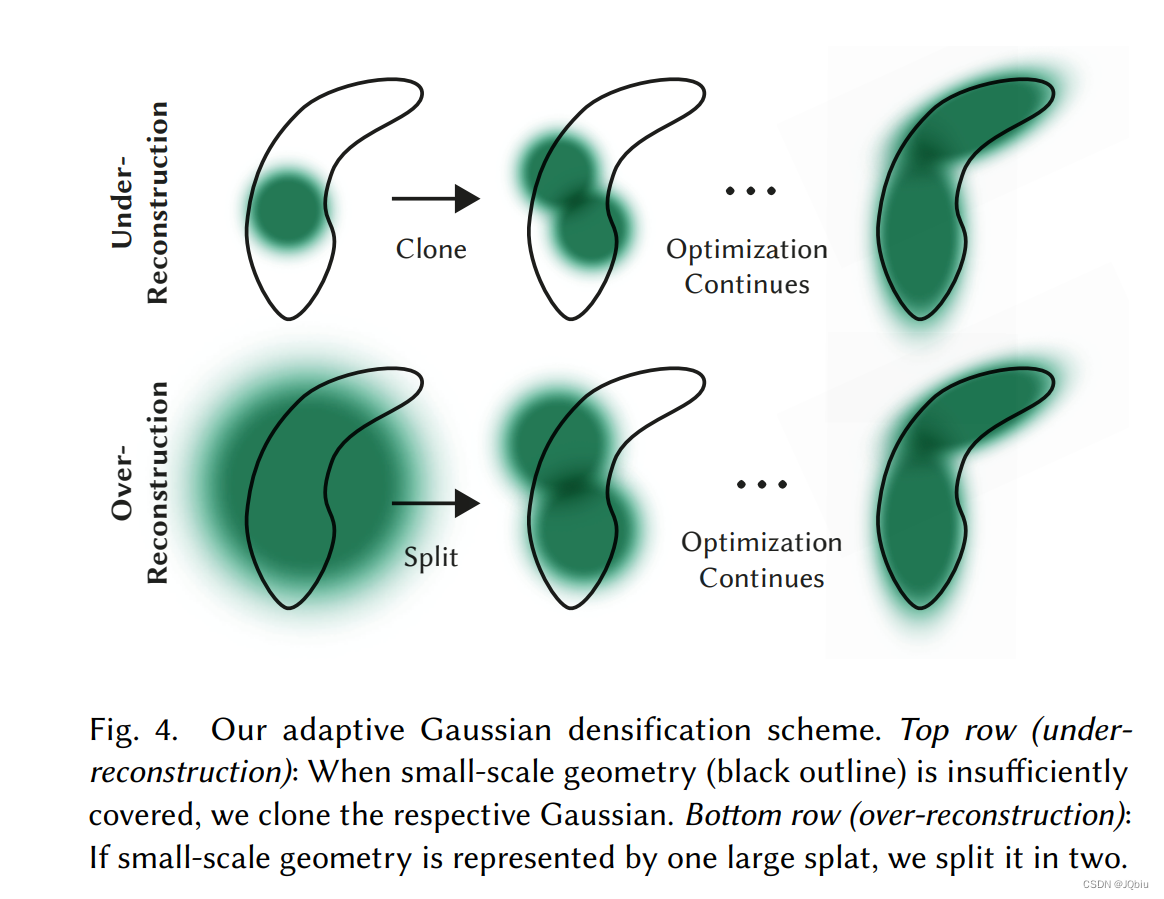
SSIM(x,y) 应该是指x和y的相似度 - 自适应控制:
主要是对3dGS的数量进行控制,达到质量和数量都在一个比较能够接受的范围内。可以分为两种:
a. under-reconstruction(欠重建):复制3dGS
b. over-reconstruction(过重建): 删除3dGS
大概就是为了避免Gaussia密度不合理的增加(3000次iter后,就设置透明度为0,每100次迭代就删掉透明的Gaussia分布,以限制Gaussia的总数量)
3.3 不足
到这里3dGaussia splatting的内容就接近尾声了,最后来讨论一下缺点吧。3D GS的效果确实可以,速度也很快,但本质上来说,3DGS不是建立了一个精准的真实3D模型,而是通过渲染结合3DGS所得到的分布,通过相机内参算一个很好看的2D图像。真实的3D物体的建模可能还需要继续探索。
就说到这,有什么理解不对的地方,大家指正啊,一起讨论,向各位学习!
四. 引用和参考:
Note: 本文没有参考论文原文,全部基于博客,主要是因为希望可以快速入门,入门之后查看论文原文可能才会产生自己的理解叭!
https://blog.csdn.net/weixin_48311163/article/details/119888018
https://zhuanlan.zhihu.com/p/595117334
https://zhuanlan.zhihu.com/p/450540827
https://zhuanlan.zhihu.com/p/449289345
https://zhuanlan.zhihu.com/p/597579341
https://www.bilibili.com/video/BV1dC4y1c7R8/?share_source=copy_web
https://zhuanlan.zhihu.com/p/113662566
https://blog.csdn.net/AYGdexiaotianxin/article/details/107225053
https://blog.csdn.net/koukutou_mikiya/article/details/134834955
https://blog.csdn.net/qq_43742590/article/details/104109103
https://blog.csdn.net/koukutou_mikiya/article/details/134834955
https://blog.csdn.net/su_zy_/article/details/134226262

















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









