







向量数据库:AI时代的“新基建”
一、向量数据库的概念
向量数据库是一种专门存储和管理高维向量数据的数据库系统,其核心价值在于将非结构化数据(如文本、图像、音频)转化为向量形式,通常由AI模型(如BERT、ResNet)将文本、图像、音视频等非结构化数据**嵌入(Embedding)**生成,例如“苹果”可能被转换为[0.23, -0.45, 0.67, …]这样的高维向量,并通过高效的相似性检索实现语义级匹配。
常用的文本嵌入模型,在硅基流动中可以看到有如下这些嵌入模型:

与传统关系型数据库不同,向量数据库通过**近似最近邻搜索(ANN)**算法,在海量数据中快速找到语义最接近的结果,而非精确匹配。例如,用户输入“蓝色毛衣”时,向量数据库会通过余弦相似度计算,返回与查询向量最接近的商品向量,而非依赖关键词匹配。
二、向量数据库的核心用途
- 语义搜索
支持基于语义的模糊匹配,例如在问答系统中找到与问题意图最相关的答案。 - 推荐系统
通过用户行为向量与商品/内容向量的相似性,实现个性化推荐(如电商场景)。 - 多模态应用
统一处理文本、图像、音频等数据,支持以图搜图、以文搜图等场景。 - 实时分析
在金融欺诈检测、网络安全等领域,通过向量相似性快速识别异常模式。 - 知识图谱扩展
将知识图谱中的实体和关系向量化,提升推理效率。 - 图像/视频检索
以图搜图、内容版权检测(如Google Images)。 - 异常检测
识别与正常模式差异较大的向量(如金融风控)。 - 大模型增强
为LLM提供外部知识库(RAG架构的核心组件)。
三、向量数据库的检索方式
- 近似最近邻搜索(ANN)
通过索引结构(如HNSW、LSH、IVF)将向量分组,缩小搜索范围。例如,HNSW算法通过分层图结构实现亚秒级检索。 - 多模态融合检索
支持文本、图像、音频的联合检索。例如,用户上传一张图片,系统可同时检索相似图片和描述文本。 - 上下文增强检索
结合元数据过滤(如时间、类别)和语义匹配,提升RAG系统生成答案的准确性。
四、检索算法示例:余弦相似度
假设我们有两个文本向量:
text1 = "猫喜欢吃鱼" → 向量 [0.2, 0.7, 0.1]
text2 = "狗喜欢啃骨头" → 向量 [0.1, 0.3, 0.8]
通过余弦相似度计算:
cosine_similarity = (text1 · text2) / (||text1|| × ||text2||)
= (0.2×0.1 + 0.7×0.3 + 0.1×0.8) / (1.0 × 1.0)
= 0.39
若相似度阈值设为0.5,则认为两者不相关。
五、主流向量数据库厂商及优缺点
| 厂商 | 优点 | 缺点 |
|---|---|---|
| Milvus/Zilliz | 分布式架构,支持百亿级向量秒级检索,生态完善 | 运维复杂,需专业团队支持 |
| Chroma | 开源免费,LangChain深度集成,适合快速原型开发 | 企业级功能有限,性能略逊于Milvus |
| Pinecone | 全托管云服务,毫秒级延迟,开箱即用 | 依赖云厂商,成本较高 |
| FAISS | Meta开源,GPU加速,支持十亿级向量 | 需自行管理数据存储,不支持实时更新 |
| Weaviate | 支持混合搜索(向量+结构化数据),集成GPT生成式搜索 | 处理PB级数据时性能下降明显 |
六、基于LangChain4j的向量数据库使用示例
以下代码演示如何用LangChain4j对接内存向量数据库,实现文本向量化与检索:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.35.0</version>
</dependency>
代码中使用了硅基流动的接口,替换掉其中的key即可,可以注册硅基流动账号体验。
注册硅基流动账号
-
访问 SiliconFlow官网 https://cloud.siliconflow.cn/i/FrfQv8wY,输入手机号注册并登录,新用户可免费获得 2000万Token额度 邀请码:FrfQv8wY。
首页模型广场有大量模型可供选择,可以根据需要选择。
-
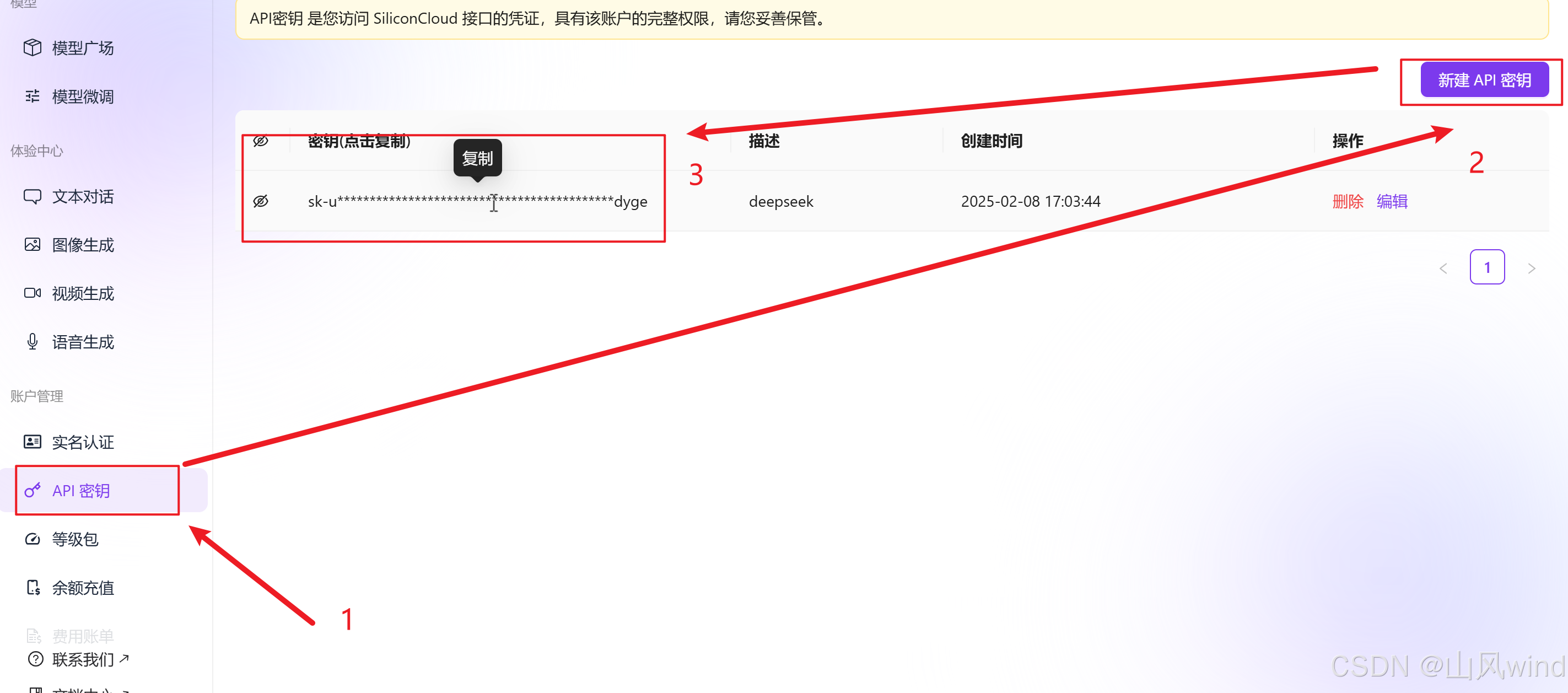
在控制台生成 API密钥(路径:左侧菜单栏 → API密钥 → 新建并复制密钥)。
package com.wind;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
/**
* @author wind
* @version 1.0
* @description: 向量检索示例
* @date 2025/3/18 18:55
*/
public class vector {
public static void main(String[] args) {
// 创建向量模型,使用 BAAI/bge-m3 模型
// 配置 API 密钥和基础 URL
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.modelName("BAAI/bge-m3")
.apiKey("sk-xxxxxxxxx")
.baseUrl("https://api.siliconflow.cn/v1")
.build();
// 将文本"水果是西瓜"转换为向量表示
Response<Embedding> embedded = embeddingModel.embed("水果是西瓜");
// 创建内存向量存储,用于存储向量和对应的文本
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// 将向量和对应的文本存入向量存储
embeddingStore.add(embedded.content(), TextSegment.from("水果是西瓜"));
// 设置查询文本
String query = "水果";
// 将查询文本转换为向量
Response<Embedding> embedding = embeddingModel.embed(query);
// 执行向量相似度搜索
// minScore 设置为 0.7,表示只返回相似度大于 0.7 的结果
EmbeddingSearchResult<TextSegment> searched = embeddingStore.search(EmbeddingSearchRequest.builder()
.queryEmbedding(embedding.content())
.minScore(0.7)
.build());
// 打印搜索结果中最相似的文本
System.out.println("打印搜索结果中最相似的文本");
System.out.println(searched.matches().get(0).embedded().text() +" 相似分数:" +
searched.matches().get(0).score());
}
}
输出结果:
打印搜索结果中最相似的文本
水果是西瓜 相似分数:0.8920091441014397
总结
向量数据库作为AI时代的“新基建”,正在重塑推荐系统、RAG、多模态应用等场景。选择时需权衡性能、成本与生态,而LangChain4j等工具链进一步降低了开发门槛,加速了向量数据库与生成式AI的融合。未来,随着多模态数据规模的爆发式增长,向量数据库的实时性、扩展性将成为竞争关键。



















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











